
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 부스트캠프 AI테크
- Numpy
- ndarray
- 카테고리분포 MLE
- Comparisons
- scatter
- boolean & fancy index
- 표집분포
- pivot table
- Python 유래
- namedtuple
- subplot
- BOXPLOT
- seaborn
- 딥러닝
- unstack
- Array operations
- VSCode
- Operation function
- 정규분포 MLE
- Numpy data I/O
- Python
- groupby
- linalg
- type hints
- 최대가능도 추정법
- dtype
- python 문법
- Python 특징
- 가능도
- Today
- Total
또르르's 개발 Story
[Stage 1 - 03] Model & Optimizer 본문
1️⃣ Goal
[BaseLine 작성] (추가 : 3/29, 기간 : 3/29 ~ 3/29)- [Data Processing]
-Face Recognition (추가 : 3/29, 기간 : 3/30 ~ 3/31)
- Cross-validation 사용 (추가 : 3/29)
- 데이터 불균형 해소 / Focal Loss, OverSampling, Sampler (추가 : 3/30, 기간 : 4/1 ~ )
- Data Augumentation (추가 : 3/30)
-Generator의 초당 Batch 처리량 측정 및 향상 (추가 : 3/30, 기간 : 3/31 ~ 3/31)- Cutmix 시도 (추가 : 4/1)
- Repeated Agumentation (추가 : 4/1)
- validation data 사용 (추가 : 4/1, 기간 : 4/1 ~ ) - [Model]
- ResNet 152층 시도 (추가 : 3/29)
- Efficient Net 시도 (추가 : 3/29, 기간 : 4/1 ~ )
- YOLO 시도 (추가 : 3/31)
- Pre-trained 모델에 Fine-tuning 하기 (추가 : 3/29, 기간 : 4/1 ~ )
- Model의 초당 Batch 처리량 측정 및 향상 (추가 : 3/30)
- dm_nfnet 시도 (추가 : 4/1) - [Training]
- 앙상블 시도 (추가 : 3/29)
- Hyperparameter 변경 (추가 : 3/29, 기간 : 3/29 ~)
- Learning Schedular 사용 (추가 : 3/29, 기간 : 4/1 ~ )
- Model의 초당 Batch 처리량 측정 (추가 : 3/30)
- 좋은 위치에서 Checkpoint 만들기 (추가 : 4/1)
- Sex 분류 (1번 모델) -> Age 분류 (2번 모델) -> Mask 분류 (3번 모델) // 모델 나누기 (추가 : 4/1)
- Crop image (mask 분류)와 일반 image(age, sex 등 분류) 둘 다 사용 (추가 : 4/1) - [Deploy]
- Python 모듈화 (추가 : 3/30)
2️⃣ Learning
[Stage 1 - 이론] Model
1️⃣ Model 정의 1) nn.Modules nn.Modules를 상속받아서 사용하면 model 객체 자체를 print (오른쪽 위) 하거나 modules() 함수를 사용 (오른쪽 아래)해서 모듈의 구조를 파악할 수 있습니다. 또한, forward 함..
dororo21.tistory.com
[Stage 1 - 이론] Training & Inference (수정)
1️⃣ Loss 1) Custom Loss Focal Loss Class Imbalance 문제(확률 자체가 낮게 측정됨)가 있는 경우, 맞춘 확률이 높은 Class는 조금의 loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여합니다. Label Sm..
dororo21.tistory.com
- Office hour
- Knowledge distilliation과 Label smoothing을 같이 사용하면 성능이 떨어질 수 있음
- Knowledge distilliation을 사용하면 성능 향상
- Label smoothing을 사용하면 성능 향상
- CutMix를 사용하면 성능 향상
- 16 bit float로 하면 더 빠른 속도/ 성능을 가질 수 있음
- Repeated Augmentation ( 한 batch에 같은 원본 사진이지만 다른 transform으로 넣는 방법)을 사용!
- 초반에는 작고 속도가 빠른 model을 사용해서 다양한 augmentation, hyperparameter를 사용해보고, 대회 막바지에 큰 모델을 오래 돌리는 것이 좋음
- 노이즈가 많은 데이터셋일수록 빨리 학습을 끝내는 것이 중요, 오래 학습하면 노이즈까지 학습하기 때문에
3️⃣ Main Task
1) 데이터 불균형 해소 : imbalanced-dataset-sampler
데이터 불균형 문제를 해결하기 위해서 찾은 방법은 Focal Loss, Over and under sampling 입니다.
이번에는 Over and under sampling 방법을 섞은 imbalanced-dataset-sampler 방법을 사용했습니다.
원래 Over and under sampling은 데이터를 복사하거나 선별하여 만들지만 문제점이 존재합니다.
Over sampling은 소수 클래스를 복사하기 때문에 과적합이 발생할 수 있습니다.
Under sampling은 다수 클래스에서 선별하기 떄문에 정보 손실이 발생합니다.

imbalanced-dataset-sampler는 다음과 같은 방법으로 수행합니다.
- imbalanced dataset에서 샘플링을 할 때 class의 분포 재조정
- 샘플링 가중치를 자동으로 추정
- avoid creating a new balanced dataset (?)
- Over sampling에서 발생하는 overfitting을 방지
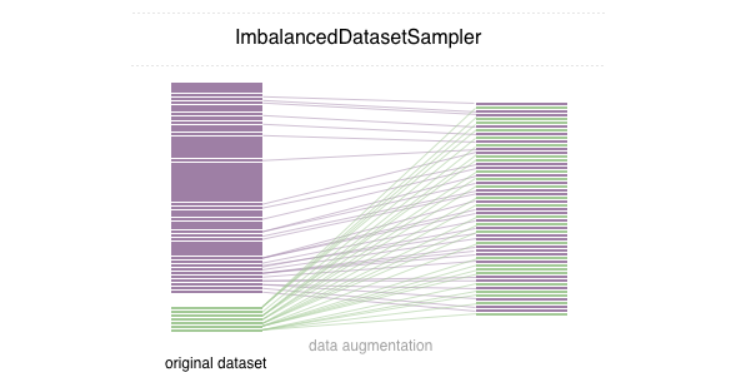
적용하기 위해서는 git에서 clone 후 setup.py를 install합니다. (또는 setup.py가 들어있는 폴더에서 pip instll .을 실행합니다.)
!python setup.py install!pip install .
torchsampler에서 ImbalancedDatasetSampler를 import합니다.
from torchsampler import ImbalancedDatasetSampler
DataLoader에서 sampler=ImbalancedDatasetSampler(train_dst)를 추가해줍니다.
(여기서 suffle=True를 빼주어야하는데 SubsetRandomSampler가 동작하기 때문이라고 합니다.
train_iter = torch.utils.data.DataLoader(train_dst, sampler=ImbalancedDatasetSampler(train_dst), batch_size=BATCH_SIZE)
valid_iter = torch.utils.data.DataLoader(valid_dst, sampler=ImbalancedDatasetSampler(valid_dst), batch_size=BATCH_SIZE)
이때, 오류가 나서 torchsampler의 imbalanced.py의 _get_label() 함수를 약간 수정해주었습니다.
def _get_label(self, dataset, idx):
...
elif isinstance(dataset, torch.utils.data.Subset):
return dataset.dataset.imgs[idx][1]
else:
return dataset[idx][1] # custom dataset이기 때문에 여기로 들어갑니다.
그냥 DataLoader를 할 때보다 동작하는데 훨씬 오래걸립니다.
이후 데이터를 찍어보면 800개 후반대로 모두 맞춰집니다. (차후에 사진 첨부)
2) Validation data
원래 K-fold Cross-Validation을 사용하려고 했지만, 시간이 오래 걸린다고해서, 간단한 Validation data를 구현했습니다.
모듈은 sklearn을 사용했습니다.
#validation data
train_image, validation_image, train_target, validation_target = train_test_split(train_data_list, train_label_list, test_size=0.2, shuffle=True, stratify=train_label_list)
valid_dst = TrainDataset(validation_image, validation_target, transform)valid_iter = torch.utils.data.DataLoader(valid_dst, sampler=ImbalancedDatasetSampler(valid_dst), batch_size=BATCH_SIZE)
3) Pre-trained된 Efficient-Net 사용
현재 (2021년 4월 기준) 가장 좋은 NFNet이 나왔지만 Parameter 수가 어마어마해서 Efficient-net-b6 모델을 사용했습니다.
Pre-trained를 불러오는 과정은 정말 간단했습니다.
from efficientnet_pytorch import EfficientNet
C = EfficientNet.from_pretrained('efficientnet-b6', num_classes=18).to(device)
4) Learning Scheduler
CosineAnnealingLR을 사용했습니다.

parameter로 $T_{max}$ (최대 iteration 횟수)와 eta_min을 조정하는데 learning rate가 cos함수를 기반으로 eta_min까지 갔다가 다시 초기 learning rate까지 올라갑니다.
scheduler = optim.lr_scheduler.CosineAnnealingLR(optm, T_max=10, eta_min=0)
train할 때 다음과 같이 사용합니다.
for epoch in range(EPOCHS):
for batch_in,batch_out in tqdm(train_iter):
# Forward path
y_pred = C.forward(batch_in.view(-1, 3, 160, 160).to(device))
loss_out = loss(y_pred,batch_out.to(device))
# Update
optm.zero_grad()
loss_out.backward()
optm.step()
scheduler.step() # scheduler.step()을 사용해서 learning rate update
4️⃣ Sub Task
없음.
5️⃣ Evaluation
| 날짜 | Data processing | Model | Training | Time | Accuracy | F1 |
| 3/29 | - ResNet-50 - |
- Hyperparmeter 설정 - |
7h 32m | 61.87% | 0.52% | |
| 3/31 | - Face Recognition - |
36m | 65.05% | 0.56% | ||
| 4/1 | - (pre-trained) Efficient-Net-b6 - |
- epoch : 20, batch size : 128 - |
1h 35m | 73.67% | 0.66% | |
| 4/1 | - (pre-trained) Efficient-Net-b7 - |
- epoch : 20, batch size : 100 - |
1h 31m | 73.25% | 0.66% | |
| 4/1 | - learning scheduler : CosineAnnealingLR - epoch : 21 - |
1h 41m | 68.49% | 0.60% |
* F1 Score

1) 데이터 불균형 해소 : imbalanced-dataset-sampler
Over and under Sampling을 섞어 만든 Sampler로 다수 class의 data는 줄이고, 소수 class의 data는 늘리는 방식을 사용했습니다.
다수 class의 data 수는 4000개 정도이며, 소수 class의 data 수는 80개 정도였는데 모두 800개 정도의 data로 맞춰졌습니다. 만약 성능이 좋지 않게 나오면 Focal loss나 기본적인 Over and under Sampling을 해보는 것도 나쁘지 않을 것 같습니다.
-> 성능이 비슷하게 나와서 Focal loss나 Over Sampling으로 (추가 : 4/2)
2) Validation data
Validation data를 나누는 것은 sklearn 모듈로 쉽게 했습니다.
시간이 난다면 K-fold cross validation도 넣어볼 것 입니다.
3) Pre-trained된 Efficient-Net 사용
확실히 ResNet을 사용했을 때보다 Accuracy와 f1-score가 증가했습니다. (역시 최신 모델)
efficientnet-b6와 efficientnet-b7를 둘 다 테스트했을 때,
b6 model + batch size=128가 b7 model + batch size = 100 보다 성능이 약간 높았습니다.
4) Learning Scheduler
CosineAnnealingLR을 사용했는데 learning rate가 왔다갔다해서 최적 weight를 못잡은 것도 있습니다.
local minimum을 탈출하기 위해 많이 사용한다고 하는데 성능은 정확히 모르겠습니다.
ReduceLROnPlateau 등 다양한 learning scheduler를 사용해보려고 합니다.
3) 차후 목표
- Focal-loss 사용
- OverSampling 사용
- ReduceLROnPlateau 사용
'[P Stage 1] Image Classification > 프로젝트' 카테고리의 다른 글
| [Stage 1 - 06] 최적의 Hyperparameter 찾기 (0) | 2021.04.05 |
|---|---|
| [Stage 1 - 05] Remote Server에서 NNI (Auto ML) 사용하기 (0) | 2021.04.04 |
| [Stage 1 - 04] Focal Loss (0) | 2021.04.02 |
| [Stage 1 - 02] Data Processing (0) | 2021.03.30 |
| [Stage 1 - 01] BaseLine 작성 (0) | 2021.03.30 |


