
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- namedtuple
- Python 특징
- ndarray
- BOXPLOT
- Numpy
- dtype
- linalg
- groupby
- 표집분포
- 최대가능도 추정법
- Python
- Comparisons
- python 문법
- Numpy data I/O
- subplot
- type hints
- 부스트캠프 AI테크
- unstack
- seaborn
- scatter
- 정규분포 MLE
- boolean & fancy index
- 딥러닝
- Array operations
- 가능도
- Operation function
- pivot table
- 카테고리분포 MLE
- VSCode
- Python 유래
- Today
- Total
또르르's 개발 Story
[17-2] 번역 모델 전처리 using PyTorch 본문
영어-한글 번역 모델을 학습하기 위해 영어-한글 번역 데이터셋을 전처리하는 방법은 다양합니다.
번역 모델은 번역하고자 하는 문장(Source)을 입력으로 받고, 번역 결과(Target)을 출력합니다.
1️⃣ 설정
필요한 모듈을 import 합니다.
from typing import List, Dict, Tuple, Sequence, Any
from collections import Counter, defaultdict, OrderedDict
from itertools import chain
import random
random.seed(1234)
import torchClass Language는 word를 index로 변환해주는 word2idx와 index를 word로 변환시켜주는 idx2word를 가지고 있습니다.
class NMTDataset는 source와 target을 받아 preprocess를 수행합니다.
class Language(Sequence[List[str]]):
PAD_TOKEN = '<PAD>'
PAD_TOKEN_IDX = 0
UNK_TOKEN = '<UNK>'
UNK_TOKEN_IDX = 1
SOS_TOKEN = '<SOS>'
SOS_TOKEN_IDX = 2
EOS_TOKEN = '<EOS>'
EOS_TOKEN_IDX = 3
def __init__(self, sentences: List[str]) -> None:
self._sentences: List[List[str]] = [sentence.split() for sentence in sentences]
self.word2idx: Dict[str, int] = None
self.idx2word: List[str] = None
def build_vocab(self, min_freq: int=1) -> None:
SPECIAL_TOKENS: List[str] = [Language.PAD_TOKEN, Language.UNK_TOKEN, Language.SOS_TOKEN, Language.EOS_TOKEN]
self.idx2word = SPECIAL_TOKENS + [word for word, count in Counter(chain(*self._sentences)).items() if count >= min_freq]
self.word2idx = {word: idx for idx, word in enumerate(self.idx2word)}
def set_vocab(self, word2idx: Dict[str, int], idx2word: List[str]) -> None:
self.word2idx = word2idx
self.idx2word = idx2word
def __getitem__(self, index: int) -> List[str]:
return self._sentences[index]
def __len__(self) -> int:
return len(self._sentences)
class NMTDataset(Sequence[Tuple[List[int], List[int]]]):
def __init__(self, src: Language, tgt: Language, max_len: int=30) -> None:
self._src = src
self._tgt = tgt
self._max_len = max_len
def __getitem__(self, index: int) -> Tuple[List[str], List[str]]:
return preprocess(self._src[index], self._tgt[index], self._src.word2idx, self._tgt.word2idx, self._max_len)
def __len__(self) -> int:
return len(self._src)
2️⃣ Preprocessor
주어진 데이터셋은 Source, Target 각각 하나의 문장으로 이루어져 있고 모델에 해당 정보를 전달하기 위해서는 하나의 문장을 여러 단어로 분리하고 각각의 단어를 index로 바꿔줄 수 있는 word2idx dictionary가 필요합니다.
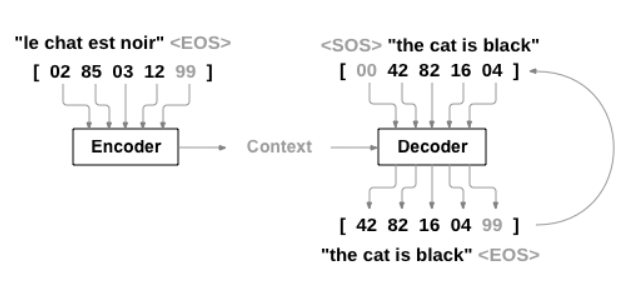
주어진 문장쌍(Source, Target)을 단어 index 단위로 바꾸어주는 preprocess 함수입니다.
(번역 모델에서 Target 문장에는 sos(start of sentence), eos(end of sentence) token이 추가되고 각각은 문장의 시작과 끝을 알려주는 token으로 사용됩니다.)
def preprocess(raw_src_sentence: List[str], raw_tgt_sentence: List[str], src_word2idx: Dict[str, int],
tgt_word2idx: Dict[str, int], max_len: int ) -> Tuple[List[int], List[int]]:
UNK = Language.UNK_TOKEN_IDX
SOS = Language.SOS_TOKEN_IDX
EOS = Language.EOS_TOKEN_IDX
src_sentence = []
tgt_sentence = []
for word in raw_src_sentence:
if word in src_word2idx.keys(): # src dictionary에 현재의 word가 있는 경우
src_sentence.append(src_word2idx[word])
else:
src_sentence.append(1) # src dictionary에 현재의 word가 없는 경우
for word in raw_tgt_sentence:
if word in tgt_word2idx.keys(): # tgt dictionary에 현재의 word가 있는 경우
tgt_sentence.append(tgt_word2idx[word])
else:
tgt_sentence.append(1) # tgt dictionary에 현재의 word가 없는 경우
src_sentence = src_sentence[:max_len] # max_len까지의 sequence만
tgt_sentence = [2] + tgt_sentence[:max_len-2] + [3] # SOS, EOS token을 추가하고 max_len까지의 sequence만
return src_sentence, tgt_sentence
3️⃣ Bucketing
Bucketing은 주어진 문장의 길이에 따라 데이터를 그룹화하여 padding을 적용하는 기법입니다. 이 기법은 모델의 학습 시간을 단축하기 위해 고안되었습니다.
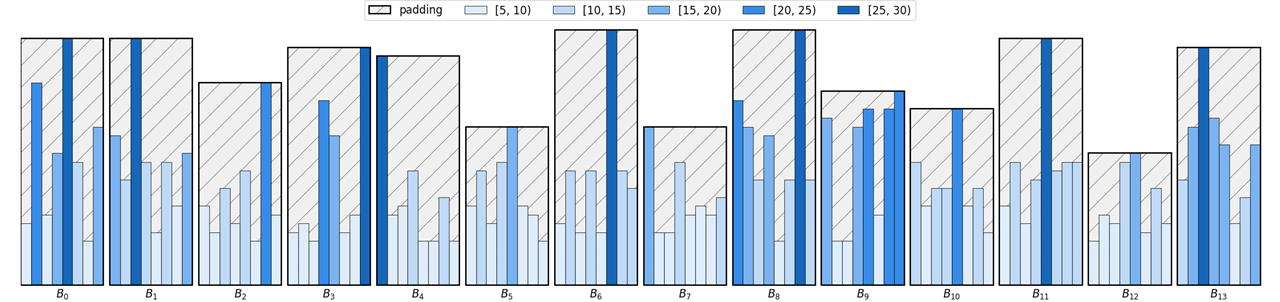
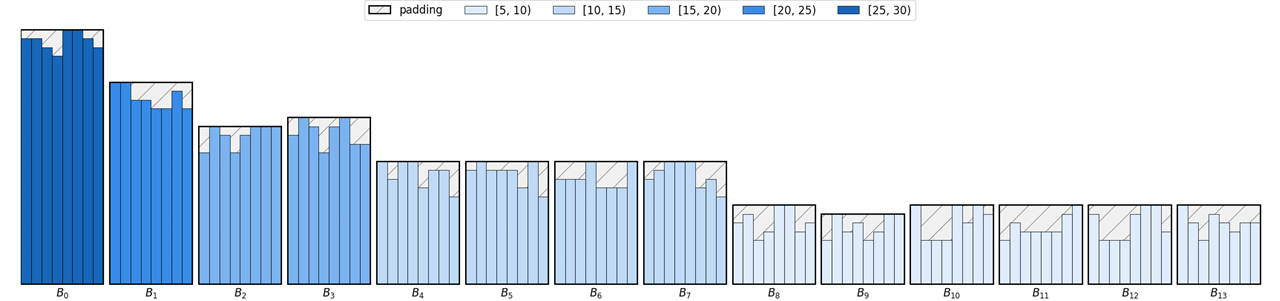
def bucketed_batch_indices(sentence_length: List[Tuple[int, int]], batch_size: int,
max_pad_len: int) -> List[List[int]]:
batch_map = defaultdict(list)
batch_indices_list = []
src_len_min = min(sentence_length, key=lambda x:x[0])[0] # 첫번째 인덱스인 src의 min length
tgt_len_min = min(sentence_length, key=lambda x:x[1])[1] # 두번째 인덱스인 tgt의 min length
# max_pad_len 크기로 비슷한 차이들의 집합으로 묶어주는 역할
for idx, (src_len, tgt_len) in enumerate(sentence_length):
src = (src_len - src_len_min + 1) // (max_pad_len) # max_pad_len 단위로 묶어주기 위한 몫
tgt = (tgt_len - tgt_len_min + 1) // (max_pad_len) # max_pad_len 단위로 묶어주기 위한 몫
batch_map[(src, tgt)].append(idx)
for key, value in batch_map.items():
batch_indices_list += [value[i: i+batch_size] for i in range(0, len(value), batch_size)]
# Don't forget shuffling batches because length of each batch could be biased
random.shuffle(batch_indices_list)
return batch_indices_list
4️⃣ Collate Function
Collate function은 주어진 데이터셋을 원하는 형태의 batch로 가공하기 위해 사용되는 함수입니다.
def collate_fn(batched_samples: List[Tuple[List[int], List[int]]]) -> Tuple[torch.Tensor, torch.Tensor]:
PAD = Language.PAD_TOKEN_IDX
batch_size = len(batched_samples)
batched_samples = sorted(batched_samples, key=lambda x:x[0], reverse=True) # 0번째 요소의 길이를 기준으로 내림차순 정렬
src_sentences = []
tgt_sentences = []
for src_sentence, tgt_sentence in batched_samples:
src_sentences.append(torch.tensor(src_sentence))
tgt_sentences.append(torch.tensor(tgt_sentence)) # tensor로 변경
# batch size에 맞게 zero로 채움
# tensor([[1, 2, 3, 4],
# [1, 2, 3, 0],
# [1, 2, 0, 0],
# [1, 0, 0, 0]])
# tensor([[1, 0, 0, 0],
# [1, 2, 0, 0],
# [1, 2, 3, 0],
# [1, 2, 3, 4]])
src_sentences = torch.nn.utils.rnn.pad_sequence(src_sentences, batch_first=True) # batch x longest seuqence 순으로 정렬 (링크 참고)
tgt_sentences = torch.nn.utils.rnn.pad_sequence(tgt_sentences, batch_first=True) # batch x longest seuqence 순으로 정렬 (링크 참고)
# 링크: https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_sequence.html
return src_sentences, tgt_sentences
5️⃣ 번역 모델 전처리 Test Case 확인
위에서 만든 preprocess, collate_fn, bucketing 함수들을 사용해서 번역 모델 전처리를 수행합니다.
def test_dataloader():
print("======Dataloader Test======")
english = Language(['고기를 잡으러 바다로 갈까나', '고기를 잡으러 강으로 갈까나', '이 병에 가득히 넣어가지고요'])
korean = Language(['Shall we go to the sea to catch fish ?', 'Shall we go to the river to catch fish', 'Put it in this bottle'])
english.build_vocab() # word2idx, idx2word dict 생성
korean.build_vocab()
dataset = NMTDataset(src=english, tgt=korean) # preprocess 수행
batch_size = 4
max_pad_len = 5
sentence_length = list(map(lambda pair: (len(pair[0]), len(pair[1])), dataset))
bucketed_batch_indices(sentence_length, batch_size=batch_size, max_pad_len=max_pad_len) # bucket batch indices 수행
dataloader = torch.utils.data.dataloader.DataLoader(dataset, collate_fn=collate_fn, num_workers=2, \
batch_sampler=bucketed_batch_indices(sentence_length, batch_size=batch_size, max_pad_len=max_pad_len)) # 이 값을 dataLoader에 넣기
src_sentences, tgt_sentences = next(iter(dataloader)) # iter로 [0,1]의 Tensor가 수행되고, [2]가 그 다음 수행 (bucket에서 [[0,1][2]]로 나눠짐)
print("Tensor for Source Sentences: \n", src_sentences)
print("Tensor for Target Sentences: \n", tgt_sentences)>>> test_dataloader()
# iter로 [0,1]의 Tensor가 수행되고, [2]가 그 다음 수행 (bucket에서 [[0,1][2]]로 나눠짐)
# [2]
======Dataloader Test======
Tensor for Source Sentences:
tensor([[ 9, 10, 11, 12]])
Tensor for Target Sentences:
tensor([[ 2, 14, 15, 16, 17, 18, 3]])
# [0,1]
======Dataloader Test======
Tensor for Source Sentences:
tensor([[4, 5, 8, 7],
[4, 5, 6, 7]])
Tensor for Target Sentences:
tensor([[ 2, 4, 5, 6, 7, 8, 13, 7, 10, 11, 3, 0],
[ 2, 4, 5, 6, 7, 8, 9, 7, 10, 11, 12, 3]])'부스트캠프 AI 테크 U stage > 실습' 카테고리의 다른 글
| [18-3] fairseq 사용하기 (0) | 2021.02.18 |
|---|---|
| [18-2] Seq2Seq with Attention using PyTorch (0) | 2021.02.18 |
| [17-1] LSTM / GRU with PyTorch (0) | 2021.02.16 |
| [16-3] Spacy를 이용한 영어 전처리 (0) | 2021.02.16 |
| [16-2] Word2Vec Using Konlpy (0) | 2021.02.16 |
