
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- namedtuple
- scatter
- 정규분포 MLE
- Python 특징
- 딥러닝
- type hints
- Operation function
- seaborn
- Array operations
- python 문법
- 최대가능도 추정법
- Comparisons
- groupby
- subplot
- 카테고리분포 MLE
- BOXPLOT
- ndarray
- Python
- Numpy data I/O
- unstack
- 부스트캠프 AI테크
- dtype
- 가능도
- VSCode
- boolean & fancy index
- pivot table
- Numpy
- 표집분포
- Python 유래
- linalg
- Today
- Total
또르르's 개발 Story
[20] Self-Supervised Pre-Training Models 본문
현재(2021.02.19 기준) NLP는 Trnasformer 구조에서 layer를 많이 쌓아서 사용하는 구조로 점차 발전하고 있습니다.
하지만 Self-Attention model이 아직까지도 Greedy decoding에서 벗어나지 못하는 실정입니다.
Self-Supervised Pre-Training Models은 대용량의 데이터로 pre-trained를 수행하고, fine-tuning을 통해 범용적으로 사용할 수 있는 Model을 말합니다.
Self-Supervised Pre-Training Models로는 GPT-1, BERT가 있고,
Advanced Self-Supervised Pre-Training Models는 GPT-2, GPT-3, ALBERT, ELECTRA가 있습니다.
1️⃣ GPT-1
OpenAI에서 나온 모델, 최근에는 GPT-2, GPT-3까지 모델이 나왔습니다.
기본적으로 Special Token 개념을 사용해서 다양한 task들을 동시에 커버할 수 있는 통합된 모델입니다.
Text에 Posionial Embed를 수행한 후 Transformer block을 12개 쌓아서 만든 모델이며,
Text Prediction은 첫 단어부터 마지막 단어까지 순차적으로 예측합니다.

Task Classification은 Sentimentation analysis나 classification과 같은 task를 수행할 수 있습니다.
classification으로 label 된 데이터가 있다고 할 때, GPT-1의 Multi-task learning에서 학습할 수 있습니다.
아래와 같이 <Start> token과 Text를 넣고 마지막에 <Extract>이라는 Special Token을 넣어주게 되면 Transformer로 encoding을 한 후 <Extract token>을 거치면서 Classification을 수행하게 됩니다.
(마지막 out layer의 입력 token으로 넣어줌)

"어제 John이 결혼을 했다."와 "어제 최소한 한 명이 결혼을 했다"라는 문장에서
첫 번째 문장(Premise)이 참이면 두 번째 문장(Hypothesis)이 무조건 참이어야 하는 논리적인 내포 관계가 있는 경우
Premise와 Hypothesis를 하나의 Sequence로 만들되, 가운데에 Delimiter <Delim>이라는 특수문자를 넣어줍니다.
<Extract> Token은 마지막에 들어가 query문으로 사용되면서 주어진 정보들에서 정보를 추출합니다.

Similarity와 Multiple Choice도 이러한 방법으로 수행됩니다. (아래에서 더 자세히 설명하겠습니다.)

이러한 다양한 Task들이 존재하는데 각각의 Task마다 Transformer를 학습시킬 때,
이미 충분히 학습이 된 12 block Transformer의 구조에서는 learning rate를 작게 주어 변경사항이 없게 하고

새롭게 올린 Classification이나 Prediction layer에서 learning rate를 높게 주어 학습이 빠르게 진행되게 만듭니다.

Pre-trained 된 GPT-1 모델을 다양한 task에 fine-tuning 해봤을 때 기존의 각 task별로 존재하던 customize 된 모델들보다 GPT-1이 훨씬 높은 성능을 보였습니다.

2️⃣ BERT
BERT는 현재까지 널리 쓰이는 Pre-training language 모델입니다.
BERT의 기본적인 motivation은 Bi-directional Encoder (양방향 encoder)입니다.
즉, GPT-1의 경우는 단방향 encoder이기 때문에 앞에 있는 문장만 가지고 문맥을 파악했다면,
BERT의 경우에는 뒤의 문장까지 파악하여 중간에 빠진 단어나 모르는 단어를 예측해줍니다.

1) Masked Language Model (MLM)
BERT 모델은 Masked Language Model (MLM)을 사용하며, Bert의 Pre-training task를 수행할 때 사용됩니다.
중간에 mask를 씌어 어떤 단어인지 맞추게 하는 형태로 학습이 진행됩니다.

Mask를 씌우는 비율은 hyper parameter로 대략 15%로 설정합니다.

너무 많은 [MASK]를 씌우면 (비율을 높이면) BERT가 문장을 맞추지 못하는 상황이 일어나고,
너무 적은 [MASK]를 씌우면 학습의 효율이 떨어지게 됩니다.
하지만 15%를 모두 [MASK]로 치환할 때 몇 가지의 문제점이 존재합니다.
pre-train에서 15%가 [MASK]로 치환된 익숙해진 문자가 나올 것인데 이런 문제를 주제 분류 task, Bound stream task 등을 수행할 때는 더 이상 [MASK] token이 등장하지 않게 됩니다. 따라서 pre-train에 제공된 양상이나 패턴이 실제 bound stream main task를 수행할 때와의 양상과 패턴이 상이할 수 있어, 학습에 방해가 될 수 있습니다.
따라서 [MASK] 15%를 모두 [MASK]로 가리는 것이 아닌 일부분을 다른 형태로 변경하게 됩니다.

15% 중 80%는 [MASK]로 치환합니다.
15% 중 10%는 random word로 바꾸게 되는데 random word가 적용된 문장을 원래 문장으로 잘 복원해 줄 수 있는 형태로 문제의 난이도를 높여주는 것입니다.
15% 중 나머지 10%는 바꾸지 않고 사용합니다.
2) Next Sentence Prediction
Next Sentence Prediction은 문장 level의 prediction 기법입니다.
BERT에서는 한 문장이 끝날 때마다 <SEP> token을 통해 구별해줍니다.
<CLS> token은 GPT-1의 <Extract> token과 같이 정보 추출의 token이며, 문장의 가장 앞에 넣어줍니다.

따라서 문장 level에서는 2개의 문장이 연속해서 나와도 어색하지 않은 문장인지를 비교해줍니다.
IsNext(연속 가능), NotNext(연속 불가능)으로 비교합니다.
또한, BERT는 Sentence를 비교하면서 중간중간에 <MASK> token에 있는 값들을 예측을 수행하게 됩니다.
3) BERT Summary
- Model Architecture
BERT는 architecture에 따라 BERT BASE와 BERT LARGE로 나뉩니다.
(L은 layer 수, H는 encoding vector의 dimension, A는 Attention head의 개수)

- WordPiece embeddings (30,000 WordPiece)
BERT에서는 word단위의 Embedding vector를 사용하는 것이 아니라 word를 좀 더 잘게 쪼개서 subword 단위로 embedding 하는 방법을 사용했습니다. (WordPiece)
- Learned positional embedding
BERT에서는 Positional embedding 자체도 neural network 학습에 의해서 결정됩니다.
- Segment Embedding
아래 그림처럼 <SEP> token을 통해 문장을 분리하는데 B 문장의 첫 단어 "he"를 구분하는 원소가 필요합니다.
Position Embedding은 위치를 나타내는 vector이기 때문에 <SEP> token을 포함($E_{5}$)해서 그대로 사용하기 때문에 A 문장과 B 문장을 구분할 수 없습니다.
따라서 Segment Embedding을 추가해서 A문장과 B문장을 나눠줍니다.
Segment Embedding 문장 level에서의 position, index를 반영한 vector입니다.

4) BERT vs GPT-1
(1) Bi-directional Training
GPT-1의 경우 바로 다음 word sequence를 예측해야 할 때 특정한 timestep에서 다음 word 접근이 불가합니다.

BERT의 경우에는 [MASK]된 단어를 포함하여 모든 word의 접근 허용이 가능합니다.
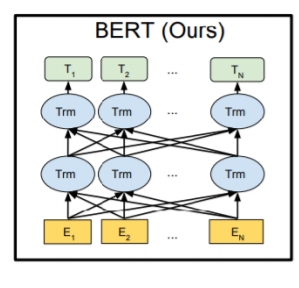
(2) Training-data size
GPT-1은 BookCorpus (800M words)를 trained 하고, BERT는 BookCorpus + Wikipedia (2500M words)를 trained 합니다.
(3) Training special tokens during training
BERT에서는 <SEP>, <CLS> token을 사용할 수 있고, 여러 문장이 주어졌을 때 segment embedding을 사용해 문장을 잘 구분할 수 있습니다.
(4) Batch Size
BERT – 128,000 words ; GPT – 32,000 words
큰 batch size를 사용하면 모델 성능이 좋아지고, 학습이 안정화됩니다.
(gradient descent를 할 때 한 번에 많은 데이터를 사용해서 업데이트하는 것이 학습이 안정화됩니다.)
(5) Task-specific fine-tuning
GPT는 fine-tuning의 learning rate가 5e-5로 고정되어 있지만, BERT는 fine-tuning의 learning rate 선택이 가능합니다.
5) Fine-tuning Process
Pre-training 한 Transformer 모델을 여러 가지 task에 사용할 수 있는 Fine-tuning process입니다.

(a) Sentence Pair Classification Tasks : 논리적으로 내포 관계, 모순 관계를 예측하는 task
<SEP>으로 문장을 구분해주고, <CLS> token은 BERT 수행 후 classification 수행할 때 사용됩니다.

(b) Single Senctence Classification Tasks

(c) Question Answering Tasks : 주어진 질문에 답변을 하는 task

(d) Single Sentence Tagging Tasks : 주어진 문장에서 문장 성분이나 품사가 무엇인지 예측하는 task

여러 task들을 한 곳에 모아놓은 dataset, benchmark set을 GLUE data라고 합니다.

6) MRC, Question Answering
MRC는 Machine Reading Comprehension의 약자로, 기계가 지문을 독해하고 그 지문에서 필요한 정보를 추출해 정답을 예측해내는 task입니다.

MRC의 대표 격인 SQuAD는 Standford 대학교에서 만든 Question and Answering dataset입니다. BERT에서는 SQuAD 1.1과 2.0을 사용합니다.
(a) SQuAD 1.1
SQuAD 1.1은 지문과 question이 주어지면, 컴퓨터가 지문을 읽고 question에 답(단어)을 맞추는 형태입니다.
BERT에서는 지문과 Question을 <SEP>를 통해 concat 해서 하나의 sequence로 만든 후, encoding을 진행합니다.
그러면 그 vector들이 정답에 해당할 법한 위치(정답은 특정한 word로 주어짐)를 예측하도록 수행하게 됩니다.

각 word별로 최종 encoding vector가 output으로 나왔을 때, 이를 공통된 output layer를 통해서 scalar 값을 뽑도록 합니다.
즉, encoding vector가 나온 후, 이 vector들을 fully connected layer $FC_{1}$를 통해 scalar값으로 변경해줍니다. scalar값을 각 word별로 얻은 후에는 여러 word들 중에 답에 해당하는 문구가 어느 단어에서 시작하는지 먼저 예측해줍니다. 만약 124개의 단어가 존재하면, 124개의 scalar값의 vector가 존재하며, 이 값들 중 "first" 단어에서 softmax의 높은 확률을 가질 수 있도록 loss를 통해 학습합니다.

또 Answering 단어가 끝나는 시점도 예측해야 하는데 이 word에 대한 또 다른 fully connected layer $FC_{2}$를 만들고 같은 방식으로 softmax를 통과해서 높은 확률의 end 위치를 설정해줍니다. 아래 그림에서는 "shock"입니다.

(b) SQuAD 2.0
SQuAD 2.0은 SQuAD 1.1에서 답을 찾을 수 없는 dataset도 포함되어 있습니다.
따라서 BERT의 fine-tuning으로 답이 있는지 없는지를 예측하는 task가 하나가 더 필요합니다. <CLS> token을 사용하여 binary classification을 수행해 "answer"와 "no answer"를 구분합니다.
만약, "answer" 답이 있다면 SQuAD 1.1을 수행한 방식대로 하면 됩니다.

(c) On SWAG
On-SWAG 같은 경우에는 주어진 문장이 있을 때, 다음에 나타날 법한 적절한 문장을 구하는 task입니다.
따라서 주어진 문장과 (i)를 concat 해서 BERT 통해 encoding 하고, 나오는 <CLS> token을 사용해서 encoding vector를 fully connected layer를 통해 scalar값을 추출합니다. 두 번째 (i)도 concat 해서 scalar값을 구해냅니다.
총 (i), (ii), (iii), (iv) 4개의 scalar값을 softmax의 입력으로 주고, 가장 어울릴만한 문장의 확률을 구해냅니다.

7) Ablation Study
BERT에서는 layer를 깊게 쌓고, 각 parameter를 늘려가는 형태로 학습을 진행하면 여러 task들의 성능이 끊임없이 좋아지는 것을 알 수 있습니다.

3️⃣ GPT-2
1) 특징
- GPT-1 보다 transformer block을 더 많이 쌓음
- GPT-2는 성능이 좋아져서 하나의 문단을 생성할 능력을 가짐

- GPT-2는 good quality의 글을 가지고 와서 trained를 했는데 good quality의 글의 기준은 3개 이상의 "좋아요"를 받은 글, 외부 링크로 reference 된 글 등 위주로 학습을 했습니다.
- GPT-2는 Byte pair Encoding (BPE)를 사용함
- GPT-2는 위의 layer로 갈수록 random initialization을 할 때 값을 더 작게 만듭니다.
(layer가 위로 갈수록 선형 변환에 사용되는 값들이 점점 더 0에 가까워지도록 => 위쪽의 layer가 하는 역할이 점점 더 줄어들 수 있도록)

- GPT-2는 Zero-shot이 가능합니다.
(Zero-shot : 어떤 task를 하라는 설명만 주어졌을 때 그 task에 대한 답변을 예측하는 것)


4️⃣ GPT-3
1) 특징
- GPT-2보다 사용한 model size와 paramter 숫자들을 훨씬 늘려줌 (175 billion parameters)

- 많은 data, 큰 batch size (96 Attention layers, Batch size of 3.2M)
- GPT-3은 One-shot과 Few-shot이 가능
one shot : zero-shot에서 예시 (example)를 주고 task를 수행
학습 데이터로써 번역을 위한 데이터를 단 한 쌍 (sea otter => loutre de mer)만 주었지만 GPT-3는 이 task, example, prompt를 텍스트의 일부로 사용해서 zero-shot보다 훨씬 좋은 성능을 보이게 됩니다.
few shot : 예시(example)를 여러 개 주고 task를 수행
one-shot보다 훨씬 좋은 성능을 낼 수 있습니다.

5️⃣ ALBERT (A Lite BERT)
ALBERT는 경량화된 BERT 모델입니다. 성능의 큰 하락 없이 (또는 더 좋은 성능을 내면서) 학습 시간을 빠르게 만들 수 있는 모델입니다.
ALBERT의 가장 큰 특징은 새로운 Sentence Order Prediction을 제안한 것입니다.
1) 경량화
(a) dimension 줄이기
Self-Attention 구조에서 embedding vector의 dimension $d_{model}$의 크기는 layer를 거듭할 때 계속 같은 크기를 사용하므로, 너무 작은 dimension 크기를 사용하게 되면 모든 정보를 담을 수가 없습니다. 대신 dimension이 크면 model 사이즈도 커지고 거기에 필요로 하는 연산량도 늘어나게 됩니다.

따라서 ALBERT에서는 embedding layer의 dimension을 줄이는 추가적인 기법을 제시했습니다.
BERT가 V x H dimension을 가지고 있다면, ALBERT를 V x E, E x H를 나눠서 계산합니다.
만약, BERT에서 500 x 100 vector가 있다면, ALBERT는 500 x 15, 15 x 100으로 표현되고,
500 x 100 = 50,000 > 500 x 15 + 15 x 100 = 9,000
메모리 공간이 훨씬 줄어들게 됩니다.

(b) Shared params
ALBERT에서는 서로 다른 Self-Attention block에서 존재하는 선형 변환 matrix $W^{Q}, W^{K}, W^{V}, W^{O}$ 들을 shared 되는 parameter로 구성합니다.
- Shared-FFN : feed-forwad network shared
- Shared-attention : $W^{Q}, W^{K}, W^{V}$ shared
- All-shared : 모두 shared
All-shared을 수행하게 되면 parameter 수는 가장 적게 들지만 성능의 하락폭이 그렇게 크지 않습니다.

2) Sentence Order Prediction
ALBERT에서는 BERT에 있는 Next Sentence Prediction 기능(다음 문장이 next sentence인지 prediction 하는 것)을 빼고,
두 문장이 정방향 order인지, 아니면 역방향 order인지를 예측하는 Sentence Order Prediction을 추가했습니다.
Negative samples(next sentence에 해당하지 않는 예제를 만들기 위해서 서로 다른 문서에서 추출된 독립적인 Samples)를 사용함으로써 두 개의 document 간의 내용이 겹치지 않게 됩니다. (상이한 단어들이 많이 나오게 됩니다.) 이렇게 되면 두 문장의 흐름과 같은 고차원적인 추론 과정을 통해 이 task을 풀어야 하는 것이 아닌, 겹치는 단어가 많은지 적은지와 같은 심플한 task가 풀리게 됩니다. 결국, 너무 쉬운 task를 per-trained 하게 되면 학습된 내용이 많이 없게 됩니다.
따라서 ALBERT의 Sentence Order Prediction은 (Negative Samples가 아닌) 인접 문장을 사용하되, 단어의 overlapping 측면에서는 정방향이나 역방향으로 순서에서 단어의 overlap의 차이가 없게 만들어 모델이 논리적인 추론에 집중하게 만듭니다.
아래서 보다시피 SOP를 사용하니 성능이 좋아진 것을 볼 수 있습니다.

6️⃣ ELECTRA
ELECTRA는 Efficiently Learning an Encoder that Classifies Token Replacements Accurately의 약자입니다.
ELECTRA는 GAN에서 착안해서 Generator와 Discriminator가 존재합니다.
Genreator는 masked language modeling을 수행하는 경우, 주어진 단어에서 일부 단어를 [MASK] 단어로 치환하고, 다시 예측 단어로 복원해냅니다.
이후, 예측 단어를 Discriminator에 넣어서 원래부터 있었던 단어(original)였는지, 아니면 새롭게 바뀐 단어(replcaed)인지 판단합니다.
Generator는 기존의 BERT 모델로 생각할 수 있고, Discriminator는 기존 Self-Attention block을 쌓은 구조인데 각 단어를 예측할 때 binary classification (original인지 replaced인지)을 해주는 모델입니다.

즉, Generator와 Discriminator가 적대적으로 싸우는 모델이며, GAN에서 가지고 온 모델입니다.
ELECTRA는 같은 연산량에 비해 BERT보다 더 좋은 성능을 보여줍니다.

'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [22] 페이지랭크(PageRank) (0) | 2021.02.23 |
|---|---|
| [21] 그래프(Graph) 개념 (0) | 2021.02.22 |
| [19] Transformer 이해하기 (2) (0) | 2021.02.18 |
| [18-1] Beam Search와 BLEU score (0) | 2021.02.17 |
| [18] Sequence to Sequence with Attention (0) | 2021.02.17 |



