
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python 특징
- 가능도
- boolean & fancy index
- Numpy
- VSCode
- scatter
- BOXPLOT
- 정규분포 MLE
- subplot
- namedtuple
- Operation function
- dtype
- groupby
- linalg
- pivot table
- unstack
- Numpy data I/O
- Python
- 표집분포
- 카테고리분포 MLE
- 부스트캠프 AI테크
- Array operations
- 딥러닝
- python 문법
- seaborn
- Comparisons
- ndarray
- type hints
- 최대가능도 추정법
- Python 유래
- Today
- Total
또르르's 개발 Story
[Stage 1 - 이론] Dataset & DataLoader 본문
1️⃣ Data Augumentation 라이브러리
- torchvision.transforms
- RandomCrop : 랜덤으로 crop을 해서 input으로 넣는 방법
- Flip : 상하 또는 좌우로 반전 / 하지만 flip은 사진을 거꾸로 찍는 사람은 거의 없으므로 역효과가 날 수 있습니다.
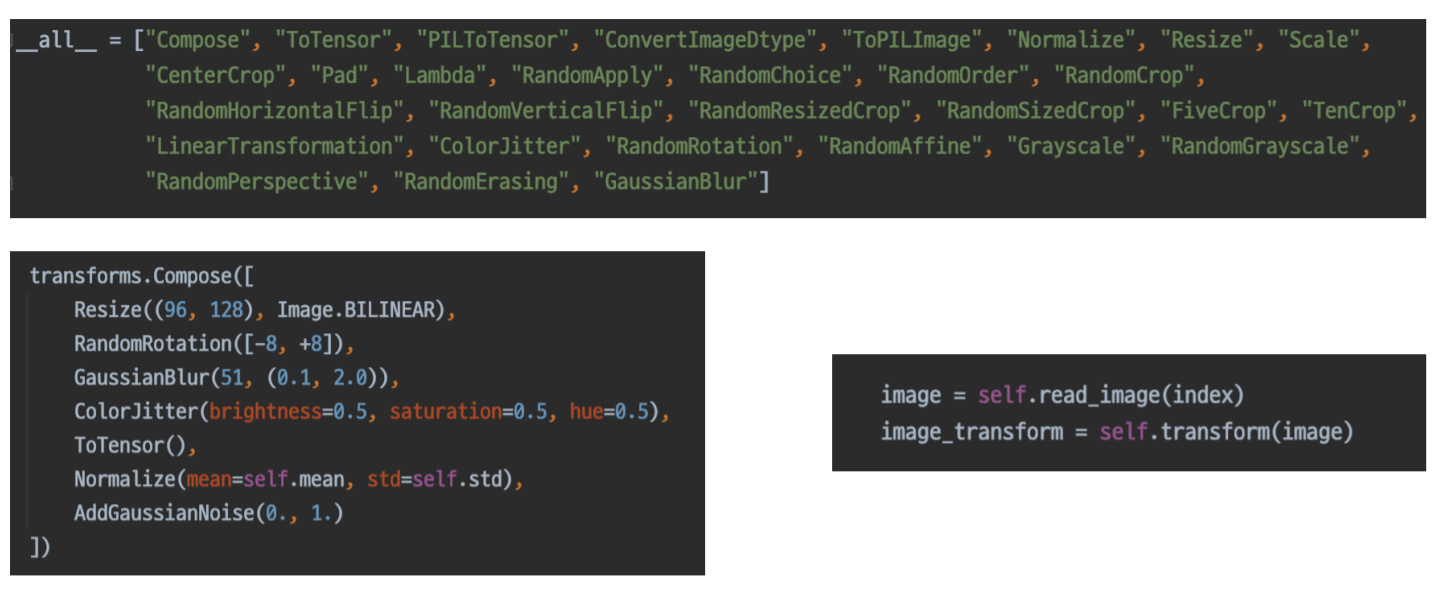
- Albumentations
Albumentations 라이브러리를 사용하면 더 빠르고 더 다양한 data agumentation들을 사용할 수 있습니다.
2️⃣ Generator
모델 학습을 할 때 Data Generator와 Model의 batch size를 맞춰주는 것이 중요합니다.
Data Generator가 초당 10 batch 밖에 되지 않으면 Model의 batch 처리 속도가 아무리 빨라도 Max 10 batch/s이며,
Data Generator의 batch 처리 속도가 아무리 빨라도 Model이 초당 20 batch를 처리한다면 Max 20 batch/s입니다.

Goal에 Generator / Model의 batch 처리 속도를 측정을 추가!
또한, transform의 순서에 따라 속도 차이도 있으니 주의해야 합니다.
RandomRotation -> Resize는 time이 3.65초 정도 걸리는 것에 반해 Resize -> RandomRotation은 time이 2배 정도 늘어난 것을 알 수 있습니다.
이 이유는 처음에 들어가는 input의 shape이 달라지기 때문에 정보량이 늘어나 더 오랜 시간이 걸립니다.

3️⃣ Datasets (torch.utils.data)
기본적인 Dataset의 구조는 다음과 같습니다.

4️⃣ DataLoader
Custom으로 제작된 Dataset을 바로 사용할 수 있지만, mini-batch 방식이나 병렬 처리(num_workers) 등에 효율적인 DataLoader를 사용할 수 있습니다.

- Collate_fn : batch마다 적용하고 싶은 함수를 다르게 주고 싶거나, 취합하는 함수를 넣을 때
- num_workers : 병렬 처리를 위한 parameter. num worker 수가 많을수록 time이 줄어듭니다.

'[P Stage 1] Image Classification > 이론' 카테고리의 다른 글
| [Stage 1 - 이론] Ensemble (0) | 2021.04.02 |
|---|---|
| [Stage 1 - 이론] Training & Inference (0) | 2021.04.01 |
| [Stage 1 - 이론] Model (0) | 2021.03.31 |


