
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 딥러닝
- 정규분포 MLE
- BOXPLOT
- type hints
- Comparisons
- seaborn
- Numpy data I/O
- Array operations
- unstack
- 카테고리분포 MLE
- pivot table
- ndarray
- 표집분포
- Numpy
- 가능도
- subplot
- Operation function
- Python 특징
- 최대가능도 추정법
- scatter
- dtype
- linalg
- namedtuple
- VSCode
- Python
- Python 유래
- 부스트캠프 AI테크
- groupby
- python 문법
- boolean & fancy index
Archives
- Today
- Total
또르르's 개발 Story
[Stage 1 - 이론] Ensemble 본문
1️⃣ Ensemble 기법들
1) Model Averaging (Voting)
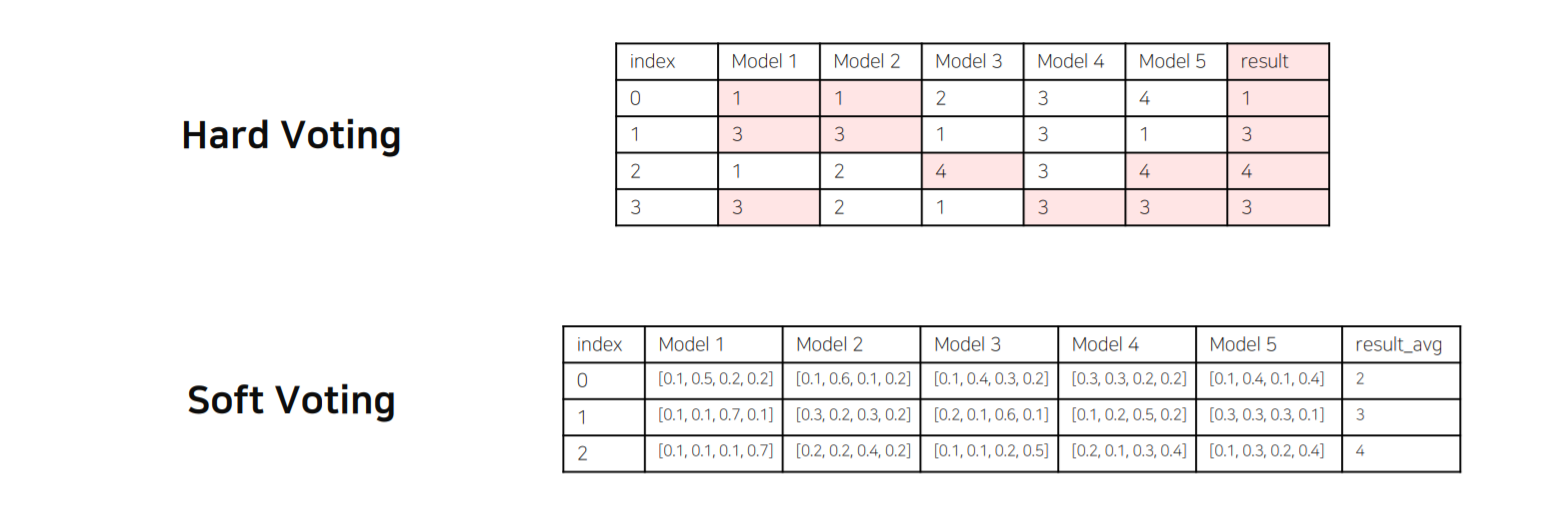
다양한 Model의 투표를 통해 결과를 내는 방법입니다.
일반적으로 Soft voting 방식의 성능이 Hard voting보다 좋습니다.
2) Stratified K-Fold Cross Validation
가능한 경우를 모두 고려 + Spllit 시에 Class 분포까지 고려하는 방법입니다.
단점은 K 숫자에 따라서 iteration이 K배 늘어납니다.

3) TTA (Test Time Augmentation)
Test에 사용되는 이미지를 Augmentation한 후 출력된 여러가지 결과를 Ensemble하는 방법

4) 성능과 효율의 Trade-off
Ensemble 효과는 확실히 있지만 그만큼 학습, 추론 시간이 배로 소모됩니다.

2️⃣ Hyperparameter Optimization
Hyperparameter를 최적화시키는 방법입니다. 요즘에는 많이 사용하지 않습니다.
(걸리는 시간에 비해 성능이 좋지 않기 때문)
주요한 Hyperparameter는 다음과 같습니다.

'[P Stage 1] Image Classification > 이론' 카테고리의 다른 글
| [Stage 1 - 이론] Training & Inference (0) | 2021.04.01 |
|---|---|
| [Stage 1 - 이론] Model (0) | 2021.03.31 |
| [Stage 1 - 이론] Dataset & DataLoader (0) | 2021.03.30 |
'[P Stage 1] Image Classification/이론' Related Articles
more



Comments