
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Numpy data I/O
- pivot table
- 표집분포
- Comparisons
- groupby
- Numpy
- type hints
- subplot
- BOXPLOT
- VSCode
- Operation function
- python 문법
- Python 특징
- dtype
- scatter
- namedtuple
- unstack
- 부스트캠프 AI테크
- linalg
- Array operations
- boolean & fancy index
- 카테고리분포 MLE
- Python 유래
- 최대가능도 추정법
- seaborn
- Python
- ndarray
- 가능도
- 정규분포 MLE
- 딥러닝
- Today
- Total
또르르's 개발 Story
[13] CNN(Convolutional Neural Network) 본문
1️⃣ Convolution
convolution의 수식을 표현하면 아래와 같습니다.
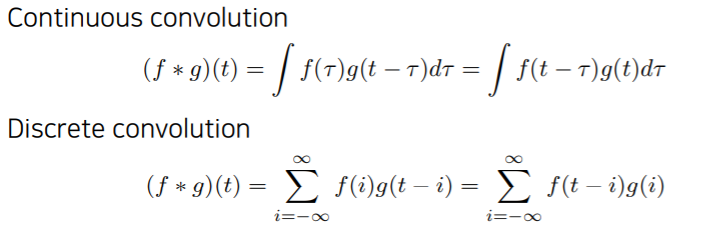
CNN에서는 대부분 2D image를 가지고 convolution을 하기 때문에 2-Dimensions convolution을 사용합니다.
여기서 $I$는 image를 나타내고 $K$는 filter를 나타냅니다.

수식으로는 이해하기 어렵지만 쉽게 말해서 filter $K$를 가지고 image $I$를 찍는 작업을 한다고 생각하시면 편합니다.


그렇다면 2D convolution을 한다는 것은 어떤 의미가 있을까요?
convolution filter $K$의 모양을 이미지 $I$에 찍는 작업을 수행하는데,
적용하고자 하는 필터의 모양에 따라서 같은 이미지의 모양이 Blur(흐림), Emboss(강조), Outline(외곽선)으로 나올 수 있습니다. Convolution filter를 사용하면 image를 수정하고 검출하는 것이 가능해집니다.

RGB 이미지를 Convolution하기 위해서는 아래와 같이 channel이 3인 tensor을 사용합니다.

위 사진에서 가운데 tensor는 가로길이*세로길이*3(channel)로 표현하는데 channel이 3인 이유는 R,G,B 총 3개의 값으로 표현되기 때문입니다.
이 떄 filter도 가로*세로*3짜리 필터를 사용해야합니다.(filter의 channel 개수 = image의 channel 개수)
그러면 feature은 가로*세로*1짜리 output이 나옵니다.
아래 사진과 같이 5x5 filter을 사용할 때 channel이 3으로 맞춰야하고, feature의 channel이 4개로 만들려면 총 4개의 (5x5x3)의 filter가 필요합니다.

2️⃣ CNN (Convolutional Neural Networks)
1) CNN 개요

CNN은 convolution layer와 pooling layer, fully connected layer로 존재합니다.
- convolution과 pooling layer : 그림에서 특정정보를 추출
- fully connected layer : 의사 결정 역할
요즘 나오는 논문에는 fully connected가 줄어가는 추세라고 합니다.
왜냐하면 fully connected가 parameter 숫자에 dependent하기 때문인데요.
우리가 학습해야하는 parameter의 숫자가 늘어나면 늘어날수록, 학습이 어렵고 generalization(일반화)이 떨어진다고 알려져있습니다.
따라서 요즘 CNN은 Convolution과 pooling layer의 depth를 늘리는 동시에 parameter 숫자를 줄이는데 집중하게 됩니다.
CNN은 위 3개의 layer말고도 Stride와 Padding이라는 개념을 사용합니다.
- Stride
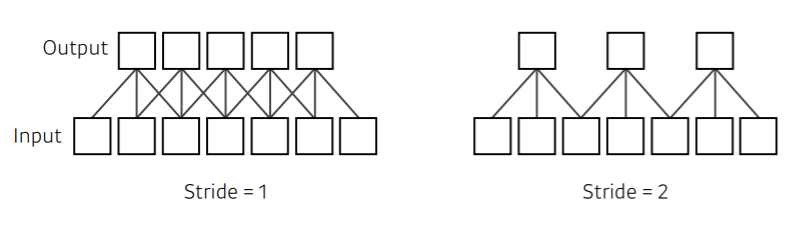
대부분의 3x3 convolution이나 5x5 convolution은 모두 stride 1을 말합니다.
stride가 1이라는 뜻은 매 픽셀마다 한 번 찍고, 1칸을 옮겨서 다음 픽셀을 찍는 것을 말하고,
stride가 2이라는 뜻은 매 픽셀마다 한 번 찍고, 2칸을 옮겨서 다음 픽셀을 찍는 것을 말합니다.
- Padding

feature의 가장자리를 0으로 채워서 convolution을 수행해 output feature의 크기를 늘려주는 것을 말합니다.
따라서 Stride와 Padding에 따라서 출력되는 output feature의 크기를 조정할 수 있습니다.

2) CNN의 Parameter 개수세기
CNN에서는 convolution하는 filter(kernel)가 parameter입니다.
(여기서 padding과 stride는 parameter 개수와 무관)
CNN에서 Parameter의 개수가 중요한 이유는
Parameter가 많으면 학습이 어렵고 generalization(일반화)이 떨어지기 때문입니다.
그리고 시간도 많이 걸린다는 문제점이 있죠.
그렇기 떄문에 CNN 모델을 설계할 때 parameter의 개수를 미리 계산해서 설계하는 것이 중요합니다.
아래의 모델의 경우 parameter 개수는 $3 \times 3 \times 128 \times 64 = 73,728$개 입니다.
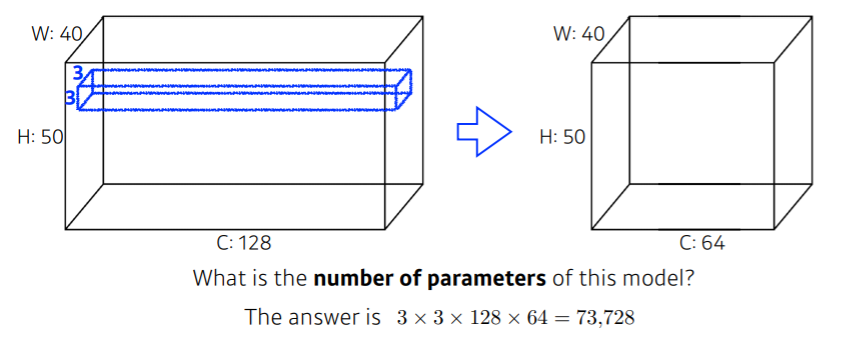
여기서 $\times 64$를 한 이유는 $3 \times 3 \times 128$을 하면 output feature의 channel이 1이 나오기 때문입니다. 따라서 channel을 늘리기 위해서는 output feature의 channel값을 곱해주어야 합니다.
-
예제) AlexNet의 Parameter 개수
첫 번째 convolution의 parameter의 개수는 35k개입니다.
이 때, *2를 한 이유는 사실 96채널짜리 feature map을 만들어야 하지만 당시에 GPU의 크기가 크지 않아서 filter을 두개로 나눠서 사용했기 때문이라고 합니다.
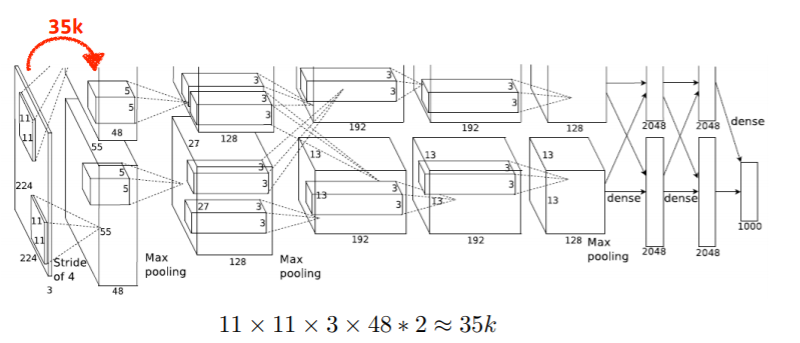

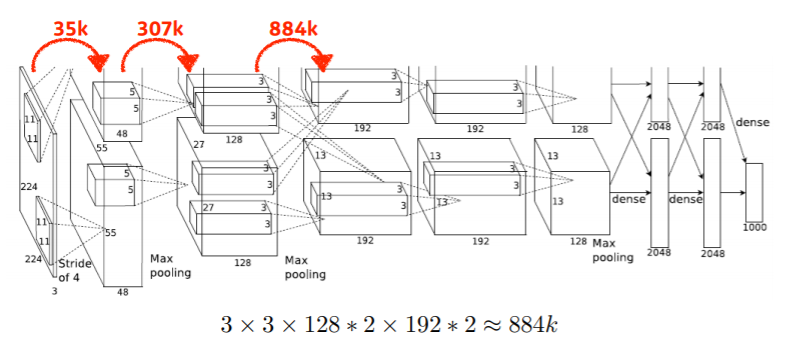
계속 계산하면 fully connected layer 부분을 마주하게 됩니다.
이 때 fully connected의 parameter 개수는 input parmeter 개수 * output parmeter 개수가 됩니다.
fully connected는 convolution보다 훨씬 큰 parameter의 개수를 가지고 있기 떄문에 요즘에는 fully connected layer를 줄이는 추세입니다.


3) $1 \times 1$ Convolution
$1 \times 1$ Convolution은 $1 \times 1$ filter을 사용해서 convolution하는 것을 뜻합니다.
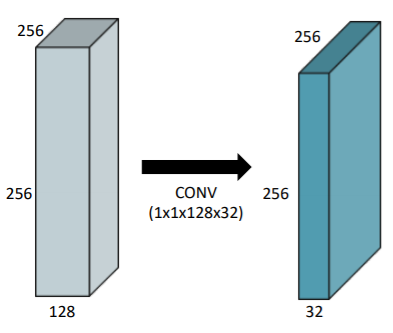
$1 \times 1$ Convolution을 사용하는 이유는 다음과 같습니다.
- Dimension reduction : 채널을 줄이는 역할 (128 channel -> 32 channel)
- Depth를 깊게 쌓으면서 Parameter 숫자를 줄일 수 있음 (e.g., bottleneck architecture)
3️⃣ CNN 알고리즘 종류
1) AlexNet (2012)

AlexNet 모델은 ILSVRC (ImageNet Large-Scale VisualRecognition Challenge)에서 우승한 딥러닝 모델입니다.
AlexNet은 $11 \times 11$ filter을 사용했는데, $11 \times 11$ filter을 사용하면 image level에서 볼 수 있는 영역은 커지지만 parameter 숫자가 엄청나게 늘어나게 됩니다.
AlexNet의 Key ideas는 다음과 같습니다.
- ReLU 활성함수 사용
- GPU 기반의 실행
- Local response (어떠한 입력공간에서 response가 많이 나오면 입력 몇 개를 죽이는 것) normalization, Overlapping pooling
- Data augment (한정적인 데이터들의 변형을 통해서 데이터 수를 늘리는 것)
- Dropout (neural network의 가중치 일부분을 0으로 바꾸는 것)
✅ ReLU Activation 함수란?

ReLU를 한마디로 정의하면 이렇습니다.
"Linear model에서 나온 값을 Non Linear하게 만들어줌"
즉, 선형 모델에서 나온 값들을 Scalar값들로 만들어주며, 딥러닝에서 사용함으로 선형 모델보다 많은 표현력을 가질 수 있게 됩니다.
ReLU의 특징은 아래와 같습니다.
- Linear model의 좋은 성질들을 잘 보존함
- Gradient descent 최적화하기 쉬움
- Genralization(일반화)가 좋음
- Vanishing gradient 문제를 해결
여기서 Vanishing gradient 문제는 다음과 같습니다.

다른 Activation 함수인 sigmoid 함수의 경우 중심값 0에서 많이 벗어나면 slope(sigmoid 함수의 기울기, gradient를 나타냄)는 0에 엄청나게 가까워집니다. 이 상황에서 gradient는 아주 작은 값이 나와서 gradient가 사라져 버리는 (vanishing gradient) 현상이 일어납니다.
ReLU는 0보다 작으면 0이 나오고, 0보다 크면 $x$가 나오기 때문에 vanishing gradient 현상을 극복할 수 있습니다.
2) VGGNet (2015)

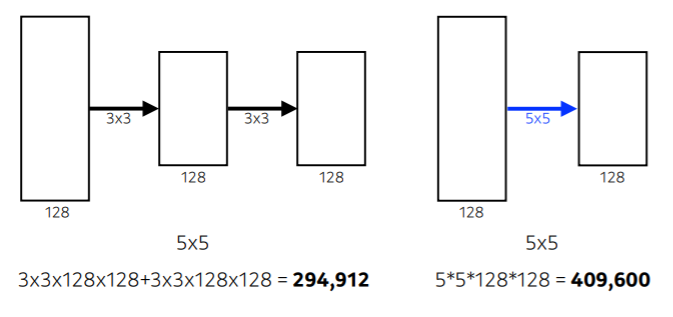
VGGNet의 가장 큰 특징은 $3 \times 3$ convolution을 이용해서 parameter 숫자를 줄인 것입니다.
✅ 왜 $3 \times 3$ convolution을 사용하나요?
$3 \times 3$ convolution을 사용해서 depth=2의 네트워크가 $5 \times 5$ convolution을 사용해서 depth=1의 네트워크보다 parameter 수가 적습니다.
3) GoogleNet (2015)

GoogleNet의 가장 큰 특징은 Inception blocks를 사용하는 것인데요. (위 사진의 검은색 네모칸)
Inception block들을 layer로 쌓아서 만들어서 네트워크 안의 네트워크(network in network) 구조를 가지고 있는 것이 특징입니다.
Inception block은 아래와 같은 구조를 가지고 있습니다.

Inception block은 1x1 convolution을 사용해서 parameter 숫자를 줄여줍니다.
block 안에서는 Input값이 여러개의 convolution으로 퍼졌다가 하나로 다시 합쳐지게 되는 과정을 거치게 됩니다.
convolution filter를 하기 전 1x1 convolution을 수행해서 parameter을 줄인 후, convolution을 해서 적은 parameter로 연산을 수행합니다.
1x1 convolution 연산을 하면 30%의 parameter을 줄일 수 있습니다.

GoogleNet을 사용하면 다른 CNN 알고리즘보다 훨씬 parameter가 적은 것을 알 수 있습니다.

4) ResNet (2015)
ResNet은 Deeper neural network가 train이 어려워지는 현상을 해결합니다.
Deeper neural network는 layer가 깊게 쌓인 네트워크를 의미하며, layer가 깊게 쌓이게 되면 training error와 test error가 같이 줄어들긴 하는데 56-layer가 20-layer의 성능을 따라잡지 못하는 현상이 발생합니다. 그래서 네트워크가 커지게 되면(layer가 늘어나게 되면) 학습에 어려움이 생기게 됩니다.

ResNet은 이러한 현상을 해결하기 위해 identity map(skip connection)을 사용합니다.
identity map(skip connection)은 $x$를 neural network 출력값 $f(x)$에 $x+f(x)$로 더해주는 방법입니다.

그렇게되면 이 convolution layer가 학습하게 되는 것은 $x$와 $x+f(x)$의 차이만 학습하게 됩니다.
아래 그래프를 보면 identity map을 사용했을 때 원래는 18 layer가 학습이 더 잘됐는데, ResNet을 사용할 경우 34 layer가 학습이 더 잘된 것을 볼 수 있습니다.

이후, ResNet에서는 identity map을 변형한 Projected Shortcut이 나오긴 했지만, 원래 idntity map인 Simple Shortcut을 일반적으로 많이 사용합니다.
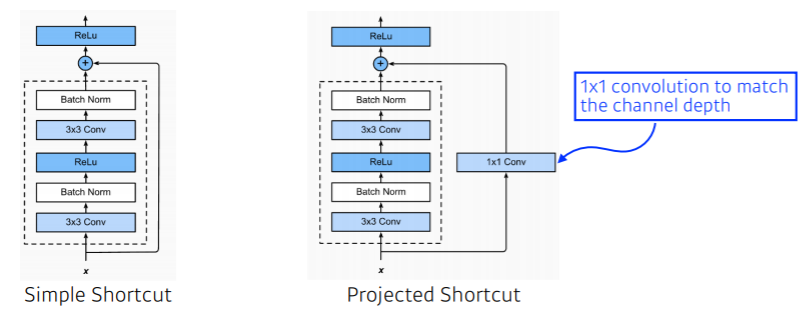
ResNet의 또다른 특징은 bottleneck architecture라고 해서 $1 \times 1$ convolution을 $3 \times 3$ convolution 사이에 넣어서 input 채널을 줄인 후, convolution을 수행하고, 다시 output 채널의 차원을 맞춰줍는 기능이 있습니다.

5) DenseNet (2017)
DenseNet은 ResNet과 같이 $x+f(X)$처럼 concatenation하는 방법이 아닌 addion(추가) 해주는 방법을 사용합니다.

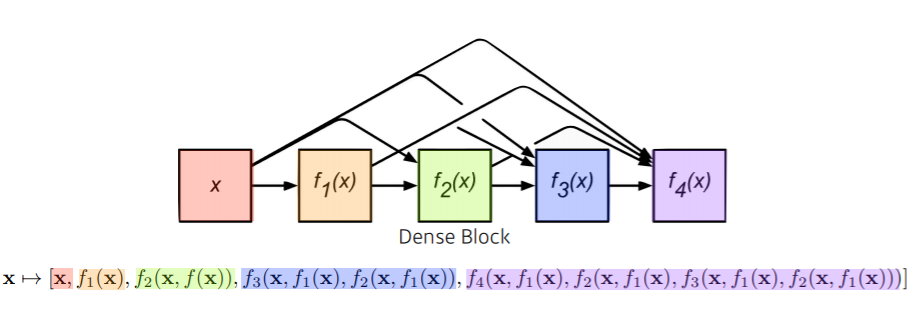
DenseNet은 어떤 input이 들어갔고 만들어졌는지 보기 편하지만 채널이 기하급수적으로 늘어나게 되고, 거기서 가해지는 convolution feature map의 크기가 커지면서 parameter의 크기가 커지는 문제점이 있습니다.
따라서 denseNet 중간 중간에 $1 \times 1$ convolution을 넣어서 파라미터를 줄여주는 부분이 필요합니다.

4️⃣ Semantic Segmentation
Semantic Segmentation은 어떤 이미지가 있을 때 이미지의 region마다 분류를 해서 검출하는 방법입니다.
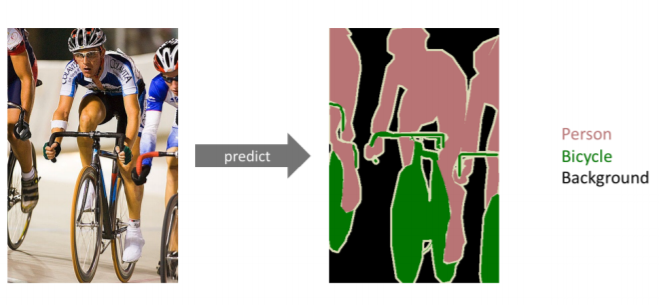
위 사진은 사진에서 Person과 Bicycle와 Background를 각각 분류해냈습니다.
Semantic Segmentation을 위해서는 Fully convolutional network와 Deconvolution 방법이 필요합니다.
1) Fully Convolutional Network (FCN)
원래 모형은 마지막에 fully connected layer (dense)가 있어 Label값으로 연결시킵니다.
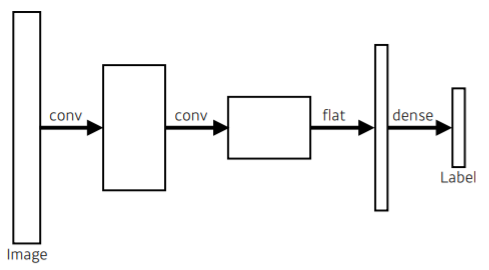
하지만 Fully convolutional network는 dense를 없애고 convolution을 통해 바로 Label값으로 연결시킵니다.

Fully Connected layer(FCL)과 Fully Convloution Network는 input과 output이 정확하게 일치합니다.
그리고 파라미터의 개수도 똑같습니다.

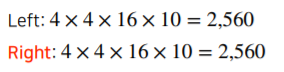
그렇다면 왜 convolutionalization을 할까요?
Convolutionalization을 하면 2가지 장점이 있습니다.
- input의 spatial dimension(공간 차원)의 독립성
(즉, 고정된 input 크기만 가지지 않아도됨) - 위치 정보 저장
(Dense를 사용하면 1차원으로 변경되면서 2차원 위치 정보를 잊어버리지만, FCN은 바로 label과 연결되므로 2차원 위치 정보를 가지고 있을 수 있음)
이 2가지 장점을 통해 분류만 할 수 있던 기존 네트워크가 semantic segmentation이 가능하게 해줍니다.
아래 그림 중 위에는 Fully Connected layer을 사용하면서 2차원 위치 정보가 1차원으로 모두 변경되었고, tabby cat이라는 분류 정보(class 정보)만 남게 됩니다.
하지만 Convolutionalization을 수행하면 dense를 거치치 않았기 때문에 2차원 위치 정보가 그대로 남아 있게 되고, 이를 기반으로 heatmap을 그릴 수 있게 됩니다. heatmap을 사용하면 이미지의 어떤 부분에 물체가 존재하는지 예측이 가능해집니다.
(아래 heatmap을 보듯이 물체가 존재할만한 곳에 높은 확률(색깔)로 표시됩니다.)
(이때, heatmap의 개수는 훈련된 class의 개수와 동일 즉, 각 heatmap은 하나의 class를 대표함)

주의해야할 점은 output의 dimension이 매우 줄어들다는 점입니다.
예를 들어, 원래 input이 100x100이였으면 output은 10x10 정도로 나오게 됩니다.
따라서 줄어져 있던 output dimensions을 늘려서 원래 output 크기로 복원해주어야 합니다.
이 과정을 Upsampling이라고 하며, deconvolution 방법을 사용합니다.

2) Deconvolution

Deconvolution은 convolution으로 함축된 값들을 복원하는 작업입니다.
직관적으로는 쉽지만 수식적으로 deconvolution을 표현하는 것은 아주 어렵습니다.
왜냐하면 convolution을 할 때 각각의 값들을 곱해서 하나로 합쳤기 때문에 반대로 그 값들을 복원하는 것은 힘든 일이기 때문이죠.
따라서 아래 사진처럼 convolution 연산을 하면 초록색 output feature map이 나왔다면,
deconvolution은 convolution된 feature map(파랑색)에 padding을 추가해서 만듭니다.
(filter는 convolution했던 filter와 같아야하며, padding을 할 때 무조건 feature map(파랑색)의 element가 한 개 이상 포함되어야함)

따라서 엄밀히 말하면 deconvolution은 convolution의 역은 아니지만 parameter의 입력과 출력 값의 역을 나타낼 수 있습니다.
5️⃣ Detection
1) R-CNN
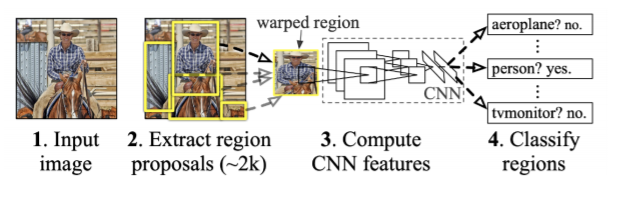
R-CNN은 input image에서 2000개의 일정한 region을 랜덤으로 뽑고, region 모두를 CNN에 넣어서 분류합니다.
(여기서 region은 크기와 비율이 달라도 CNN 입력에 들어갈 때는 warp이나 crop을 통해서 일정하게 만들어줌)
(분류는 SVM을 가지고 분류)
R-CNN은 2000개의 region을 모두 CNN에 넣어서 분류하기 때문에 엄청 오래 걸립니다.(brute-force 느낌)
2) SPPNet

기존의 CNN은 모두 이미지가 고정되어야 했습니다(FC에 고정된 길이의 입력 필요). 따라서 신경망에 통과시키기 위해서는 이미지를 고정된 크기로 crop하거나 비율을 조정(wrap)해야 했습니다. 하지만 이렇게 되면 물체 일부분이 잘리거나, 생김새가 달라지는 문제점이 생겼습니다.
SPPNet은 전체 image를 그대로 CNN에 통과시켜 feature map을 추출하고, 그 feature map에서 2000개의 물체 영역을 찾습니다. 이 때 각각의 RoI(관심 영역; Region of Interest)들은 각각의 크기와 비율이 다릅니다. SPP(spatial pyramid pooling)을 적용하여 고정된 크기의 feature tensor을 추출하고, FCL와 SVM을 통해 분류합니다.
✅ Spatial Pyramid Pooling을 무엇일까요?
Spaital Pyramid Pooling는 각기 다른 크기의 feature map에서 고정된 크기의 feature vector을 뽑아내는 방법입니다.
아래 그림에서는 4x4, 2x2, 1x1 3가지 영역을 제공하며, 각각을 하나의 피라미드라고 부릅니다.
피라미드 한 칸을 bin이라고 부르는데, 만약 64x64x256 크기의 feature map이 들어왔다면, 4x4 피라미드의 하나의 bin 크기는 16x16입니다. (64/4=16)
이때, 각 bin에서는 max pooling을 실시하고(가장 큰 값만 추출) 그 결과를 256-d vector에 집어넣습니다.
즉, 4x4 피라미드에서 한 bin의 크기가 16x16이면, 16x16에서 가장 큰 값을 pooling해서 16x256-d vector의 원소로 집어넣습니다.
이후, 이 3개의 vector(16x256-d, 4x256-d, 256-d)들을 concat하여 1-d vector을 생성합니다.
input에서 크기가 다른 feature map이 들어온다 하더라도 output은 항상 일정한 크기의 1-d vector가 추출되므로, fully-connected layer을 통해 분류가 가능해집니다.

SPPNet은 CNN을 한 번만 사용한 후, convolution feature map에 해당하는 위치의 tensor를 가지고 오는 과정만 region별로 계산하기 때문에 R-CNN에 비하면 빠릅니다.
3) Fast R-CNN

Fast R-CNN은 전체 input 이미지를 받고 CNN을 통해 convolution feature map을 추출합니다.
이후, feature map의 각각의 region에 대해서 ROI pooling을 통해 고정된 feature vector을 뽑습니다.
이후, softmax를 통해서 해당 RoI가 어떤 물체인지 classification합니다.
bounding box regressor는 bounding box를 어디로 움직이면 좋을지 (regressor)를 결정하는 역할을 합니다.
✅ RoI Pooling은 무엇일까요?

RoI Pooling은 추출된 전체 feature map에서 미리 정해놓은 $h * w$ 크기의 bounding box의 크기를 maxpooling하는 방법을 뜻합니다. 위에서 설명한 SPP의 Single level Pyramid만 사용해서 하는 방식으로, 똑같이 칸을 나눠(spliting) maxpooling을 하고, 이를 쫙 펼쳐서 feater vector를 추출하게 됩니다.
4) Faster R-CNN
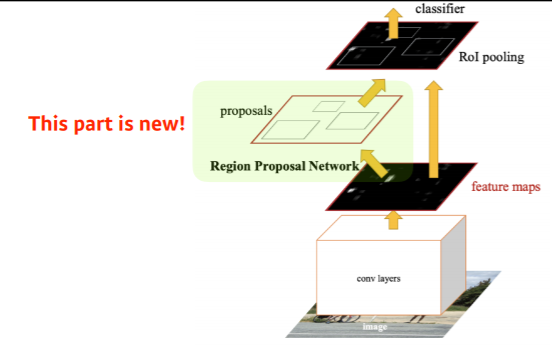
Faster R-CNN은 Region Proposal Network + Fast R-CNN의 합쳐서 만든 알고리즘입니다.
여기서 Region Proposal Network는 Region을 찾는 역할도 neural network 학습을 통해 찾는 방법을 뜻합니다.
하지만 전체 이미지에서 특정 영역에 bounding box로써의 의미가 있을지 없을지(물체가 있을지 없을지) 모르는 상황이기 때문에 anchor boxes라는 개념을 사용합니다.

anchor boxes는 미리 정해놓은 bounding box의 크기라고 생각하면 됩니다.
anchor box를 통해 "이 이미지 안에 어느정도 크기의 물체가 있을 것 같다"를 미리 알고 있게 되는 것이죠.
이러한 k개의 템플릿을 미리 만들어 놓고 neural network에 학습을 시켜 이 템플릿들이 얼마나 바뀔지에 대한 값을 찾아가는 과정입니다.

RPN(Region Proposal Network)는 feature map에서 추출한 Intermediate layer을 사용해서 classification과 regression 두 가지 작업을 진행합니다.
RPN에서 classification은 Fully convolution network를 사용해서 모든 영역을 돌아가면서 찾게 됩니다.
따라서 이미지에서 해당하는 물체가 있을지 없을지만 구분하는 역할을 합니다.
이때, classification을 수행하기 위해서는 intermediate layer를 $1 \times 1$ convolution * (2(오브젝트 인지 아닌지 나타내는 지표 수) x 9(앵커 개수)) 채널 수만큼 수행해줘서, 그 결과로 H x W x 18 크기의 feature map을 얻습니다.
RPN에서 regression은 bounding box 정보를 업데이트하는 것을 뜻합니다.
bounding box의 (x,y,w,h) 좌표를 다시 조정해줍니다.
이때, regression을 수행하기 위해서는 intermediate layer를 $1 \times 1$ convolution * (4(bounding box의 x,y,w,h) x 9(앵커 개수)) 채널 수만큼 수행해줘서, 그 결과로 H x W x 36 크기의 feature map을 얻습니다.
따라서 RPN에서 나온 output layer 크기는 H x W x (9 * 2 + 9 * 4)채널 크기로 나오게 됩니다.

숫자가 의미하는 각각의 의미는 아래와 같습니다.
- 9
- anchor box가 3개가 있음 (128*128, 256*256, 512*512) = 3개
- ratios도 정함 (1:1, 1:2, 2:1) = 3개
따라서 3*3 = 9개의 anchor box 중에서 하나를 정하게 됩니다.
- 4
bounding box에서 width, height, x offset, y offset을 얼마나 조정할 지 = 4 개
- 2
해당 bounding box가 쓸모가 있는지 없는지(yes or no) = 2개
5) YOLO

YOLO는 faster R-CNN보다 훨씬 빠릅니다.
빠른 이유는 region proposal network를 통해서 나온 region들을 가지고 분류를 하는 것이 아닌 이미지 한장 자체를 가지고 CNN을 수행하기 때문인데요. 즉, bounding box를 따로 뽑는 과정이 없습니다.
대신, 이미지가 S x S grid로 나누게 됩니다.
S x S grid로 나눈 이미지 안에서 "찾고 싶은 물체의 center"가 해당 grid 안에 들어가면 그 grid cell이 해당 물체에 대한 bounding cell과 해당 물체가 무엇인지 같이 예측(classification)합니다.

B=5로 주면 5개의 bounding box를 예측하게 됩니다.
그 bounding box의 (x/y/w/h)를 찾아주게 되고 bouding box가 쓸모가 있는지 없는지를 판단합니다.
그리고 그 grid cell에 있는 물체가 어떤 분류에 속하는지를 예측하게 됩니다.
faster R-CNN은 예측되는 위치를 찾고 그 후에 neural network로 분류를 정했다면 YOLO는 그 두 개를 동시에 수행합니다.
이 YOLO를 tensor로 표현하게되면 S x S x (B * 5 +C) 채널 크기입니다.
- S x S : gird의 개수
- B * 5 : 5개의 bounding box에 대한 (x,y,w,h)의 값
- C : class의 수
'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [14-1] Transformer 이해하기 (1) (0) | 2021.02.04 |
|---|---|
| [14] RNN, LSTM, GRU 정리 (1) (0) | 2021.02.04 |
| [12-1] Convolution 연산 이해하기 (0) | 2021.02.03 |
| [12] 최적화 (Optimization) 종류와 용어들 (0) | 2021.02.02 |
| [11-2] PyTorch 기본문법 (0) | 2021.02.02 |



