
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python 특징
- 최대가능도 추정법
- scatter
- 표집분포
- Comparisons
- groupby
- type hints
- unstack
- 부스트캠프 AI테크
- linalg
- Python
- VSCode
- 카테고리분포 MLE
- Numpy data I/O
- Numpy
- 딥러닝
- namedtuple
- 정규분포 MLE
- dtype
- Python 유래
- BOXPLOT
- Operation function
- 가능도
- ndarray
- boolean & fancy index
- python 문법
- Array operations
- pivot table
- subplot
- seaborn
- Today
- Total
또르르's 개발 Story
[35] Multi-modal: Captioning and speaking 본문
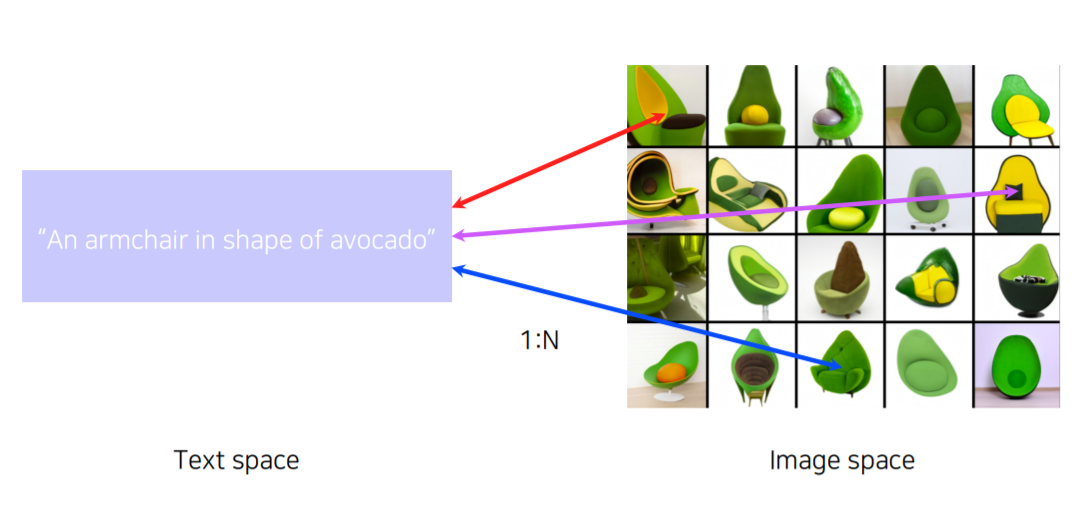
Multi-modal learning은 다양한 데이터 type (Vision, Audio 등)을 사용해서 학습하는 것을 의미합니다.
Mutli-modal learning의 어려운 점은 다음과 같습니다.
(1) 데이터들이 서로 다른 표현방법을 가지고 있기 때문에 학습이 쉽지 않습니다.

(2) 서로 다른 데이터들의 양이 unbalance 하고 각각의 feature space도 unbalance 합니다.
(3) 모델을 사용해서 학습을 할 때 여러 modality를 사용하게 될 경우에 여러 modality를 fair 하게 참조하지 못하고 bias 되는 경향이 있습니다.
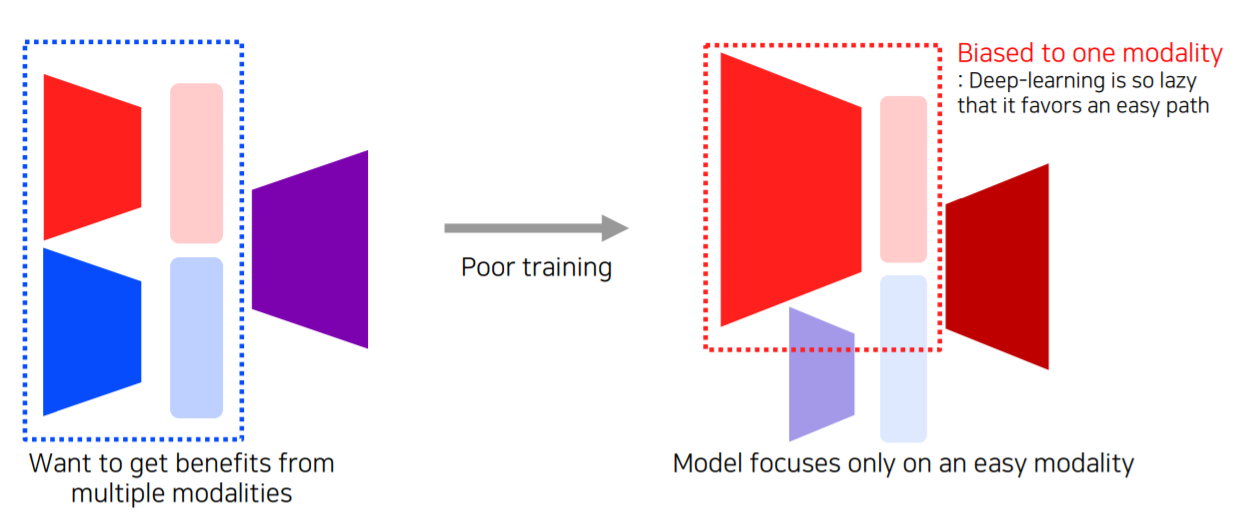
따라서 Multi-modal learning 이용하는 데에는 일정한 pattern이 있습니다.
- Matching : 하나의 데이터 type의 data(빨강)와 또 다른 데이터 type의 data(파랑)를 공통된 space(보라)로 보내서 서로 matching 시키는 구조
- Translating : 하나의 modality data(빨강)를 다른 modality data(파랑)으로 translate 해주는 구조
- Referencing : 하나의 modality data(빨강)에서 똑같은 modality data(빨강)로 출력하고 싶은데 다른 modality data(파랑)를 참조하는 구조

1️⃣ Multi-modal tasks (1) - Visual data & Text
1) Joint embedding (Matching)
1-1) Application - image tagging
주어진 image를 가지고 tag를 생성할 수 있고, tag를 사용해 image를 찾을 수 있습니다.

Image tagging은 pre-trained 된 unimodal model (각각의 model)들을 합쳐줍니다.
text를 하나의 feature vector 형태로 표현을 해줍니다. image data 또한 하나의 feature vector 형태로 표현해줍니다.
이때 두 개의 feature vector의 dimension은 같아야 합니다.
이후, 두 개의 feature vector가 호환성이 있도록 Joint embedding을 해줍니다.

Joint embedding space가 학습하기 위해서 text와 images를 같은 embedding space에 mapping 해줍니다. 그리고 embedding 간의 distance를 줄이는 방향으로 학습을 해줍니다.
이때, non-matching 관계일 경우 text와 images의 distance를 늘려줍니다.
이렇게 distance를 기반으로 해서 학습하는 방법을 Metric learning이라고 합니다.

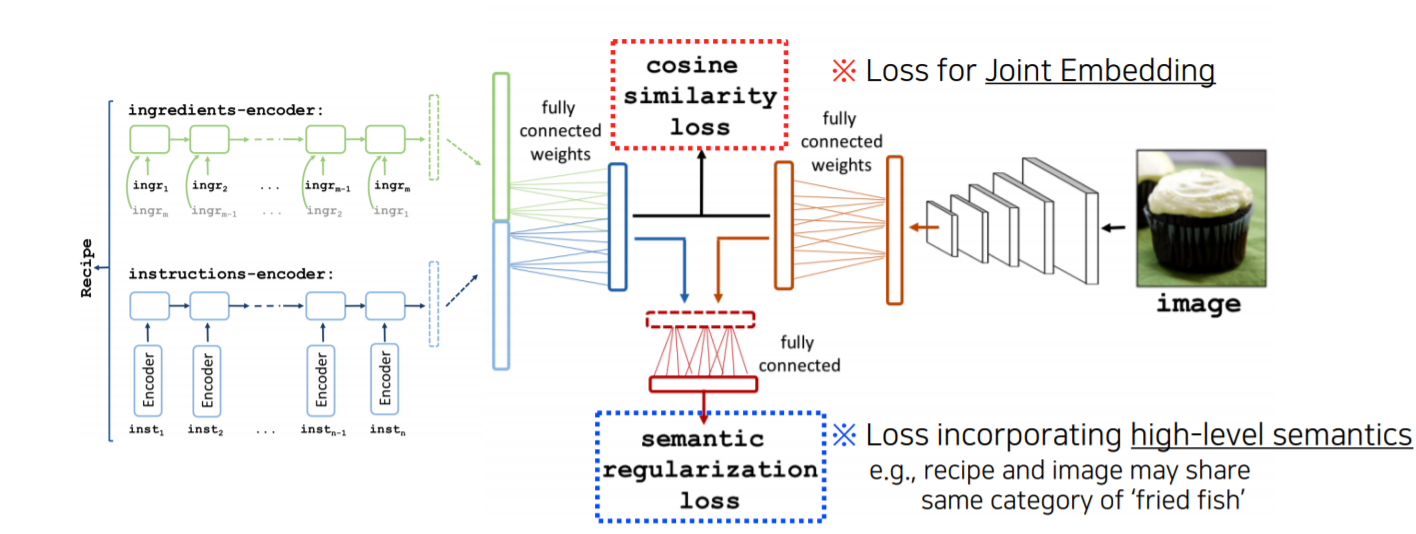
1-2) Application - Image & food recipe retrieval
Image를 넣어줬을 때 그 image에 따른 recipe를 알려주고, recipe를 넣어줬을 때 그에 따른 image를 보여줍니다.

Recipe는 순서가 있는 text이기 때문에 재료(ingredients)들이 어떤 순서로 추가가 되느냐를 RNN 계열의 network를 통해서 하나의 fixed vector를 출력합니다. insturction도 마찬가지입니다.
Ingredients vector와 instruction vector 두 개를 concatenation 해서 하나의 vector로 만들어줍니다. 이 vector는 text를 대표하는 vector가 됩니다.
Image는 CNN backbone network를 이용해서 하나의 feature vector로 만들어주고 text와 똑같은 dimension의 vector로 만들어줍니다.
그다음에 cosine similarity loss를 사용해서 text와 image가 연관이 되었다면 loss를 높게, 연관이 되어있지 않다면 loss를 낮게 줍니다.
두 번째 loss는 semantic regularization loss로써 cosine similarity loss로 해결이 안 되는 regularization 부분들을 해결할 수 있습니다. 전체 정보 중에서 일부의 정보만이라도 중요하게 catch 했으면 좋겠다는 값을 넣어줍니다.
2) Translation
2-1) Application - image captioning
Image가 주어지면은 그 image를 잘 설명하는 text description을 생성해내는 방법입니다.

Image translation에서는 Image는 CNN을 사용하고, text에는 RNN 구조를 사용하게 됩니다. 이러한 방법을 "Show and tell"이라고 합니다.
- Encoder : Image가 input으로 들어오면 fixed dimension vector로 바꿔주기 위해 ImageNet에서 pre-trained 된
- Decoder : LSTM에 넣어서 text를 출력합니다.

"Show, attend and tell"은 "Show and tell"에서 Image의 어떤 부분에 attention을 해야 하는지 추가해서 확장시킨 방법입니다.
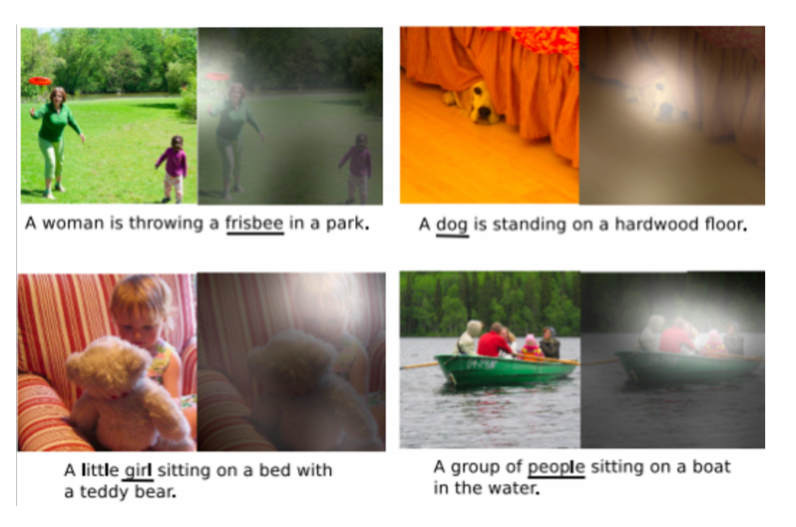
"Show, attend, and tell"에서는 input image에서 Convolution feature를 뽑기 위해 input image를 CNN에 넣습니다.
근데 여기서 다른 점은 feature dimension vector로 그냥 출력하는 것이 아닌, 공간 정보를 유추할 수 있는 14 x 14 feature map을 출력하고, 이 feature map을 RNN에 넣어줍니다.
이 RNN은 반복해서 하나의 word를 생성할 때마다 이 14 x 14 feature map을 referencing 해서 계속 예측을 해나갑니다.

Attention을 사용한 메커니즘은 다음과 같습니다.
Spatial 한 feature (a)가 들어오게 되면 RNN을 통과시켜서 어디를 referencing 해야 하는지 heatmap으로 만들어줍니다. 이 attention과 feature를 잘 결합해서 Z라는 vector를 만들어줍니다. 이러한 방법은 Soft attention embedding이라고 말합니다.

이러한 Attention 메커니즘이 Inference을 할 때 어떤 식으로 사용이 되는지 살펴보도록 하겠습니다.
Image가 주어지면은 Feature를 추출해서 LSTM에 넣어줍니다.
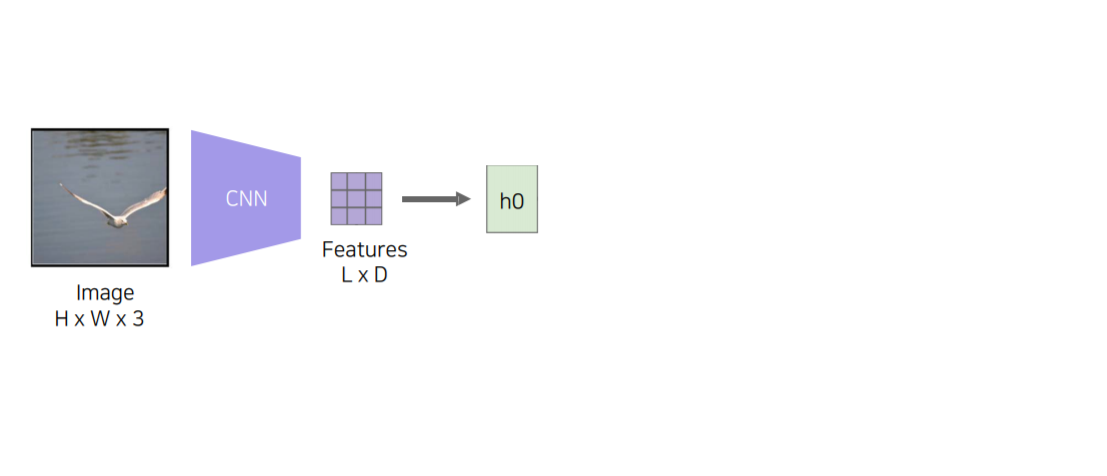
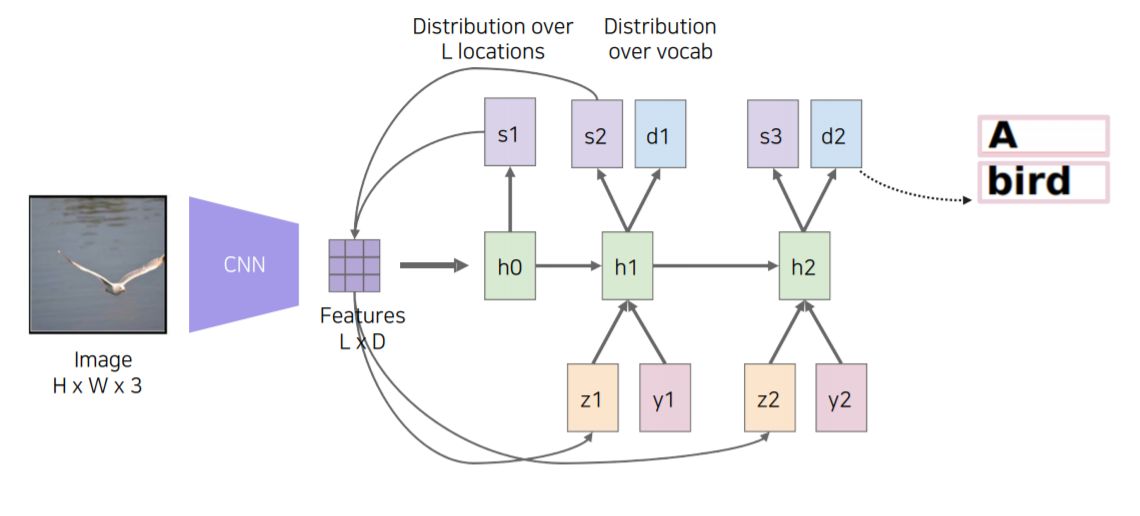
그러면 Condition으로 넣어주면 어떤 부분을 attention 할지 spatial attention을 weight로 출력해 줍니다(아래 그림에서 S1). 그렇다면 이 weight를 이용해서 Feature 하고 inner product를 해서 하나의 vector(아래 그림에서 Z1)를 만들게 됩니다.

그 후, RNN step에 Z1을 Condition으로 넣어주게 되고 Start word token (아래 그림에서 y1)을 넣어주게 됩니다.
사진에서는 갈매기의 날개 부분이 밝게 빛나는 것을 알 수 있는데 이 Feature를 통해서 Start word token이 주어졌을 때 어떤 첫 글자를 뽑을지 h1(RNN에서) 고민하게 됩니다.

그래서 처음 시작한 단어는 "A"가 나오게 됩니다.
그러고 나서는 h1이 어떤 부분을 Referencing 할 것인지 S2에게 예측을 해줍니다.

h1의 예측을 받은 S2가 다시 Feature와 inner product를 해서 Z2라는 conditional vector를 만들어줍니다.
S2에서 갈매기의 양 날개 부분을 referencing 해서 Feature와 inner product를 했기 때문에 Feature에서는 양 날개 위치 부분을 주의 깊게 (attention) 보게 됩니다. (S2 weight들이 그쪽 부분에 값이 높기 때문에 feature와 내적을 하면 그 부분이 높음)
y2에는 이전에 출력했던 "A"라는 문자를 넣어주게 됩니다.

다시 그러면 h2가 z2, y2를 가지고 다음 단어를 prediction 하게 됩니다.
2-2) Text-to-image by generative model
이번에는 Text가 주어지면 image를 만들어주는 model입니다. 이때, image는 한 장만 나오는 것이 아니라 여러 장이 나와야 합니다.

구조는 아래 그림과 같습니다.
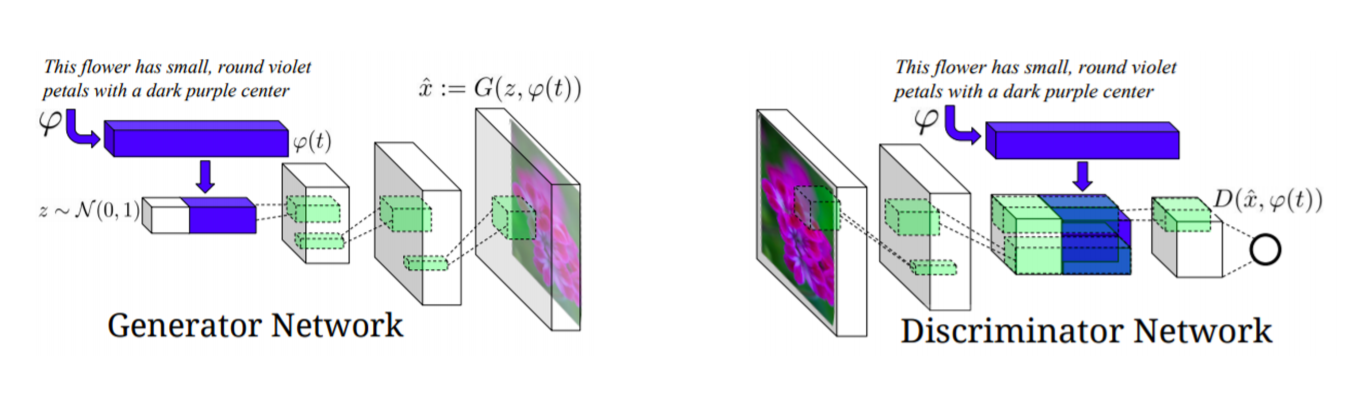
Generator network에서는 text가 들어왔을 때 Fixed dimension vector로 만들어주는 네트워크(아래 그림에서 $\varphi$)를 가지고 있습니다.
그리고 fixed dimension vector 앞에다가 Gaussian Random code ( $z ~ N(0,1)$ )를 붙여줍니다. Gaussian Random code의 역할은 항상 똑같은 input이 들어갔을 때 항상 output 결과가 똑같이 나오는 것을 방지해줍니다. 그래서 다양한 결과가 나올 수 있도록 해줍니다.
그리고 decoder를 거쳐서 image 형태로 generation을 합니다.
Discriminator network는 처음 image가 들어오면 encoder 부분을 거치게 됩니다.
그리고 Generator Network에서 사용했던 text 정보를 Discriminator에서 가지고 와서 사용하게 됩니다. 그래서 이 sentence condition 하에 input 영상이 make sence 한 것인가를 판단하도록 learning을 수행합니다.
3) Referencing
3-1) Visual question answering
Visual question answering은 영상이 주어지고 질문이 주어지면 답을 도출하는 task입니다.
Visual question answering 아키텍처는 다음과 같습니다.
Visual question answering은 Image stream과 Question stream으로 구성되어 있습니다.
Image stream은 pre-trained 된 network를 사용해서 fixed dimension vector 형태로 출력하게 됩니다.
Question stream은 text의 sequence로 RNN으로 encoding을 하게 됩니다.
이 두 개의 vector를 Point-wise multiplication을 해서 두 개의 embedding feature가 interrection을 할 수 있도록 만듭니다.
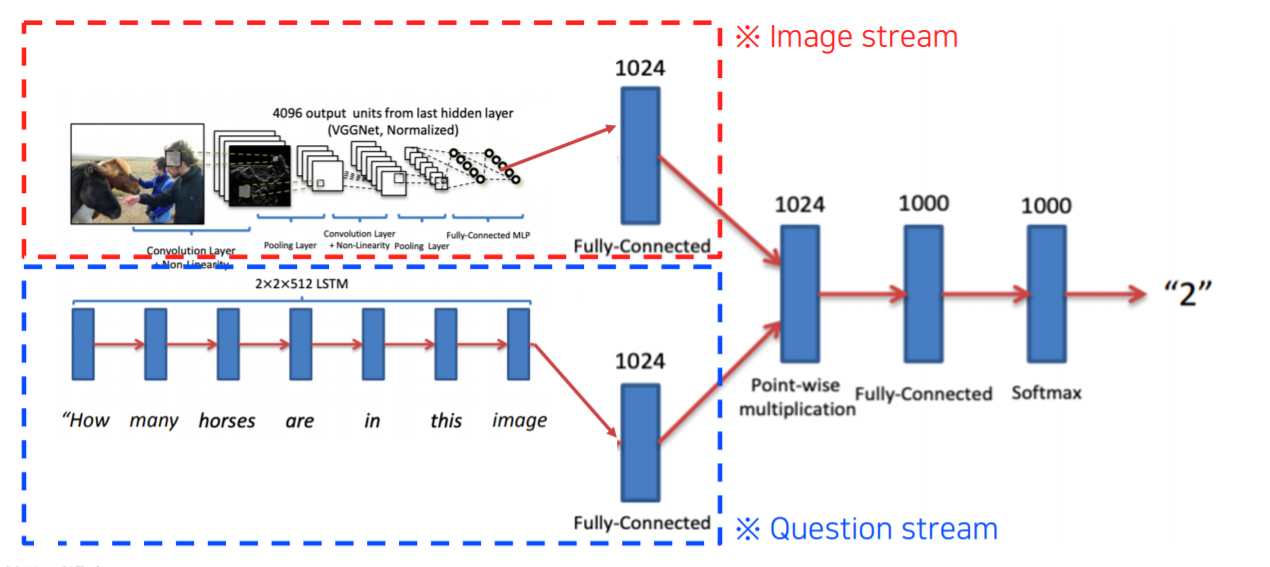
그리고 이 전체 부분을 end-to-end training을 수행하게 됩니다.

2️⃣ Multi-modal tasks (2) - Visual data & Audio
1) Sound 표현 방식
- Waveform : 1d signal로 시간축에 대해 wave 형태로 존재

Waveform에서 Spectrogram으로 변환시키기 위해서는 Fourier transform을 사용합니다.
하지만 Fourier transform을 그냥 사용하는 것이 아니라 다른 방법으로 변환해서 사용합니다.
- Short-time Fourier transform(STFT)
시간축 t에 대해서 존재하는 waveform 전체에 대해 fourier transform을 적용하면 주파수축으로 옮겨가게 됩니다. 그렇지만 주파수축으로 모두 전부 옮겨가게 되면 시간에 따른 변화를 파악할 수가 없습니다. 따라서 제안된 것이 STFT입니다.
STFT는 굉장히 짧은 window 구간 내에서만 fourier transform을 수행합니다.
하지만 fourier transform을 바로 적용하는 것이 아니라 Hamming window로 boundary에 대한 weight를 약하게 주고, 가운데 부분을 강조하는 형태로 window를 곱해줍니다. 이 방법을 사용하면 연결된 부분을 window slicing 할 때 waveform 일부분이 확 잘려서 signal이 급격하게 변하는 것을 방지할 수 있습니다.
그리고 Power spectrum을 가지게 되는데 Power spectrum은 시간에 따라 바뀌기 때문에 여러 Power spectrum을 추출할 수 있습니다. 근데 이것을 일정 간격 띄어서 추출합니다(A: 20~25ms로 띄어서, B: 10ms로 띄어서). 이 일정간격 띄는 것을 Hop 또는 Offset이라고 부릅니다.

✅ 그렇다면 Fourier transform을 왜 할까요?
시간 축에 input signal이 주어지게 되면 Fourier transform을 통해서 각각의 삼각함수가 어느 정도 성분으로 들어가 있는지 다 분해하게 됩니다. 따라서 각 주파수 성분을 파악할 수 있게 됩니다.
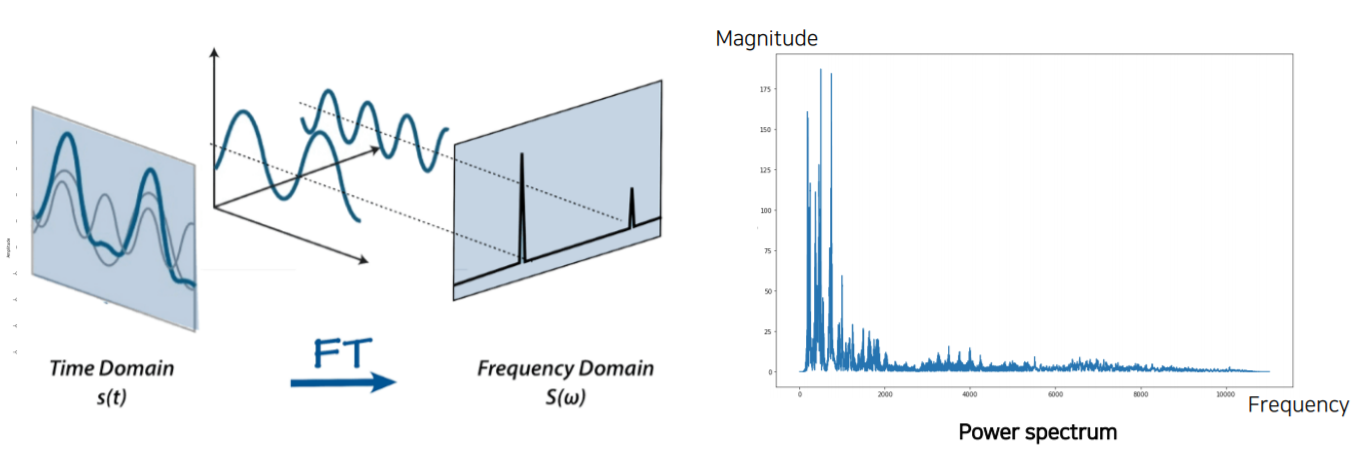
- Spectrogram
그래서 이러한 spectrum 하나하나를 한 window에서 구현하게 되면, 하나하나를 세로로 stack 하게 됩니다.
그러면 시간(t)에 따라서 주파수 성분이 어떻게 변해가는지 눈으로 볼 수 있게 됩니다.

* mel spectrogam : 인간이 안 쓰는 주파수 영역 (7000-8000) 차이를 줄이기 위해 spectrogram에 log를 취해줌. (log함수는 값이 커질수록 점점 값 차이가 생기지 않음)
2) Joint embedding
2-1) Application - Sound paging
Sound를 통해서 현재의 sound를 어떤 장소에서 일어난 지 추측해서 현재 장면을 추측하는 task입니다.

따라서 SoundNet이라는 Network 모델을 사용하게 됩니다.
input으로는 label이 되어있지 않은 video를 사용하고, labeling을 사용하지 않고 기존에 pre-trained 되어있는 Visual Recognition Network를 사용합니다. 이 부분에 Unlabeled Video를 넣어줍니다.
그러면 Visual Recogition Network에서
Object Distribution은 Object가 어떤 것이 들어가 있는지에 대한 distribution을 출력해주고,
Scene Distribution은 Places CNN으로 지금 현재 video가 어떤 장면(scene)에서 촬영되고 있는지를 출력해줍니다.
그리고 video는 audio를 동반하고 있기 때문에 audio를 Raw Waveform 형태로 추출을 해서 CNN에 넣어줍니다.
CNN은 1D-CNN이며, 맨 마지막에는 2개의 head로 분리해줍니다.
첫 번째 head는 Scene Distribution을 따라 하도록, 즉, place recognition을 할 수 있도록
두 번째 head는 Object Dsitribution을 할 수 있도록, 즉, 어떤 obejct들이 존재하는지를
KL divergence를 minimize 하는 형태로 학습을 시켜줍니다.

따라서 이러한 학습 방식을 teacher-student 방식의 학습 방법입니다.
이 방법은 "visual knowledge를 sound에게 tranfer 했다"라고 말할 수 있습니다.
만약 특정 target task가 있을 경우,pool 5에 있는 feature를 추출해서 사용합니다.
Conv8에 존재하는 head들에서 feature를 추출하기에는 Object distribution과 Scene distribution에만 너무 optimizer 되어 있기 때문에 pool 5 부분이 조금 더 generalizable 되어있다고 말할 수 있습니다.
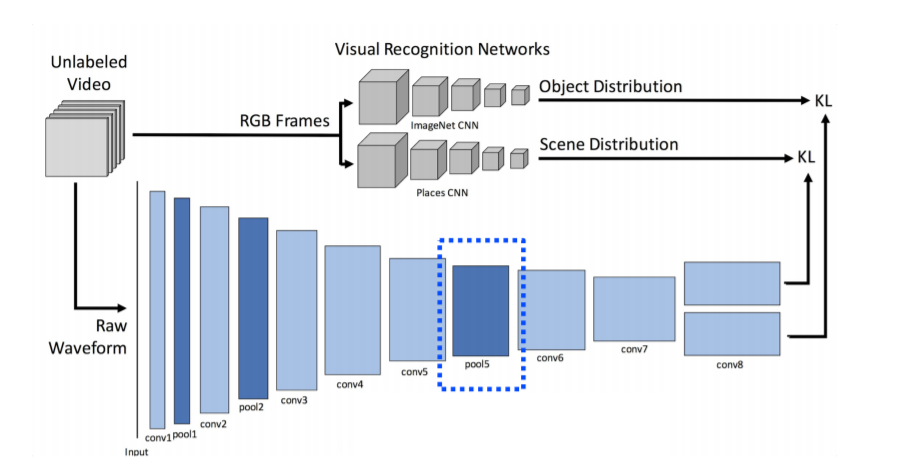
3) Translation
3-1) Speech2Face
어떤 Voice를 듣고 그 Voice를 기반으로 Face를 생성해내는 방법입니다.
그래서 Speech2Face Model은 Spectrogram이 input으로 들어가고 Fixed dimension vector가 나오면 Face Decoder에 들어가서 얼굴을 reconstruction 해주는 translation 모델입니다.

Speech2Face는 Module networks를 적극적으로 활용합니다.
Module network는 각자 담당하고 있는 network가 미리 학습된 것을 잘 조합해서 사용합니다.
VGG-Face Model(pre-trained)은 얼굴 image가 들어오면 Fixed dimension vector 형태로 가지고 옵니다.
Face Decoder(pre-trained)는 face feature가 들어오면 reconsturction해서 face를 출력하게 됩니다.
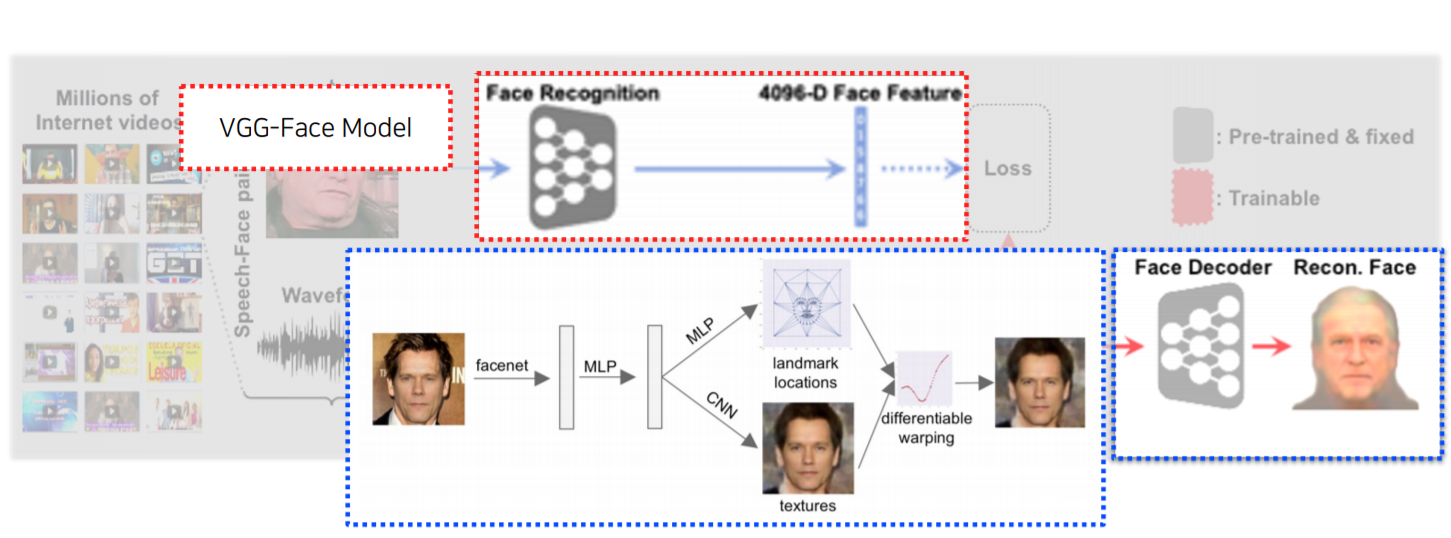
따라서 video에서 image와 speech를 따로 분리한 후, VGG-Face Model과 Speech2Face Model에 보내서 Fixed dimension vector를 추출합니다. 이 두 개의 Fixed dimension vector의 Loss를 구해 차이를 점차 없애가는 방법입니다.
그렇게 되면 Face Decoder는 Face Feature에 호환이 되도록 학습이 되었기 때문에 추가적인 학습 없이 "voice encoder에서 출력된 feature"와 "face feature"와 호환이 되기만 하면 Face Decoder에 넣어줄 수 있습니다.
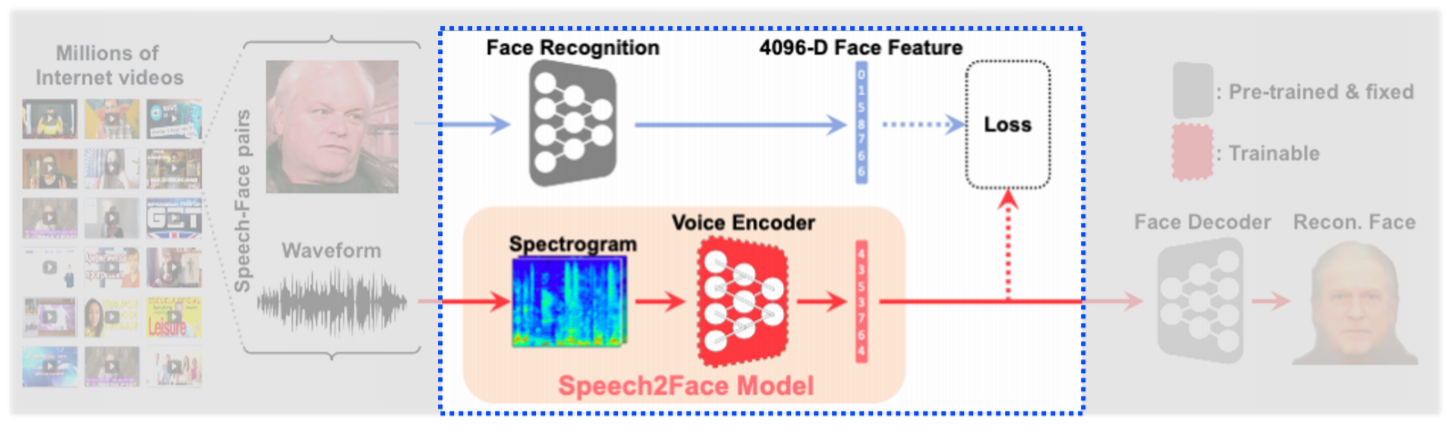
이 방법은 annotation이 필요하지 않습니다. Self supervised 방법이기 때문입니다.
왜냐하면 video 내에서 얼굴 image와 voice가 이미 paired 되어있는 게 자동으로 annotation이 된 것이라고 생각할 수 있습니다.
3-2) Application - Image-to-speech synthesis
Image-to-speech synthesis는 image에서부터 speech를 만드는 방법입니다.

여기서의 Module network는 image가 들어오면 CNN을 통해서 14 x 14 feature map으로 만들어줍니다. 그리고 LSTM + Attention 구조 ( "Show, Attend, and Tell" 구조를 동일하게 사용)를 사용합니다. 대신 하나의 word를 추출하는 것이 아니라 sub-word unit 단위 (ex. token)로 출력을 해줍니다.
그리고 이 sub-word unit에서 speech를 복원하는 Unit-to-Speech Model을 따로 학습해놓습니다.
여기서 Tacotron2 모델을 사용했는데, Tacotron2는 TTS (Text To Speech) 아키텍처입니다.

Learn Units은 Image-to-Unit Model과 Unit-to-Speech Model사이에서 unit이 잘 호환이 될 수 있도록 유도해줍니다.
Speech가 들어오면 Unit이 나오는 Network (Speech-to-Unit Model)을 구성해놓고, Unit이 나오면 Learned Units module에 들어가서 사용이 됩니다.
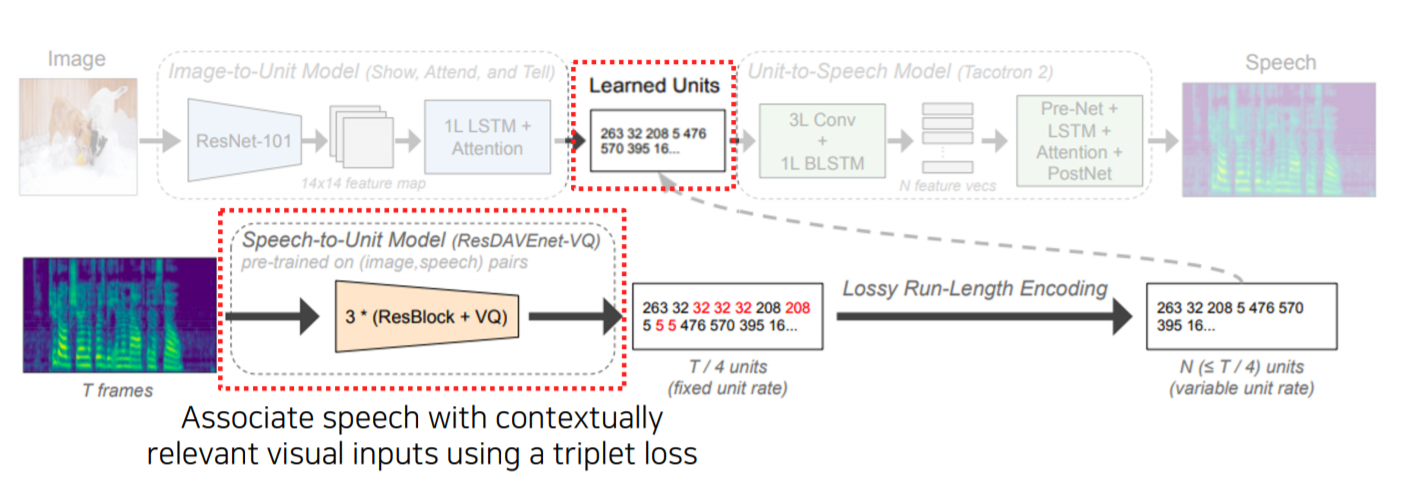
그러면 Speech가 Learned Units에 들어오면 항상 Unit을 출력할 수 있기 때문에 Learned Units -> Image, 또는 Learned Units -> Speech 방향으로 해서 input / output 관계로 따로따로 학습이 가능해집니다.

4) Referencing
4-1) Application - Sound source localization
소리를 input으로 넣어주고 image를 넣어주었을 때 이 소리가 어디에서 나는지 image에서 찾는 방법입니다.

아키텍쳐 구조는 다음과 같습니다.
Image는 Visual recogniziation net으로 학습된 Visual net을 사용하고, Audio도 SoundNet처럼 학습된 CNN 구조를 사용하게 됩니다.

그렇지만 Visual Net에서는 fixed dimension vector를 사용하지 않고 spatial feature를 Attention net에 넘겨주게 됩니다. 따라서 아래 사진에서 Visual Net에서 온 Spactial feature (주황색)와 Audio net에서 온 fixed dimension vector (파란색)을 내적을 통해서 유사도를 측정합니다.
그러면 그 내적 값이 Localization score로 나타나게 됩니다.

Sound source localization은 Unsupervised 방법으로도 학습이 가능합니다.
Image에서 Audio는 annotation으로 활용이 가능하기 때문입니다.
Visual Net에서 추출한 Visual feature map을 $\bigotimes$ 부분까지 가지고 오고, Localization Score를 Weight로 사용합니다. 그리고 feature map(visual feature map)과 Weight(Localization score)를 weighted sum을 해서 pooling을 수행합니다. 그리고 Attended visual feature를 생성합니다.

이렇게 추출한 Attended visual feature 하고 sound에서 나온 feature하고 metric learning 형태로 구해줍니다.
같은 video에서 audio가 나왔다면 가까워지고, 다른 video에서 audio가 나왔다면 멀어지는 형태를 갖습니다.

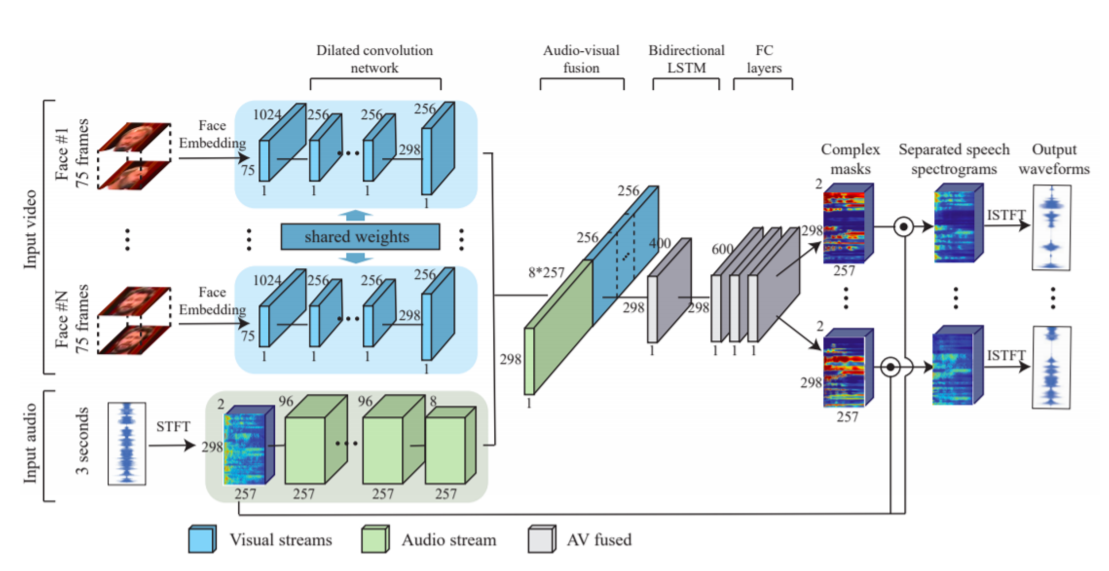
4-2) Application - Speech seperation
Visual 정보를 참조를 해서 speech separate를 하는 방법입니다.

이 방법에서는 Visual Stream과 Audio Stream이 필요합니다.
처음에 N개의 Face가 등장하게 되면 N개에 대해서 Face embedding을 수행해서 Feature vector를 뽑습니다.
그다음에는 Speech에 대해 Spectrogram을 만들어주고 Speech에 대한 정보를 추출하게 됩니다.


뽑힌 N명의 Face Feature vector와 Speech data를 concatenation을 해주고, 각각에 대해서 이 spectrogram을 어떻게 분리해야 하는지 Complex mask 형태로 각각 출력을 해주게 됩니다. 그리고 이 spectrogram mask를 원본 spectrogram과 곱해줘서 filtering 된 최종적인 separated speech spectrogram을 분리하게 됩니다.

그리고 Seperated speech spectrogram을 복호화를 해줘서 wavform으로 구성해줍니다.
Loss는 L2 Loss로 수행하게 됩니다. 하지만 L2 Loss를 사용하려면 "Clean Spectrogram"(N개의 목소리가 섞이지 않은 각각의 정답 spectrogram)과 "생성된 spectrogram"의 차이를 minimalized 해야 합니다. 그렇기 위해서는 clean spectrogram이 annotation 형태로 제공되어야 합니다. 그렇지만 이렇게 합쳐진 video에서 여러 사람이 말하는 경우 clean spectrogram을 얻기가 어렵습니다.
따라서 train data를 합성해서 만듭니다. 2개의 clean speech video를 "concat"을 하고, 거기서 나오는 2개의 audio는 "더해서" 사용합니다.
'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [36] 결정기 (Decision making machine) (0) | 2021.03.15 |
|---|---|
| [35-1] Computer Vision 3D task (0) | 2021.03.13 |
| [34-2] 실제 Backpropagation이 수행되는 원리 (0) | 2021.03.11 |
| [34-1] Conditional generative model (0) | 2021.03.11 |
| [34] Instance/Panoptic segmentation (0) | 2021.03.11 |


