
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- dtype
- 최대가능도 추정법
- Python
- BOXPLOT
- pivot table
- 표집분포
- subplot
- 가능도
- ndarray
- type hints
- Python 유래
- 정규분포 MLE
- Operation function
- 딥러닝
- Numpy
- Array operations
- scatter
- linalg
- groupby
- VSCode
- unstack
- 부스트캠프 AI테크
- Python 특징
- seaborn
- python 문법
- boolean & fancy index
- Numpy data I/O
- namedtuple
- Comparisons
- 카테고리분포 MLE
- Today
- Total
또르르's 개발 Story
[Stage 1 - 06] 최적의 Hyperparameter 찾기 본문
1️⃣ Goal
[BaseLine 작성] (추가 : 3/29, 기간 : 3/29 ~ 3/29)- [Data Processing]
-Face Recognition (추가 : 3/29, 기간 : 3/30 ~ 3/31)
- Cross-validation 사용 (추가 : 3/29)
-데이터 불균형 해소 /imbalanced Sampler,Focal Loss, OverSampling, Weighted loss (추가 : 3/30, 기간 : 4/1 ~ )
- Data Augumentation (Affine, Gaussian 등) (추가 : 3/30, 추가 : 4/5 ~ )
-Generator의 초당 Batch 처리량 측정 및 향상 (추가 : 3/30, 기간 : 3/31 ~ 3/31)- Cutmix 시도 (추가 : 4/1)
- Repeated Agumentation (추가 : 4/1)
-validation data 사용 (추가 : 4/1, 기간 : 4/1 ~ 4/1) - [Model]
- ResNet 152층 시도 (추가 : 3/29)
-Efficient Net 시도 (추가 : 3/29, 기간 : 4/1 ~ 4/2)
- YOLO 시도 (추가 : 3/31)
-Pre-trained 모델에 Fine-tuning 하기 (추가 : 3/29, 기간 : 4/1 ~ 4/1)
- Model의 초당 Batch 처리량 측정 및 향상 (추가 : 3/30)
- dm_nfnet 시도 (추가 : 4/1) - [Training]
- 앙상블 시도 (추가 : 3/29)
- Hyperparameter 변경 (추가 : 3/29, 기간 : 3/29 ~)
- Learning Schedular 사용 (추가 : 3/29, 기간 : 4/1 ~ )
- Model의 초당 Batch 처리량 측정 (추가 : 3/30)- 좋은 위치에서 Checkpoint 만들기 (Adam으로 모든 minimum 찾고, SGD로 극소점 찾기) (추가 : 4/1, 새로운 baseline code)
- Sex 분류 (1번 모델) -> Age 분류 (2번 모델) -> Mask 분류 (3번 모델) // 모델 나누기 (추가 : 4/1)
- Crop image (mask 분류)와 일반 image(age, sex 등 분류) 둘 다 사용 (추가 : 4/1, 기간 : 4/5 ~ )
- batch size 작게 쓰면서, SGD 사용 (추가 : 4/2)
-NNI (Auto ML) 사용 (추가 : 4/2, 기간 : 4/2 ~ 4/4) - [Deploy]
-Python 모듈화 (추가 : 3/30, 새로운 baseline code)
2️⃣ Learning
없음.
3️⃣ Main Task
1) NNI에서 Data Augmentation 추가하기
Model을 좀 더 Robust하게 만들기 위해서 augmentation에 Affine Augmentation과 Gaussian Augmentation을 추가합니다.
# search_space.json
{
"batch_size": {"_type":"choice", "_value": [8, 16, 32, 64, 128]},
"lr":{"_type":"choice","_value":[0.001, 0.01, 0.1]},
"model": {"_type" : "choice", "_value" : ["Efficientnet_b6", "Efficientnet_b0", "Efficientnet_b3"]},
"criterion": {"_type": "choice", "_value" : ["focal", "label_smoothing", "cross_entropy", "f1"]},
"augmentation": {"_type": "choice", "_value" : ["BaseAugmentation", "AffineAugmentation", "GaussianAugmentation"]}
}
Affine Augmentation을 Class로 만들고, transforms.Compose에 RandomAffine을 추가합니다.
class AffineAugmentation:
def __init__(self, resize, mean, std, **args):
self.transform = transforms.Compose([
transforms.CenterCrop([350, 350]),
Resize(resize, Image.BILINEAR),
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
ColorJitter(0.1, 0.1, 0.1, 0.1),
ToTensor(),
Normalize(mean=mean, std=std)
])
def __call__(self, image):
return self.transform(image)
Gaussian Augmentation도 transform으로 만들고 Gaussian Noise를 추가해줍니다.
class AddGaussianNoise(object):
"""
transform 에 없는 기능들은 이런식으로 __init__, __call__, __repr__ 부분을
직접 구현하여 사용할 수 있습니다.
"""
def __init__(self, mean=0., std=1.):
self.std = std
self.mean = mean
def __call__(self, tensor):
return tensor + torch.randn(tensor.size()) * self.std + self.mean
def __repr__(self):
return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)
class GaussianAugmentation:
def __init__(self, resize, mean, std, **args):
self.transform = transforms.Compose([
transforms.CenterCrop([350, 350]),
Resize(resize, Image.BILINEAR),
ColorJitter(0.1, 0.1, 0.1, 0.1),
ToTensor(),
Normalize(mean=mean, std=std),
AddGaussianNoise()
])
def __call__(self, image):
return self.transform(image)
train.py에서는 parser.args['augmentation'] 값을 받아와 dataset에 transform으로 지정해줍니다.
transform_module = getattr(import_module("dataset"), args['augmentation']) # default: BaseAugmentation
transform = transform_module(
resize=args['resize'],
mean=dataset.mean,
std=dataset.std,
)
dataset.set_transform(transform)2) NNI로 최적의 Hyperparameter 찾기 + [ Crop / 일반 image ] 비교
찾고 싶은 hyperparameter의 종류는 다음과 같습니다.
- batch_size : 최적의 batch size 조합
- model : 모두 Efficientnet만 사용했는데 다양성이 떨어지네요..
- criterion : focal, label smoothing, cross entropy, f1 사용 (다음에는 weighted loss도 사용)
- data dir : crop image와 일반 image를 가지고 훈련시켰을 때 성능이 차이가 나는지 궁금했습니다.
# search_space.json
{
"batch_size": {"_type":"choice", "_value": [8, 16, 32, 64, 128, 140]},
"model": {"_type" : "choice", "_value" : ["Efficientnet_b6", "Efficientnet_b0", "Efficientnet_b3"]},
"criterion": {"_type": "choice", "_value" : ["focal", "label_smoothing", "cross_entropy", "f1"]},
"data_dir": {"_type": "choice", "_value" : ["/opt/ml/input/data/train/crop_images", "/opt/ml/input/data/train/images"]}
}
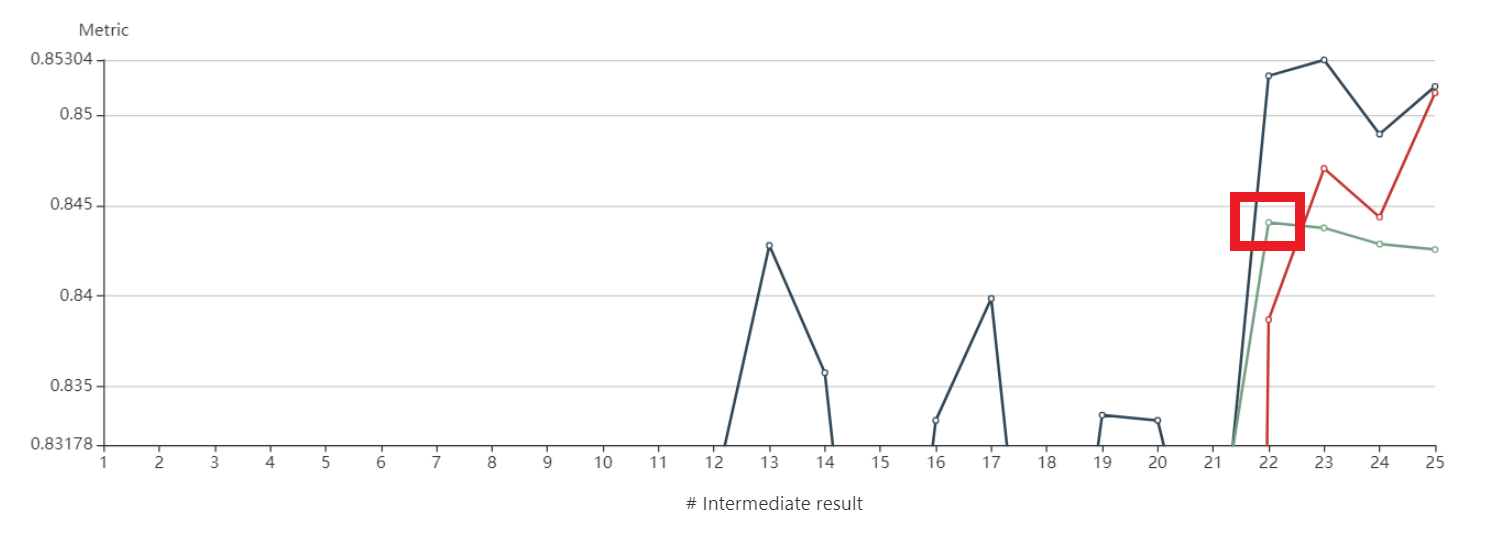
space_search의 parameter를 가지고 돌려보면 다음과 같습니다.
- Duration : 8h
- Trial Number : Succeeded 7 / Failed 1 (아마 cuda out of memory)

(1) 성능 : 0.8530% (남색)
- batch size : 64
- model : Efficientnet_b6
- criterion : cross_entropy
- data : 일반 images
- epochs : 23


(2) 성능 : 0.8512% (빨강)
- batch size : 140
- model : Efficientnet_b3
- criterion : focal
- data : crop images
- epochs : 25


(3) 성능 : 0.8440% (초록)
- batch size : 140
- model : Efficientnet_b3
- criterion : label_smoothing
- data : crop images
- epochs : 22
(4) 성능 : 0.8306% (주황)
- batch size : 32
- model : Efficientnet_b6
- criterion : label_smoothing
- data : crop images
- epochs : 25


(5) 성능 : 0.8196% (연두)
- batch size : 16
- model : Efficientnet_b3
- criterion : cross_entropy
- data : 일반 images
- epochs : 18


(6) 성능이 안나오는 hyperparameter
- batch size : 8
- model : Efficientnet_b0
- criterion : f1
- data : 일반 images
- epochs : 25
- batch size : 8
- model : Efficientnet_b6
- criterion : f1
- data : 일반 images
- epochs : 25
모두 batch size 8, criterion f1을 사용하고 있습니다.

4️⃣ Sub Task
없음.
5️⃣ Evaluation
| 날짜 | Data processing | Model | Training | Time | Accuracy | F1 |
| 3/29 | - ResNet-50 - |
- Hyperparmeter 설정 - |
7h 32m | 61.87% | 0.52% | |
| 3/31 | - Face Recognition - |
36m | 65.05% | 0.56% | ||
| 4/1 | - (pre-trained) Efficient-Net-b6 - |
- epoch : 20, batch size : 128 - |
1h 35m | 73.67% | 0.66% | |
| 4/1 | - (pre-trained) Efficient-Net-b7 - |
- epoch : 20, batch size : 100 - |
1h 31m | 73.25% | 0.66% | |
| 4/1 | - learning scheduler : CosineAnnealingLR - epoch : 21 - |
1h 41m | 68.49% | 0.60% | ||
| 4/2 | - imbalanced-dataset-sampler - |
- learning scheduler X - epoch : 26 - |
1h 39m | 72.38% | 0.64% | |
| 4/2 | - loss : Focal loss ($\gamma$ = 2) - epoch : 16 - |
1h 29m | 74.43% | 0.68% |
* F1 Score

1) NNI에서 Data Augmentation 추가하기
- 대부분 base agumentation에서 좋은 성능을 보이는 것을 알 수 있습니다.
- Gaussian, Affine agumentation을 사용하면 약간의 성능 하락을 보입니다.



추가로 perspective Agumentation을 해보는 것이 목표입니다.
2) 최적의 Hyperparameter 찾기 + [crop / 일반 image] 비교
일단, FaceNet을 사용한 crop image와 일반 image의 차이는 거의 없는 것 같습니다.
최적의 Hyperparameter는 아직 더 많은 실험이 필요합니다.
다만, 피해야할 Hyperparameter는 batch size 8, f1 loss를 사용하는 것입니다.
'[P Stage 1] Image Classification > 프로젝트' 카테고리의 다른 글
| [Stage 1 - 08] No Augmentation (0) | 2021.04.08 |
|---|---|
| [Stage 1 - 07] Ensemble 하기 (0) | 2021.04.08 |
| [Stage 1 - 05] Remote Server에서 NNI (Auto ML) 사용하기 (0) | 2021.04.04 |
| [Stage 1 - 04] Focal Loss (0) | 2021.04.02 |
| [Stage 1 - 03] Model & Optimizer (0) | 2021.04.01 |



