
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- python 문법
- VSCode
- Array operations
- seaborn
- Numpy data I/O
- BOXPLOT
- type hints
- boolean & fancy index
- Numpy
- 최대가능도 추정법
- pivot table
- ndarray
- 카테고리분포 MLE
- scatter
- Python 유래
- Python
- unstack
- Python 특징
- 정규분포 MLE
- 부스트캠프 AI테크
- 표집분포
- dtype
- 딥러닝
- namedtuple
- groupby
- 가능도
- linalg
- subplot
- Operation function
- Comparisons
- Today
- Total
또르르's 개발 Story
[Stage 2 - 02] 한국어 전처리 / 토크나이징 본문
1️⃣ Goal
[BaseLine 작성] (추가 : 4/12, 새로운 Baseline code)- [Data Processing]
- Exploratory Data Analysis (추가 : 4/12, 기간 : 4/12 ~ )
- Cross-validation 사용 (추가 : 4/12)
- 데이터 불균형 해소 (추가 : 4/12)
- 한국어 전처리 (추가 : 4/13, 기간 : 4/13 ~ )
- 새로운 tokenizer 사용 (추가 : 4/12, 기간 : 4/13 ~ )
- 형태소 분류기 -> BERT wordpiece (추가 : 4/13) - [Model]
- BERT 모델 사용 (추가 : 4/12)
- GPT 모델 사용 (추가 : 4/12)
- ELECTRA 모델 사용 (추가 : 4/12)
- KoBERT 모델 사용 (추가 : 4/12) - [Training]
- 앙상블 시도 (추가 : 4/12)
- Hyperparameter 변경 (추가 : 4/12)
- Learning Schedular 사용 (추가 : 4/12)
- 좋은 위치에서 Checkpoint 만들기 (추가 : 4/12)
- NNI (Auto ML) 사용 (추가 : 4/12) - [Deploy]
- Python 모듈화 (추가 : 4/12)
2️⃣ Learning
[Stage 2 - 이론] 한국어 토큰화
1️⃣ 자연어 처리 단계 Task 설계 필요 데이터 수집 통계학적 분석 - Token 개수 -> 아웃라이어 제거 - 빈도 확인 -> 사전(dictionary) 정읟 전처리 - 개행 문자 / 특수 문자 제거 - 공백 제거 - 중복 표현
dororo21.tistory.com
[임베딩 측정 방법]
- WordSim353 : annotator를 사용해 단어의 유사성과 관련성을 비교합니다.
h tiger cat 7.35
i tiger tiger 10.00
t book paper 7.46
M computer keyboard 7.62
t computer internet 7.58
S plane car 5.77
S train car 6.31
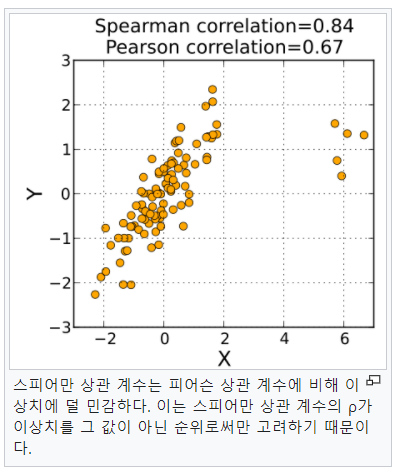
- Spearman's correlation : 두 변수 의 순위 사이의 통계적 의존성을 측정하는 비모수적인 척도
즉, 순위가 매겨진 변수 간의 피어슨 상관계수로 정의됩니다.
피어슨 상관계수는 다음과 같이 정의됩니다.

이 피어슨 상관계수를 순위로 매긴 것이 Spearman's correlation입니다.
- Analogy test : 두 단어의 관계를 유추하는 테스트
A:B의 관계가 주어지고, C가 주어졌을 때 D를 유추하는 방법

3️⃣ Main Task
1) 한국어 전처리
1-1) 뉴스 기사 크롤링 (newparaper3k)
newspaper3k는 url 정보만 입력하면 텍스트를 추출해줍니다.
!pip install newspaper3k
newspapaer 라이브러리는 한국어 크롤링도 지원해줍니다.
import newspaper
>>> newspaper.languages()Your available languages are:
input code full name
bg Bulgarian
hu Hungarian
ro Romanian
ar Arabic
et Estonian
no Norwegian
ko Korean
nb Norwegian (Bokmål)
be Belarusian
sw Swahili
sv Swedish
vi Vietnamese
hr Croatian
ru Russian
el Greek
zh Chinese
fr French
fa Persian
fi Finnish
nl Dutch
ja Japanese
hi Hindi
it Italian
sr Serbian
de German
es Spanish
pl Polish
id Indonesian
en English
tr Turkish
mk Macedonian
da Danish
sl Slovenian
uk Ukrainian
he Hebrew
pt Portuguese
뉴스 크롤링은 다음과 같습니다.
from newspaper import Article
news_url = [NEWS_URL] # news url 적기
article = Article(news_url, language='ko')article.download()
article.parse()
>>> print('title:', article.title)
>>> print('context:', article.text)
1-2) 전처리
이후 다음과 같은 전처리를 수행할 수 있습니다.
- HTML 태그 제거
regex를 사용해 HTML 태그를 제거할 수 있습니다.
re.sub(r"<[^>]+>\s+(?=<)|<[^>]+>", "", text).strip()
- 문장 분리
한국어 문장분리기 중 kss 라이브러리를 사용해서 문장을 분리할 수 있습니다.
!pip install kssimport ksssplited_sent = kss.split_sentences(sent)
- Email 제거
regex를 통해 Email를 제거할 수 있습니다.
text = re.sub(r"[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+", "", text).strip()
- Hashtag 제거
regex를 통해 hashtag를 제거할 수 있습니다.
text = re.sub(r"#\S+", "", text).strip()
- Mention(@) 제거
regex를 통해 유저에 대한 멘션(@)을 제거할 수 있습니다.
text = re.sub(r"@\w+", "", text).strip()
- URL 제거
regex를 통해 본문에 포함된 URL을 제거할 수 있습니다.
text = re.sub(r"(http|https)?:\/\/\S+\b|www\.(\w+\.)+\S*", "", text).strip()
text = re.sub(r"pic\.(\w+\.)+\S*", "", text).strip()
- bad char 제거
regex를 통해 문제가 나타날 수 있는 문자들을 제거합니다.
text = re.sub(r"[\+á?\xc3\xa1]", "", text)
- 언론 정보 제거
regex를 통해 언론사, 언론 정보를 제거합니다.
- 저작권 관련 텍스트 제거
regex를 통해 저작권 관련 텍스트를 제거합니다.
re_patterns = [
r"\<저작권자(\(c\)|ⓒ|©|\(Copyright\)|(\(c\))|(\(C\))).+?\>",
r"저작권자\(c\)|ⓒ|©|(Copyright)|(\(c\))|(\(C\))"
]
- 이미지 label 제거
regex를 통해 뉴스에 포함된 이미지 label을 제거합니다.
text = re.sub(r"\(출처 ?= ?.+\) |\(사진 ?= ?.+\) |\(자료 ?= ?.+\)| \(자료사진\) |사진=.+기자 ", "", text).strip()
- 반복된 문자 줄이기
soynlp를 사용해서 중복된 문자를 줄입니다.
!pip install soynlpfrom soynlp.normalizer import *
>>> print(repeat_normalize('미히히히히히히히힛', num_repeats=2)) # 반복되는 횟수
미히히힛
- 특수문자 제거
특수문자 mapping을 사용해서 replace 합니다.
punc_mapping = {"‘": "'", "₹": "e", "´": "'", "°": "", "€": "e", "™": "tm", "√": " sqrt ", "×": "x", "²": "2", "—": "-", "–": "-", "’": "'", "_": "-", "`": "'", '“': '"', '”': '"', '“': '"', "£": "e", '∞': 'infinity', 'θ': 'theta', '÷': '/', 'α': 'alpha', '•': '.', 'à': 'a', '−': '-', 'β': 'beta', '∅': '', '³': '3', 'π': 'pi', }
- 연속된 공백 제거
두 개 이상의 연속된 공백을 하나로 만듭니다.
- 중복된 문장 제거
dictionary로 중복을 제거합니다.
texts = list(OrderedDict.fromkeys(texts))
- 띄어쓰기 추가
띄어쓰기가 안되어있는 문장은 pykospacing을 통해 띄어쓰기 시킬 수 있습니다.
!pip install git+https://github.com/haven-jeon/PyKoSpacing.gitfrom pykospacing import spacing>>> spacing("안녕하세요저는제임스입니다.")
안녕하세요 저는 제임스입니다.
- 맞춤법 검사
py-hanspell을 사용해서 맞춤법을 검사할 수 있습니다.
!pip install git+https://github.com/ssut/py-hanspell.gitfrom hanspell import spell_checker
spell_checker.check("외안돼")
checked = spelled_sent.checked
- 형태소 분석기를 사용한 문장 필터링
konlpy의 Mecab을 사용해 명사(NN), 동사(V), 형용사(J)가 3개의 품사가 최소 하나씩 존재해야합니다.
!pip install konlpy# Mecab 설치 / 가장 빠른 한국어 형태소 분석기
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)from konlpy.tag import Mecab
mecab = Mecab()
morphs = mecab.pos("아버지가방에들어가신다.", join=False) # pos = part of speech
>>> print(morphs)
[('아버지', 'NNG'), ('가', 'JKS'), ('방', 'NNG'), ('에', 'JKB'), ('들어가', 'VV'), ('신다', 'EP+EF'), ('.', 'SF')]
Tag들은 다음과 같이 분류할 수 있습니다. (명사 NN, 동사 V, 형용사 J)
NN_TAGS = ["NNG", "NNP", "NNB", "NP"]
V_TAGS = ["VV", "VA", "VX", "VCP", "VCN", "XSN", "XSA", "XSV"]
J_TAGS = ["JKS", "J", "JO", "JK", "JKC", "JKG", "JKB", "JKV", "JKQ", "JX", "JC", "JKI", "JKO", "JKM", "ETM"]
- 불용어 필터링
큰 의미가 없는 불용어를 필터링합니다.
- 문장 최대, 최소 길이 필터링
문장의 MAX LEN, MIN LEN을 기준으로 필터링합니다.
- 다른 나라 언어 필터링
음절 단위로 비교해 사전에 정의한 Unicode 범위 내에 존재하는 언어들을 필터링합니다.
주의할 점은 같은 unicode 체계를 사용하는 언어가 있어 같이 삭제가 될 수 있습니다. (독일어를 삭제하려고 헀지만 같은 알파벳으로 영어가 삭제됨)
a = int(range_s, 16) # 16진수 -> 10진수 변환
b = int(range_e, 16)
if a<= ord(w) and ord(w) <= b:2) 한국어 토크나이징
토크나이징의 목적은 크게 두 가지입니다.
- 의미를 지닌 단위로 자연어를 분절
- Model의 학습 시, 동일한 size로 입력
따라서 token의 개수가 부족할 때는 [padding] 처리를 해주고, 개수가 많을 때는 token을 잘라서 반환해주어야 합니다.
max_seq_length = 10
# padding
tokenized_text += ["[PAD]"] * (max_seq_length - len(tokenized_text))
>>> print(tokenized_text)
['이순신은', '조선', '중기의', '무신이다.', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
- 어절 단위 tokenizing
모든 단어를 띄어쓰기 단위로 분리
text = "이순신은 조선 중기의 무신이다."
tokenized_text = text.split(" ")
>>> print(tokenized_text)
['이순신은', '조선', '중기의', '무신이다.']
- 형태소 단위 tokenizing
형태소 분석기를 사용해서 분리
!pip install konlpy!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)from konlpy.tag import Mecab
mecab = Mecab()
text = "이순신은 조선 중기의 무신이다."
tokenized_text = [lemma[0] for lemma in mecab.pos(text)]
>>> print(tokenized_text)
['이순신', '은', '조선', '중기', '의', '무신', '이', '다', '.']
- 음절 단위 tokenizing
자연어를 한 글자씩 분리
text = "이순신은 조선 중기의 무신이다."
tokenized_text = list(text)
>>> print(tokenized_text)
['이', '순', '신', '은', ' ', '조', '선', ' ', '중', '기', '의', ' ', '무', '신', '이', '다', '.']
- 자소 단위 tokenizing
초성, 중성, 종성 총 3개의 자소로 분리
!pip install hgtkimport hgtk
text = "이순신은 조선 중기의 무신이다."
tokenized_text = list(hgtk.text.decompose(text))
>>> print(tokenized_text) # ᴥ는 음절과 음절 단위를 구분해주는 구분자
['ㅇ', 'ㅣ', 'ᴥ', 'ㅅ', 'ㅜ', 'ㄴ', 'ᴥ', 'ㅅ', 'ㅣ', 'ㄴ', 'ᴥ', 'ㅇ', 'ㅡ', 'ㄴ', 'ᴥ', ' ', 'ㅈ', 'ㅗ', 'ᴥ', 'ㅅ', 'ㅓ', 'ㄴ', 'ᴥ', ' ', 'ㅈ', 'ㅜ', 'ㅇ', 'ᴥ', 'ㄱ', 'ㅣ', 'ᴥ', 'ㅇ', 'ㅢ', 'ᴥ', ' ', 'ㅁ', 'ㅜ', 'ᴥ', 'ㅅ', 'ㅣ', 'ㄴ', 'ᴥ', 'ㅇ', 'ㅣ', 'ᴥ', 'ㄷ', 'ㅏ', 'ᴥ', '.']
- WordPiece tokenizing
NLP 모델이 학습한 단어 조각으로 분리
!pip install transformers!mkdir wordPieceTokenizerfrom tokenizers import BertWordPieceTokenizer
# Initialize an empty tokenizer
wp_tokenizer = BertWordPieceTokenizer(
clean_text=True, # [이순신, ##은, ' ', 조선]에서 띄어쓰기 ' '를 지우고 싶다면 True // bert model은 모두 clean_text가 true
handle_chinese_chars=True, # 본문 내에 있는 한자가 음절 단위로 분리
strip_accents=False, # True: [YepHamza] -> [Yep, Hamza] // 대문자가 나오는 기준으로 분리
lowercase=False, # 모두 소문자로 변경 // False로 하는 것이 성능이 더 좋음
)
# And then train
wp_tokenizer.train(
files="[FILE_PATH]",
vocab_size=10000, # 내가 만들고 싶은 vocab의 size이며, 크게 만들수록 음절 단위로 잘림
min_frequency=2, # 2개 이하로 등장하면 vocab으로 만들지 않음
show_progress=True,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"],
limit_alphabet=1000,
wordpieces_prefix="##" # prefix // ##은 앞에 연결된 음절이 있다는 의미
)
# Save the files
wp_tokenizer.save_model("wordPieceTokenizer", "my_tokenizer")text = "이순신은 조선 중기의 무신이다."
tokenized_text = wp_tokenizer.encode(text)
>>> print(tokenized_text)
Encoding(num_tokens=10, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing])
>>> print(tokenized_text.tokens)
['이', '##순', '##신은', '조선', '중', '##기의', '무', '##신이', '##다', '.']
>>> print(tokenized_text.ids)
[708, 1340, 7612, 1999, 756, 2601, 452, 8478, 1016, 16]
4️⃣ Sub Task
1) 개인정보 보호를 위한 regex 정리
개인정보 보호를 위해 "*"을 많이 사용하는데 re.sub를 많이 사용합니다.
근데 re.sub를 사용하면 match된 모든 값들을 repl 값들로 바꿔버리는 문제가 발생하였습니다.
김철수 -> 김**- 김철수 -> ***
따라서 김철수 -> 김** 로 바꾸고 싶다면 (?<= ... ) 문구를 사용하면 됩니다.
만약, (?<= ABC) DEF 이런식으로 사용하게 되면 ABCDEF를 re.sub가 match시키지만, 변환은 DEF만 하게 됩니다.
이름 필터링은 다음과 같이 만들 수 있습니다.
text = "김철수"
text = re.sub("(?<=[가-힣])[가-힣]{1,3}", r'**' ,text)
>>> print(text)
"김**"
이메일 필터링은 다음과 같이 만들 수 있습니다.
text = "cheul_INFP@gmail.com"
text = re.sub(r"(?<=[a-zA-Z])[\w_-]+(?=@)", '*'*(len(text.split("@")[0])-1),text)
>> print(text)
"c*********@gmail.com"
2) 한글 발음으로 변환
'소리나는 대로' 표현하기 위해 일반적인 자연어 텍스트를 발음 형태로 변환할 수 있습니다.
!pip install g2pkfrom g2pk import G2p
g2p = G2p()
>>> g2p(texts)
5️⃣ Evaluation
| 날짜 | Data processing | Model | Training | Time | Accuracy |
| 4/13 | - EDA - |
1h | - | ||
| 4/13 | - new baseline code - |
30m | 59.3000% | ||
1) 한국어 토크나이징
- 위에서 배운 한국어 전처리와 토크나이징을 실제 프로젝트에 적용해보는 것이 목표입니다.
2) 차후 목표
- AI 모델 사용하기
- 프로젝트에 적용 가능한 최적의 Tokenizer 찾기
'[P Stage 2] KLUE > 프로젝트' 카테고리의 다른 글
| [Stage 2 - 05] Pororo 라이브러리 사용하기 (0) | 2021.04.20 |
|---|---|
| [Stage 2 - 04] Entity Special token (0) | 2021.04.20 |
| [Stage 2 - 04] BERT MASK & 단일 문장 분류 (0) | 2021.04.16 |
| [Stage 2 - 03] BERT (0) | 2021.04.15 |
| [Stage 2 - 01] EDA (0) | 2021.04.13 |



