
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- subplot
- groupby
- unstack
- 최대가능도 추정법
- Comparisons
- 정규분포 MLE
- 표집분포
- ndarray
- type hints
- linalg
- Array operations
- Numpy data I/O
- dtype
- scatter
- 딥러닝
- Numpy
- Python 유래
- 부스트캠프 AI테크
- pivot table
- Python 특징
- 가능도
- Python
- VSCode
- namedtuple
- Operation function
- BOXPLOT
- seaborn
- 카테고리분포 MLE
- python 문법
- boolean & fancy index
- Today
- Total
또르르's 개발 Story
[31-1] Annotation data efficient learning 본문
"Annotation data efficient learning"
즉, 적은 수의 데이터로 효율적으로 학습하는 방법에는 여러 가지 방법이 있습니다.
Data augmentation, Knowledge distillation, Transfer learning, Self-Training에 대해서 알아봅시다.
1️⃣ Data augmentation
Data augmentation은 현재 가지고 있는 데이터를 가지고 Brightness, Rotate, Crop을 통해 데이터를 풍부하게 만들어주는 기법입니다.
1) Brigthness
밝기는 img에 일정값을 더해주면 됩니다. (다만, 0~255 사이)

2) 기하학적 변환
기하학적 변환은 OpenCV를 통해 쉽게 변환할 수 있습니다.

3) Crop
Crop은 Window slicing를 통해 변환이 가능합니다.

4) Affine transformation
Affine transformation은 변환 전 후에도 선(line), 길이의 비율(length ratio), 평행(parallelism)이 유지되는 이미지 변환을 말합니다.
아래 그림과 같이 직사각형이 마름모로 Affine transformation을 수행하면서
line이 유지, length ratio도 유지, parallelism도 유지(선들의 평행, 즉, 만나지 않음)되는 것을 알 수 있습니다.
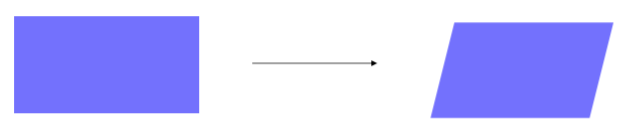
Affine transformation은 OpenCV를 통해 나타날 수 있습니다.
이때, 대응점(pts1, pts2; 빨간색 점)을 만들어서 input과 output의 기준을 잡게 되고, getAffineTransform에 넣어주면 점에 대응하는 행렬이 반환되게 됩니다.

5) CutMix
CutMix는 두 개의 img를 cut 하고 mix 하는 방법입니다. 데이터를 합성해서 사용하는 방법입니다.

이때, img만 합성하는 것이 아니라 label도 그 비율을 합성해서 넣어주어야 합니다.

CutMix를 사용하면 의미 있는 성능 향상이 일어나면서, 동시에 물체의 위치를 더 정교하게 catch 할 수 있게끔 학습되게 됩니다.
6) RandAugment
그렇다면 이러한 Augmentation을 한 번씩만 사용해야 할까요?
다양한 Augmentation을 만들기 위해서는 여러 가지 Augmentation을 조합해서 사용해야 합니다.
즉, 여러가지 가능한 영상처리 기법을 조합해서 전혀 다른 데이터를 생성할 수 있습니다.
그렇다면 어떤 기법을 어떻게 조합해야 좋은 성능의 데이터들을 뽑아낼 수 있을까요?
데이터를 쉽게 뽑아낼 수 있는 방법 중 하나가 RandAugmentation입니다.
RandAugment는 어떤 Augment가 성능이 좋은지 알 수 없으니, Random 하게 가져다 쓰고 가장 좋은 성능의 augment를 산출하는 기법입니다.

RandAugment에서 조정되는 parameter는 두 개입니다.
- 어떤 augmentation을 적용할 것인가?
- 해당 augmentation의 강도는 얼마나 줄 것인가?
또한, 이러한 augmenation의 기법들의 sequence를 Policy라고 합니다.
Policy는 {N augmentations to apply}로 N개의 augmentation을 적용할 수 있습니다.
Policy의 parameter는 2 x N개로 구성됩니다.
2️⃣ Leveraging pre-trained information
1) transfer learning
Transfer Learning이란 기존에 미리 학습시켜놓은 사전 지식을 활용해서 새로운 task에 적은 노력으로도 높은 성능에 도달하는 기법입니다. 즉, 한 데이터셋에서 배운 지식을 다른 데이터셋에서 활용하는 기법이라 말할 수 있습니다.
아래는 미리 학습한 Model입니다.

여기서 Fully Connected layer를 없애고 새로운 FC Layer을 집어넣습니다. 이렇게 하면 새로운 task에 대해 사용할 수 있습니다. Convolution Layers 부분은 기존에 학습된 내용들을 그대로 가지고 있습니다.(Freeze Weight)

또한, 다음과 같이 Fully Connected Layer에서는 높은 learning rate를 갖고, Convolution Layer는 낮은 learning rate를 갖게 만들어서 학습할 수도 있습니다. 이 방법은 위 방법보다는 학습이 많이 필요해 데이터셋은 더 많이 필요하지만, 성능은 더 좋아집니다.

2) Knowledge distillation (Teacher-student learning)
Knowledge distillation (Teacher-student learning)은 큰 모델에서 작은 모델로 지식(Knowledge)을 전달함으로써 사용됩니다.

Teacher-student 모델은 Model Compression (모델 압축)에 사용할 수 있습니다.
최근에는, teacher model에서 생성된 출력을 unlabeled 된 데이터의 pseudo-label (가짜 레이블)로 자동 생성하는 용도로 사용되기도 합니다. 가짜 레이블로 자동 생성을 해 더 큰 student network를 사용할 때도 regularization 역할로 사용할 수 있습니다.
(1) 기본적인 Knowledge distillation의 구조
Pre-trained 된 Teacher Model과 아직 학습되지 않은 Student Model을 initialization 합니다.
이때, Student Model은 Teacher Model보다 더 작은 Model을 사용하는 것이 일반적입니다.

이후, "Teacher Model에서 나온 Output"과 "Student Model에서 나온 Output"을 KL div. Loss를 통해 측정을 하고, Student만 학습을 합니다. 즉, KL div는 두 개의 output의 distribution을 비슷하게 만드는 역할을 합니다.
Student model은 Teacher Model의 행동을 비슷하게 따라 하는 학습법이며, 이 과정 중에 Label을 전혀 사용하지 않았기 때문에 unsupervised Learning으로 볼 수도 있습니다. 그렇기 때문에 Student model에서는 똑같은 Input X를 사용하는 것이 아닌 임의의 데이터셋 사용이 가능합니다.
(2) 확장된 Knowledge distillation의 구조
확장된 Knowledge distillation 구조는 다음과 같습니다.
- Ground Truth Y : 실제 정답 Label
- Student Loss : Ground Truth Label을 사용한 Loss
- Distillation Loss : Teacher과 Student의 predict의 Loss

여기서 Soft Prediction은 Soft Label로 표현된 Prediction을 뜻하며, softmax를 통과한 0~1 사이 값들이 나오게 됩니다.
각각의 값들에 대한 경향성이 Knowledge를 나타낸다고 가정을 해서 어떤 class에 더 가까운지 확인할 수 있습니다.
(여기서 Hard label은 one-hot vector를 나타내며, 0과 1로만 표현됩니다.)

따라서 Soft prediction은 Softmax를 통해 나오게 됩니다.
여기서 중요한 점은 Softmax(T=t), Softmax(T=1) 개념입니다.

T는 temperature을 나타내며, softmax를 계산하면서 입력을 큰 값 T로 나눠줍니다. 그렇게 되면 softmax를 통과한 결과값이 스무스하게 나오게 됩니다. (T를 사용하지 않으면 극단적인 결과값이 나올 수 있습니다.)
(결과가 스무스하게 나온다는 뜻은 극단적으로 0에 가까운 값, 1에 가까운 값으로 나눠져 보여지는 vector가 아닌, 고르게 분포되어서 나오는 현상을 의미합니다.)

이번에는 Distillation Loss와 Student Loss의 차이를 알아봅시다.

- Distillation Loss
- KLdiv(Soft label, Soft prediction)
- Loss는 teacher network와 student network의 prediction 결과의 차이를 측정
- teacher network가 무엇을 알고 있는지 따라 하게 만드는 것 - Student Loss
- CrossEntropy(Hard label, Soft prediction)
Ground Truth(Hard label)를 사용하기 때문에 CroosEntropy를 그대로 사용
- Loss는 student network가 prediction 한 결과와 true label이 일치하도록 만드는 것
- 실제 정답을 찾는 것
Backpropagation은 Student Model만 훈련하게 됩니다.

3️⃣ Leveraging unlabeled dataset for training
1) Semi-supervised learning
Semi-supervised learning은 다음 문장으로 표현할 수 있습니다.
Semi-supervised learning : Unsupervised (Nolabel) + Fully Supervised (fully labeled)
즉, Label이 없는 dataset을 사용한 비지도 학습 + Label이 있는 dataset을 사용한 지도 학습의 결합입니다.
Semi-supervised learning은 다음과 같이 진행됩니다.
- Labeled 된 dataset을 가지고 Model을 학습시킵니다.
- Unlabeled 된 dataset에 대해 학습된 Model로 label들을 예측해서 Pseudo-labeled(가짜 label) dataset을 만들어줍니다.
- 다시 Labeled 된 dataset과 Pseudo-labled 된 dataset을 가지고 Model을 학습시킵니다.

2) Self-training
Self-training은 Augmentation + Teacher-Student networks + semi-supervised learning를 합친 방법입니다.
2019년 ImageNet classification에서 가장 높은 성능을 보여줬고, 성능이 다른 기법보다 압도적이었습니다.
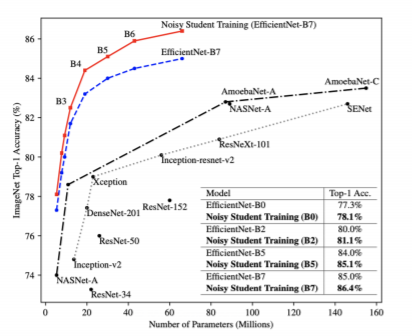
Self-training의 방법은 다음과 같습니다.
- ImageNet dataset에 있는 1M개 data를 사용해서 Teacher network를 학습시킵니다.
- 300M 개의 unlabeled된 data를 학습된 Teacher network를 사용해서 300M개의 Pseudo-labeled data를 만들어줍니다.
- ImageNet dataset에 있는 1M개 data와 300M개의 Pseudo-labeled data를 합쳐서 Student network를 학습시킵니다. 이때, RandAugment를 사용해서 더 방대한 양의 데이터를 학습시키게 됩니다.
- Student network의 학습이 완료되면 기존의 Teacher network를 없애고, Student network를 새로운 Teacher network로 만들어버립니다. 그런 후, 기존 Student Model 자리에 새로운 Student Model (New Student Model)을 집어넣습니다.
- 위 과정을 다시 반복합니다.

여기서 중요한 점은 기존 Teacher-Student Model에서는 Model의 크기가 Teacher Model > Student Model이지만,
Self-training에서는 Model의 크기가 Teacher Model < Student Model, 즉, Sutdent Model의 크기가 조금씩 커집니다.

'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [32-1] Semantic Segmentation (0) | 2021.03.09 |
|---|---|
| [32] Image Classification (2) (0) | 2021.03.09 |
| [31] Image Classification (1) (0) | 2021.03.08 |
| [30] 퀀트 트레이딩 (Quant Trading) (0) | 2021.03.05 |
| [29-1] Creative Commons License (CCL) 분류 (0) | 2021.03.04 |


