
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- type hints
- scatter
- Python
- dtype
- pivot table
- namedtuple
- 최대가능도 추정법
- Comparisons
- BOXPLOT
- 표집분포
- seaborn
- unstack
- subplot
- groupby
- 정규분포 MLE
- Operation function
- python 문법
- 카테고리분포 MLE
- linalg
- Numpy data I/O
- Array operations
- Python 특징
- VSCode
- Python 유래
- Numpy
- 딥러닝
- ndarray
- 부스트캠프 AI테크
- 가능도
- boolean & fancy index
- Today
- Total
또르르's 개발 Story
[Stage 2 - 이론] BERT 본문
1️⃣ BERT
BERT 모델은 Original Input을 넣어서 "Input과 똑같은 Output"을 나오게 하는 방식을 사용했습니다.
이때, Original Input을 masking 기법을 통해 가려줌으로써 "Input과 똑같은 Output"이 최대한 나오게 설계했습니다.

2️⃣ BERT 구조도
- BERT는 Transformer 12개로 구성되어있습니다.
- [CLS]는 Sentence 1과 Sentence 2가 next Sentence관계인지를 분류하게 됩니다.

1) 데이터 tokenizing
- WordPiece tokenizing
- He likes playing -> He likes play ##ing
- 입력 문장을 tokenizing하고,그 token들로 ‘tokensequence’를 만들어 학습에 사용
- 2개의 tokensequence가 학습에 사용

2) Masked Language Model
BERT는 [CLS], [SEP]와 같은 special token을 제외하고, 15% 확률로 랜덤으로 token을 선택하게 됩니다.
이 중 80%는 선택된 token을 Masking하고,
10%는 선택된 token을 다른 token으로 대체하며,
나머지 10%는 선택된 token을 바꾸지 않습니다.

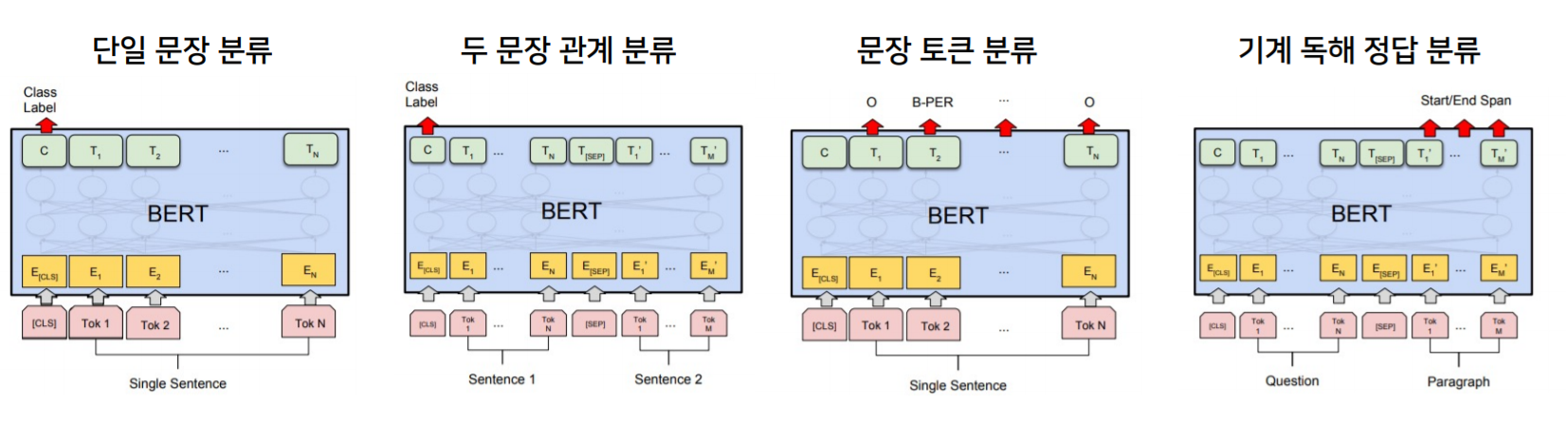
3️⃣ GLUE dataset
GLUE dataset에는 다양한 task들이 존재하고, 이러한 dataset을 가지고 NLP 언어모델의 성능 지표 역할을 할 수 있습니다.

BERT는 다양한 GLUE Dataset에서 fine-tuning을 통해 실험이 가능합니다.
- 단일 문장 분류 : 문장이 어떤 클래스에 속하는가
- 두 문장 관계 분류 : 두 문장의 Next sentence, 가설 관계, 유사도 등을 예측
- 문장 토큰 분류 : 각 token들에 분류기를 부착해 토큰 각각이 어떤 label을 가지게 되는지
- 기계 독해 정답 분류 : 지문과 질문이 주어지면, 질문 내용을 지문에서 찾아서 start/end point 출력
4️⃣ BERT 모델 응용
- 감정 분석
네이버 영화 리뷰 코퍼스 (https://github.com/e9t/nsmc)로 감성 분석 - 관계 추출
KAIST가 구축한 Silverdata사용 (1명의 전문가가 annotation) - 의미 비교
디지털 동반자 패러프레이징 질의 문장 데이터를 이용하여 질문-질문 데이터 생성 및 학습 - 개체명 분석
ETRI개체명 인식 데이터를 활용하여 학습 및 평가 진행 (정보통신단체표준 TTA.KO-10.0852) - 기계 독해
LG CNS가 공개한 한국어 QA데이터 셋,KorQuAD (https://korquad.github.io/)
1) 한국어 tokenizing에 따른 성능 비교
가장 좋은 성능은 형태소 분류기 통과 후, WordPiece 사용하는 방법입니다.
"이순신"과 같은 명사에서 "이"-> 성을 나타내는 부분들을 더 잘 검출할 수 있기 때문입니다.

'[P Stage 2] KLUE > 이론' 카테고리의 다른 글
| [Stage 2 - 이론] BERT를 활용한 단일 문장 분류 (0) | 2021.04.19 |
|---|---|
| [Stage 2 - 이론] 한국어 BERT 모델 학습하기 (0) | 2021.04.18 |
| [Stage 2 - 이론] 의존 구문 분석 (0) | 2021.04.16 |
| [Stage 2 - 이론] 한국어 토큰화 (0) | 2021.04.13 |
| [Stage 2 - 이론] 자연어 단어 임베딩 (0) | 2021.04.12 |

