
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- linalg
- scatter
- Operation function
- python 문법
- pivot table
- BOXPLOT
- 최대가능도 추정법
- dtype
- Comparisons
- seaborn
- VSCode
- 가능도
- Numpy
- subplot
- Python 특징
- 카테고리분포 MLE
- Array operations
- ndarray
- 부스트캠프 AI테크
- boolean & fancy index
- type hints
- 정규분포 MLE
- groupby
- Numpy data I/O
- namedtuple
- unstack
- Python
- 딥러닝
- 표집분포
- Python 유래
- Today
- Total
또르르's 개발 Story
[39] 경량화(2) - 양자화 본문
1️⃣ 양자화 (Quantization)
양자화는 아날로그 데이터, 즉 연속적인 값을 디지털 데이터, 즉 띄엄띄엄한 값으로 바꾸어 근사하는 과정을 뜻합니다.
양자화를 하면 다음과 같은 특징이 있습니다.
- model size가 줄어듦
- memory bandwidth requirements가 줄어듦
- inference의 speed up을 위해 가장 중요한 기술
하지만 양자화를 하면 정보 손실이 일어나게 됩니다.
아래 그림과 같이 float32는 크기에 비해 적은 범위를 사용하고 있고, 이 것을 int8에 mapping 시키면 모든 공간 사용이 가능하지만 정보 손실이 일어납니다.

1) Affine quantization
Affine transform은 어떤 linear map에서 형태는 똑같지만(닮음은 유지하면서), 비율이나 크기만 작아지고 커지는 transform입니다.
이와 비슷하게, Affine quantization은 이전 수식이나 형태를 유지하면서, 모델의 비율이나 크기만 작고 크게 quantization을 수행하는 것을 말합니다.
딥러닝에 사용하는 linear + activation 계산도 데이터들의 크기나 order는 그대로 유지하면서 scale up, scale down만 하는 방법으로 진행됩니다.

여기에 Affine quantization을 수행하게 되면 중간중간에 이러한 Float -> INT, INT -> Float와 같은 quantization을 수행하게 됩니다. 이때, 중간중간 Float, int형으로 variance의 scale만 바뀌었을뿐, 모델의 형태 자체가 변하지는 않습니다.

Affine quantization을 수행하는 방법은 다음과 같습니다.

2) Quantizing activation and weights
activation과 weight 모두 quantizing을 할 수 있습니다.
아래 그림은 ReLU activation function을 3-bit로 quantizatin한 것을 볼 수 있습니다.
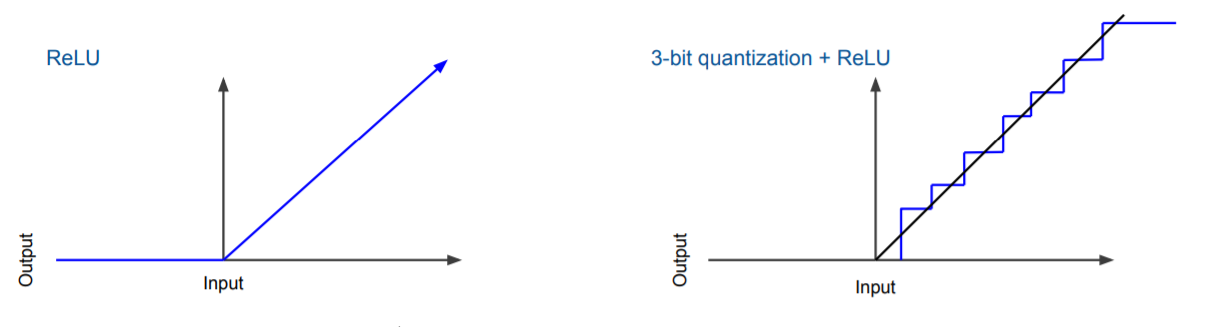
따라서 Activation function에 quantization을 수행할 수 있고, weight 자체에다 quantization을 할 수 있습니다.

3) Quantized value 미분
Quantization의 문제는 backpropagation을 할 때 발생합니다.
바로 미분이 안되는 문제점을 가지고 있습니다.
Quantization을 하게 되면 계단 형태의 함수가 발생하게 되고, flat 한 부분은 미분을 할 수 없기 때문입니다.

따라서 backpropagation을 할 때 $\frac {\partial y} {\partial x}$를 Quantization 하기 전의 값으로 돌려놓고서 Loss를 계산합니다. 즉, 아래 그림에서 y -> x로 돌려놓고 계산을 하게 됩니다.

또는, "Quantization와 같은 계단 형태"와 "orignial 함수와 같은 직선"의 중간 단계인 smoothing을 해서 미분이 가능하게 만드는 경우도 있습니다. T=11의 경우 굴곡이 생기기 때문에 미분이 가능합니다.

2️⃣ 여러 Quantization의 종류
다음은 Deep Learning에 사용되는 Quantization을 로드맵 형태로 표현한 것입니다.
주요 용어들은 다음과 같습니다.
- Static : training을 한 다음에 weight와 activation을 정해진 bit수를 가지고 quantize 합니다.
- Dynamic : weight는 traing 시점에 quantize를 하지만, activation는 Inference 시점에만 quantize를 수행합니다.
- Post-training : training 후에 한 번에 quantize를 수행
- Quantization-aware training : train 과정에 quantize를 수행
train 과정 중에 quantize loss가 이럴 것이다라는 fake node를 가져다 놓고 시뮬레이션을 돌리는 방법입니다.
이렇게 하면 원래 train loss가 향하는 방향보다 약간 틀어져서 quantize가 된 것까지 고려해서 training을 수행합니다.

이 중, Dynamic, Post Training, Quantization-Aware Training을 도식으로 표현하면 다음과 같습니다.

Dynamic, Post Training, Quantization-Aware Training을 표로 작성하면 다음과 같습니다.

'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [40] 경량화(4) - 행렬 분해 (0) | 2021.03.19 |
|---|---|
| [38-1] 경량화(1) - Pruning (0) | 2021.03.17 |
| [38] DL Compiler Acceleration (0) | 2021.03.17 |
| [37-1] Hyperparameter Search & NAS (0) | 2021.03.17 |
| [37] 딥러닝 관점의 Entropy (0) | 2021.03.17 |



