
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pivot table
- linalg
- python 문법
- 최대가능도 추정법
- namedtuple
- groupby
- Comparisons
- 표집분포
- 부스트캠프 AI테크
- Python
- Python 유래
- unstack
- ndarray
- 가능도
- subplot
- Numpy
- dtype
- Array operations
- type hints
- 딥러닝
- Numpy data I/O
- 정규분포 MLE
- Python 특징
- VSCode
- BOXPLOT
- scatter
- Operation function
- seaborn
- 카테고리분포 MLE
- boolean & fancy index
- Today
- Total
또르르's 개발 Story
[32] Image Classification (2) 본문
[31] Image Classification에 이어서 작성합니다.
[31] Image Classification (1)
1️⃣ K Nearest Neighbors 세상에 있는 모든 데이터를 다 저장하고 있다면 Image Classification을 어떻게 수행하면 될까요? 바로 간단한 K Nearest Neighbors (K-NN) 방법을 사용하면 됩니다. K Nearest Neighbo..
dororo21.tistory.com
1️⃣ Going deeper
네트워크 깊이가 깊어질수록 다음과 같은 장점이 있습니다.
- Lager receptive fields (즉, 더 많은 픽셀들을 참조하기 때문에)
- More capacity and non-linearity
하지만 네트워크를 깊이 쌓을수록 아래와 같은 문제가 생겨납니다.
- Gradient vanishing / exploding
- Computationally complex (계산 복잡도)
Overfitting problemDegradation problem (Layer가 깊어질수록 학습이 안 되는 현상)
2️⃣ GoogLeNet (2015)
GoogLeNet은 Inception module을 가지고 있습니다.
Inception module은 다양한 filter를 사용해 convolution하고, 다시 concatenation 하는 과정을 가집니다. 이때, 1x1 convolutions (bottleneck layer)을 사용해 channel의 수를 줄입니다.

다음은 GoogLeNet의 Architecture입니다.
- Stem network : vanilla convolution networks

- Stacked inception modules
위에서 설명한 inception module들을 여러 층으로 쌓아줍니다.
Bottleneck을 사용해서 여러층으로 쌓아도 학습이 잘 됩니다.

- Auxiliary classifiers
Backpropagation을 하면서 뒷부분에서는 훈련이 잘되지만 앞쪽으로 갈수록 gradient vanishing 문제가 생기는 것을 알 수 있습니다. 이 문제를 해결하기 위해 gradient를 중간중간에 주사기처럼 꽂아주는 방법을 사용합니다. 여기서의 Classifier(흰색 블록)는 맨 마지막에 있는 Classifier(흰색 블록)와 동일합니다.

Auxiliary Classifier는 학습 중에만 사용을 하고 forward 과정에는 사용하지 않습니다. 학습할 때 최종 Classifier를 가지고 와 Softmax0 부분에 넣어주고 학습을 시킵니다.

3️⃣ ResNet (2016)
ResNet은 layer를 151층까지 쌓는 것이 가능한 Network이며, layer을 깊게 쌓이면 생기는 degradation problem을 해결한 network입니다.
1) Degradation problem
원래는 Overfitting 문제라고 생각했지만, Overfitting은 56-layer가 20-layer보다 training error가 더 낮아야 합니다.
하지만 아래 그림처럼 training error에서도 56-layer의 error가 20-layer보다 높다는 것을 알 수 있습니다.
따라서 이 문제를 Degradation Problem이라고 정의했는데, 최적화(Optimization) 문제로 56-layer network가 학습이 잘 안된 것이다라는 결론입니다.

2) Residual
일반 layer에서는 $x$에서 $H(x)$를 학습하는 것은 복잡하기 때문에 더 어렵습니다.
따라서 Residual block에서는 identity 외 잔여부분 $F(x)$만 모델링을 해서 학습을 하게끔 하면 학습의 부담을 줄일 수 있습니다. 그렇게 하면 학습해야 하는 대상이 "Residual" 부분 $F(x)$만 남기 때문에 분할정복이 가능해집니다.

결론적으로 identity 부분 $x$만 남겨두고 Residual 부분 $F(x)$만 학습한 후, $x + F(x)$를 통해 최종값 $H(x)$을 구할 수 있습니다.
Backpropagation을 수행할 때는 기본 경로와 identity 두 개의 방향으로 gradient를 흘려줍니다. identity 방향으로 gradient를 흘려줌으로써 gradient vanishing 문제를 해결할 수 있습니다. 기본 경로에서 gradient가 vanishing이 되더라도, identity에서는 gradient를 보존할 수 있습니다.

✅ 그렇다면 이러한 Residual Connection, Shortcut Connection이 왜 성능이 좋을까요?
한 분석논문에 따르면 $2^{n}$의 경우의 수로 gradient가 지나갈 수 있는 input, output path가 생성된다고 합니다.
즉, 아래 그림과 같이 $f1, f2, f3$이 있을 때, 아래와 같이 $2^{3} = 8$개의 path가 생성되게 됩니다.

Residual은 다양한 path를 가지고 있기 때문에 아주 복잡한 문제들도 학습해나갈 수 있습니다.
3) Overall architecture
처음에는 7 x 7 layer로 시작합니다.
그리고 He initalization 즉, ResNet에 적합한 initialization으로 시작합니다.

여기서 He initialization을 사용하는 이유는 identity connection, 즉, 덧셈이 있는데 일반적인 initialization을 사용하게 되면 계속해서 큰 값이 더해지게 됩니다. 이런 부분을 고려해서 Resdiual에 적합한 initialization 방법을 사용했습니다.
다음으로는 Residual Block을 쌓습니다. residual block은 2개의 3 x 3 conv layer을 사용합니다.

여기서 중요한 점은 색깔별로 블록이 나눠져 있습니다.
한 블록을 넘어갈때마다 공간 축은 1/2으로 줄면서(Stride = 2), channel 수는 2배 (outchannel)씩 늘어나게끔 설정되어 있습니다.

Pytorch에서는 Resnet 18-layer를 사용할 때 다음과 같이 코드를 작성할 수 있습니다.




4️⃣ Beyond ResNets
1) DenseNet
DenseNet에서는 ResNet 하고 비슷하지만, Dense block에서 channel axis로 concatenation을 하게 만들었습니다.

따라서 Dense block은 바로 직전의 입력만 넣어주는 것뿐 아니라 훨씬 이전의 정보도 넘겨주게 됩니다.
Dense block은 이전의 출력들을 모두 이어주는 설계로 되어있습니다. 따라서 상위 layer에서도 하위 layer에서의 feature들을 재참조해서 재활용할 수 있는 특징을 가집니다. 이렇게 함으로써 더 복잡한 Mapping의 학습이 용이하도록 도와주는 역할을 합니다.

덧셈은 정보를 합쳐서 하나의 정보로 만들어버리지만, concat을 하게되면 정보를 이어 붙여서 상위 layer에서도 하위 layer의 정보를 재활용할 수 있습니다.
2) SENet
SENet은 Depth를 높이거나 Connection을 새로 하는 방법이 아니라, 현재 주어진 Activation의 관계가 더 명확해질 수 있도록 채널 간의 관계를 모델링하고, 중요한 feature들은 Attention할 수 있도록 만든 Model입니다.

이때, Attention을 생성하는 방법은 Squeeze와 Excitation으로 나눠지게 되는데,
- Squeeze : global average pooling을 통해서 각 channel의 공간 정보를 없애고, 각 채널의 분포를 보여줍니다.
아래 그림과 같이 $F_{sq}$를 수행하면 H x W x C 크기가 1 x 1 x C 크기로 변경되고, channel의 평균 정보들만 포함하게 됩니다.
- Excitation : FC layer 하나를 통해서 Channel 간의 연관성을 고려합니다.
1 x 1 x C vector가 W를 거쳐서 channel 간의 연관성을 고려해서 new weighting 하는 Attention Score를 생성합니다.

따라서 input Attention (H x W x C)와 방금 구한 Weight (색깔있는 1 x 1 x C)를 같이 활용해서 Activation을 Rescaling 합니다. 중요도가 낮다고 생각되는 것들은 값을 낮추고, 중요도가 높다고 생각되는 것들은 더욱 강하게 만듭니다.
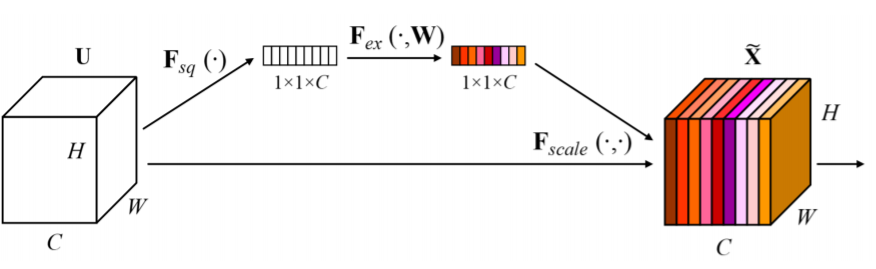
즉, input Attention을 똑같은 weight로 보는 것이 아닌 weighting을 통해 중요한 것은 강조하고(빨강, 높은 숫자), 중요하지 않은 값(파스텔값, 0에 가까움)은 없애버립니다.
3) EfficientNet
EfficientNet이 나오기 전까지 network의 성능을 높이기 위한 방법은 아래 (b), (c), (d) 3가지 중 하나로 대부분 귀결이 되었습니다.
하지만 EfficientNet은 새로운(다른) 설계방식을 제안했습니다.

따라서 (a) baseline이 주어졌다고 했을 때, 네트워크의 성능을 높이는 방법은 다음과 같았습니다.
- Width Scaling : channel 축을 늘리는 방법입니다.
즉, CNN에서는 서로 다른 Convolution filter를 사용한 경우입니다.
ex) goolgeNet, DenseNet

- depth scaling : layer를 깊게 쌓는 방법입니다.
ex) ResNet

- resolution scaling : input image의 resolution을 큰 것을 넣어주는 방법입니다.

이렇게 (b), (c), (d) 3가지 정도의 main factor들이 있는데, 이 3가지의 성능 증가폭이 다릅니다.
예를들어, (d) resolution scaling의 경우는 성능이 초반부터 급격하게 증가합니다.
따라서 이 3가지의 main factor들을 조합한 것이 (e) compound scaling이며, EfficientNet의 main idea입니다.

EfficientNet의 성능표를 보면 다른 network보다 성능이 빠르게 증가하는 것을 볼 수 있습니다.

4) Deformable convolution
사람과 동물은 팔 다리처럼 상대적인 위치에 따라 바뀔 수가 있는데, 이런 Deformable 한 부분을 고려한 Convolution이 필요해서 제안된 Network입니다.
기본적으로 3 x 3 Convolution filter가 존재하고, 거기에 2D Offsets Map을 추정하기 위한 branch가 따로 결합되어 있습니다. 따라서 Convolution layer를 통해서 input이 들어왔을 때 Offset field를 생성하게 되고, 이 offsets field에 따라서 각각의 Weight들을 옆으로 벌려줍니다(input feature map의 파란색 직사각형들). 그러면 이 위치에 맞게끔 irregular(불규칙)한 sampling을 통해서 Activation과 irregular 한 filter를 내적해서 한 가지 값(output feature map의 파란색 직사각형)으로 도출하게 됩니다. 이것이 즉, irregular한 shape을 가진 convolution을 하는 방법입니다.

아래 그림처럼 일반 convolution은 일정한 shape의 직사각형에서 receptive field를 갖지만,
Deformable convolution에서는 불규칙한 shape 즉, 일정한 물체 안에 포진되어있는 점들을 가지고 receptive field을 결정합니다.

5️⃣ Summary of image classification
VGGNet은 다른 최신 network보다 parameter수가 압도적으로 많기 때문에 메모리적으로 부담이 큽니다.

GoogleNet은 Auxiliary Classifier 때문에 학습과 이용에 복잡한 요소들이 있습니다.
따라서 좀더 사용이 간편한 VGGNet이나 ResNet을 많이 사용합니다.
'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [33] Object detection (0) | 2021.03.10 |
|---|---|
| [32-1] Semantic Segmentation (0) | 2021.03.09 |
| [31-1] Annotation data efficient learning (0) | 2021.03.08 |
| [31] Image Classification (1) (0) | 2021.03.08 |
| [30] 퀀트 트레이딩 (Quant Trading) (0) | 2021.03.05 |



