
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- VSCode
- scatter
- 표집분포
- unstack
- seaborn
- subplot
- dtype
- linalg
- Python 특징
- Numpy
- 부스트캠프 AI테크
- Array operations
- Operation function
- Python
- 정규분포 MLE
- 카테고리분포 MLE
- Numpy data I/O
- python 문법
- 최대가능도 추정법
- boolean & fancy index
- ndarray
- namedtuple
- Comparisons
- type hints
- groupby
- 딥러닝
- Python 유래
- 가능도
- BOXPLOT
- pivot table
- Today
- Total
또르르's 개발 Story
[23-1] 추천 시스템 본문
추천 시스템은 사용자 각각이 구매할 만한 혹은 선호할 만한 상품/영화/영상을 추천합니다.
추천 시스템의 핵심은 사용자별 구매를 예측하거나 선호를 추정하는 것입니다.
그래프 관점에서 추천 시스템은
“미래의 간선을 예측하는 문제”
“누락된 간선의 가중치를 추정하는 문제”
로 해석할 수 있습니다.
1️⃣ 내용 기반 추천시스템
내용 기반(Content-based) 추천은 각 사용자가 구매/만족했던 상품과 유사한 것을 추천하는 방법입니다.
내용 기반 추천은 다음 네 가지 단계로 이루어집니다.

1) 사용자가 선호했던 상품들의 상품 프로필(Item Profile)을 수집하는 단계

어떤 상품의 상품 프로필이란 해당 상품의 특성을 나열한 벡터입니다.
영화의 경우 감독, 장르, 배우 등의 원-핫 인코딩이 상품 프로필이 될 수 있습니다.

2) 사용자 프로필(User Profile)을 구성하는 단계

사용자 프로필은 선호한 상품의 상품 프로필을 선호도를 사용하여 가중 평균하여 계산합니다. 즉, 사용자 프로필 역시 벡터입니다.
여기서 가중 평균은 각각의 벡터에 대해서 사용자가 선호하는 정도가 다를 수 있는데 그 선호하는 정도를 가중치로 하여 평균을 내는 방법을 뜻합니다. 가중평균 사용하여 사용자 프로필 구성합니다.

3) 사용자 프로필과 다른 상품들의 상품 프로필을 매칭하는 단계

매칭은 사용자의 프로필과 상품 프로필이 얼마나 유사한지를 살펴보고 선택하는 단계입니다.
이 단계에서는 사용자 프로필 벡터 $\vec {u}$와 상품 프로필 벡터 $\vec {v}$ 코사인 유사도 $\frac {\vec {u} \cdot \vec{v}} {||\vec{u}|| ||\vec{v}||}$를 계산합니다. 즉, 두 벡터의 사이각의 코사인 값을 계산합니다.

코사인 유사도가 높을수록, 해당 사용자가 과거 선호했던 상품들과 해당 상품이 유사함을 의미합니다.
선택하는 과정은 다음과 같습니다.
red는 [1, 0, 0, ...]으로 결정되어 있고, 나머지 상품은 [0, 0, 0, ...]과 같은 vector로 구성되어 있을 때,
사용자 프로필 [red=1, circle=0.5, triangle = 0.5, ....] 등에서 red가 가장 유사한 형태를 보여 아래 그림과 같이 red vector를 선택하게 됩니다.

4) 사용자에게 상품을 추천하는 단계
계산한 코사인 유사도가 높은 상품들을 추천합니다.

내용 기반 추천시스템은 다음 장점을 갖습니다.
- 다른 사용자의 구매 기록이 필요하지 않습니다.
- 독특한 취향의 사용자에게도 추천이 가능합니다.
- 새 상품에 대해서도 추천이 가능합니다.
- 추천의 이유를 제공할 수 있습니다.
예시: 당신은 로맨스 영화를 선호했기 때문에, 새로운 로맨스 영화를 추천
내용 기반 추천시스템은 다음 단점을 갖습니다.
- 상품에 대한 부가 정보가 없는 경우에는 사용할 수 없습니다.
(상품 프로필이라는 것 자체가 상품의 부가 정보를 이용한 것이기 때문에) - 구매 기록이 없는 사용자에게는 사용할 수 없습니다.
- 과적합(Overfitting)으로 지나치게 협소한 추천을 할 위험이 있습니다.
2️⃣ 협업 필터링 추천시스템
사용자-사용자 협업 필터링은 다음 세 단계로 이루어집니다.
- 추천의 대상 사용자를 𝑥라고 합시다.
- 우선 𝑥 와 유사한 취향의 사용자들을 찾습니다.
- 다음 단계로 유사한 취향의 사용자들이 선호한 상품을 찾습니다.
- 마지막으로 이 상품들을 𝑥 에게 추천합니다.

취향의 유사성은 상관 계수(Correlation Coefficient)를 통해 측정합니다.
- $r_{xy}$ : 사용자 𝑥의 상품 𝑠에 대한 평점
- $\bar {r_{x}}$ : 사용자 𝑥가 매긴 평균 평점
- $S_{xy}$ : 사용자 𝑥와 𝑦가 공동 구매한 상품들

만약, 동일한 영화 S에 대해서 $x$라는 사람이 높은 평점을 매기고, $y$라는 사람이 높은 평점을 매겼다면, 양의 상관관계를 갖게 되어 양수값을 가지게 됩니다.
반면, $x$가 높은 평점을 매기고, $y$가 낮은 평점을 매겼다면, 불일치가 발생하고 음의 상관관계가 발생하게 됩니다.
분자의 $(r_{xs} - \bar {r_x}), (r_{ys} - \bar {r_y})$들을 영화 S에 대해서 합치는 $\sum_{s \in S_{xy}}$를 수행합니다.
분모 $\sqrt{\sum_{s \in S_{xy}}(r_{xs} - \bar{r_x})^{2}}$ $\sqrt{\sum_{s \in S_{xy}}(r_{ys} - \bar{r_y})^{2}}$는 0과 1 사이로 정규화하는 목적으로 사용하게 됩니다.
즉, 일치가 많이 발생할수록 $sim(x,y)$ 값은 양수를 가지며, 불일치가 많이 발생할수록 $sim(x,y)$의 값은 음수를 가지게 됩니다.
예시로 아래와 같이 사용자(지수, 제니, 로제)와 영화 (반지의 제왕, 겨울왕국, 라푼젤, 해리포터, 미녀와 야수) 평점이 있다고 합시다. 여기서 나타난 숫자는 영화 평점을 나타내며, '?'는 평점을 매기지 않은 것을 나타냅니다.
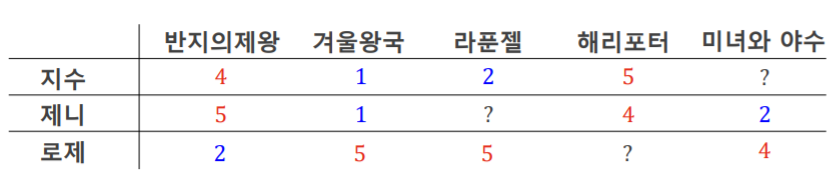
"지수"와 "제니"의 취향 유사도를 게산합니다.
(취향의 유사도에서 ? (평점을 매기지 않은 것)는 빼고 계산합니다.)

지수와 로제의 취향의 유사도는 0.88 입니다.

즉, 둘의 취향은 매우 유사합니다.
반면, "지수"와 "로제"의 취향 유사도는 조금 다릅니다.

지수와 로제의 취향의 유사도는 -0.94 입니다.

즉 둘의 취향은 매우 상이합니다.
따라서, "지수"의 취향을 추정할 때는 "제니"의 취향을 참고하게 됩니다.
예를 들면, 지수는 미녀와 야수를 좋아할 확률이 낮습니다. 지수와 제니의 취향은 유사하고, 제니는 미녀와 야수를 좋아하지 않았기 때문입니다.
이와 같이 취향의 유사도를 가중치로 사용한 평점의 가중 평균을 통해 평점을 추정합니다.
사용자 𝑥의 상품 𝑠에 대한 평점을 $r_{xs}$를 추정하는 경우를 생각합시다.
상관 계수를 이용하여 상품 𝑠를 구매한 사용자 중에 𝑥와 취향이 가장 유사한 𝑘명의 사용자 𝑁(𝑥; 𝑠)를 뽑습니다.
따라서 각각의 $y$가 𝑥랑 실제로 취향이 얼마나 유사한지 ($sim(x,y)$)를 가중치로 사용하여 상품 𝑠에 대해 내린 평점의 가중평균을 계산합니다.
평점 $r_{xs}$는 아래의 수식을 이용해 추정합니다.

이후, 추정한 평점이 가장 높은 상품들을 𝑥에게 추천합니다.
협업 필터링은 다음 장점을 가집니다.
- 상품에 대한 부가 정보가 없는 경우에도 사용할 수 있습니다.
협업 필터링은 다음 단점을 가집니다.
- 충분한 수의 평점 데이터가 누적되어야 효과적입니다.
- 새 상품, 새로운 사용자에 대한 추천이 불가능합니다.
- 독특한 취향의 사용자에게 추천이 어렵습니다.
3️⃣ 추천 시스템의 평가
1) 데이터 분리
다음과 같은 score 데이터가 있습니다.

이 데이터를 훈련(Training) 데이터와 평가(Test) 데이터로 분리합니다.

평가 데이터는 주어지지 않았다고 가정합시다.

훈련 데이터를 이용해서 가리워진 평가 데이터의 평점을 추정합니다.

추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정합니다.

2) 평가 지표
추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정합니다.
오차를 측정하는 지표로는 평균 제곱 오차(Mean Squared Error, MSE)가 많이 사용됩니다.
평가 데이터 내의 평점들을 집합을 𝑇라고 합시다.
평균 제곱 오차는 아래 수식으로 계산합니다.

평균 제곱근 오차(Root Mean Squared Error, RMSE)도 많이 사용됩니다.

'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [24-1] 넷플릭스 추천시스템 (0) | 2021.02.26 |
|---|---|
| [24] 정점 임베딩 (Node Embedding) (0) | 2021.02.25 |
| [23] 군집 구조 (0) | 2021.02.24 |
| [22-1] 그래프 전파 모형 (0) | 2021.02.23 |
| [22] 페이지랭크(PageRank) (0) | 2021.02.23 |



