
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Comparisons
- linalg
- VSCode
- boolean & fancy index
- Python 유래
- 카테고리분포 MLE
- ndarray
- pivot table
- seaborn
- Operation function
- Numpy
- 최대가능도 추정법
- 부스트캠프 AI테크
- subplot
- 딥러닝
- Array operations
- scatter
- python 문법
- Python 특징
- 가능도
- 표집분포
- namedtuple
- Python
- Numpy data I/O
- BOXPLOT
- type hints
- unstack
- groupby
- dtype
- 정규분포 MLE
- Today
- Total
또르르's 개발 Story
[Stage 2 - 03] BERT 본문
1️⃣ Goal
[BaseLine 작성] (추가 : 4/12, 새로운 Baseline code)- [Data Processing]
- Exploratory Data Analysis (추가 : 4/12, 기간 : 4/12 ~ )
- Cross-validation 사용 (추가 : 4/12)
- 데이터 불균형 해소 (추가 : 4/12)
-한국어 전처리 (추가 : 4/13, 기간 : 4/13 ~ 4/13 )
- 새로운 tokenizer 사용 (추가 : 4/12, 기간 : 4/13 ~ )
- 형태소 분류기 -> BERT wordpiece (추가 : 4/13)
- [ENT][/ENT] tag를 추가해서 train 돌리기 (추가 : 4/14) - [Model]
- BERT 모델 사용 (추가 : 4/12, 기간 : 4/14 ~ )
- GPT 모델 사용 (추가 : 4/12)
- ELECTRA 모델 사용 (추가 : 4/12)
- KoBERT 모델 사용 (추가 : 4/12) - [Training]
- 앙상블 시도 (추가 : 4/12)
- Hyperparameter 변경 (추가 : 4/12)
- Learning Schedular 사용 (추가 : 4/12)
- 좋은 위치에서 Checkpoint 만들기 (추가 : 4/12)
- NNI (Auto ML) 사용 (추가 : 4/12) - [Deploy]
- Python 모듈화 (추가 : 4/12)
2️⃣ Learning
[Stage 2 - 이론] 한국어 토큰화
1️⃣ 자연어 처리 단계 Task 설계 필요 데이터 수집 통계학적 분석 - Token 개수 -> 아웃라이어 제거 - 빈도 확인 -> 사전(dictionary) 정읟 전처리 - 개행 문자 / 특수 문자 제거 - 공백 제거 - 중복 표현
dororo21.tistory.com
tokenizer의 구조가 어떻게 만들어졌는지 다시 찾아봤더니, 데이터 압축 알고리즘 중 하나인 byte pair encoding 기법을 적용해서 sub-word tokenization을 한다고 써놓았네요..;;
dororo21.tistory.com/48?category=918851
[19-1] Byte Pair Encoding with Python
1️⃣ Byte Pair Encoding 일반적으로 하나의 단어에 대해 하나의 embedding을 생성할 경우 out-of-vocabulary(OOV)라는 치명적인 문제를 갖게 됩니다. 학습 데이터에서 등장하지 않은 단어가 나오는 경우 Unknow
dororo21.tistory.com
3️⃣ Main Task
1) BERT 모델 사용하기
huggingface의 transformers를 설치하고 불러옵니다.
!pip install transformersfrom transformers import AutoModel, AutoTokenizer, BertTokenizer
104개의 언어를 통째로 학습한 모델 multi-lingual bert model를 사용합니다.
MODEL_NAME = "bert-base-multilingual-cased" # 104개 언어를 통째로 학습한 모델
model = AutoModel.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
Multi-lingual bert model은 총 vocab size는 119,547개 정도되며, 그 중 한국어는 8000개 정도된다고 합니다.
>>> print(tokenizer.vocab_size) # 한국어는 8000개 정도의 vocab
119547
1-1) Tokenizer 사용
tokenizer를 하게되면 bert model은 총 3개의 값들을 출력합니다.
tokenized_input_text = tokenizer(text, return_tensors="pt") # return_tensors는 pytorch로 반환
for key, value in tokenized_input_text.items():
print("{}:\n\t{}".format(key, value))input_ids: # token -> vocab의 ID
tensor([[ 101, 9638, 119064, 25387, 10892, 59906, 9694, 46874, 9294,
25387, 11925, 119, 102]])
token_type_ids: # Sentence 구분 (sentence2는 1로 초기화됨)
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
attention_mask: # special token (pad, cls, sep) 구분 / padding은 0으로 초기화
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
여기서 tokenizer.tokenize를 사용하면 입력된 texts를 tokenizing해서 명시적으로 보여줍니다.
tokenized_text = tokenizer.tokenize(text)
>>> print(tokenized_text)
['이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.']
text를 encode하면 앞 뒤로 [CLS], [SEP] special token이 자동으로 붙습니다.
따라서 101 (CLS), 102 (SEP)이 붙습니다.
input_ids = tokenizer.encode(text)
>>> print(input_ids)
[101, 9638, 119064, 25387, 10892, 59906, 9694, 46874, 9294, 25387, 11925, 119, 102]
encode된 input_ids를 다시 decode하면 문자로 돌아옵니다.
이때, [CLS] / [SEP]가 붙어서 출력됩니다.
decoded_ids = tokenizer.decode(input_ids)
>>> print(decoded_ids)
[CLS] 이순신은 조선 중기의 무신이다. [SEP]
만약 special token이 부착되지 않게 만들려면 add_special_tokens=False로 합니다.
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False) # special token 부착 X
>>> print(tokenized_text)
['이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.']
input_ids = tokenizer.encode(text, add_special_tokens=False)
>>> print(input_ids)
[9638, 119064, 25387, 10892, 59906, 9694, 46874, 9294, 25387, 11925, 119]
decoded_ids = tokenizer.decode(input_ids)
>>> print(decoded_ids)
이순신은 조선 중기의 무신이다.
tokenizer.tokenize와 tokenizer.encode에는 다양한 조건들을 더 넣을 수 있습니다.
tokenized_text = tokenizer.tokenize(
text,
add_special_tokens=False,
max_length=5, # token을 기준으로 5개
truncation=True # truncation(긴 문장을 max length에 맞춰 자름)을 자동으로 수행해줌
)
>>> print(tokenized_text)
['이', '##순', '##신', '##은', '조선']
input_ids = tokenizer.encode(
text,
add_special_tokens=False,
max_length=5,
truncation=True
)
>>> print(input_ids)
[9638, 119064, 25387, 10892, 59906]
decoded_ids = tokenizer.decode(input_ids)
>>> print(decoded_ids) # 이때, token개수가 max_length로 truncation되는 것이며, 글자 수와 다를 수 있음
이순신은 조선
padding을 넣어서 사용할 수 있습니다.
tokenized_text = tokenizer.tokenize(
text,
add_special_tokens=False,
max_length=20, # token을 기준으로 5개
padding="max_length" # padding은 다양함 (앞에 / 뒤에 / segment A,B 위치에 넣을 수 있음)
)
>>> print(tokenized_text)
['이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
input_ids = tokenizer.encode(
text,
add_special_tokens=False,
max_length=20,
padding="max_length"
)
>>> print(input_ids)
[9638, 119064, 25387, 10892, 59906, 9694, 46874, 9294, 25387, 11925, 119, 0, 0, 0, 0, 0, 0, 0, 0, 0]
decoded_ids = tokenizer.decode(input_ids)
>>> print(decoded_ids) # 이때, token개수가 max_length로 truncation되는 것이며, 글자 수와 다를 수 있음
이순신은 조선 중기의 무신이다. [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
1-2) 새로운 Token 추가
하지만 언어는 계속 발전하며, Vocab에 없는 단어가 나올 수 있습니다.
[UNK]가 많이 발생할수록 원본 문장의 의미가 점점 희석됩니다.
[UNK] 리뿔이 뜨럽거 므리커럭이 [UNK] 냐왜쇼 [UNK] [UNK]
따라서 tokenizer.add_tokens로 token을 추가할 수 있습니다.
added_token_num = tokenizer.add_tokens(["깟뻬뜨랑", "케쇽", "우뤼갸", "쳥쇼", "섀료"]) # token 추가
Vocab의 크기가 늘어난 것을 알 수 있습니다.
>>> print(tokenizer.vocab_size)
119547
1-3) Special token 추가
Special token을 추가하기 위해서는 dict 형태로 넣어주어야 합니다.
여기서 added_token_num을 일반 token + special token을 더해줬는데, 추가된 token (일반 + special 모두)들을 모두 저장해두어야 합니다.
added_token_num += tokenizer.add_special_tokens({"additional_special_tokens":["[ENTITY]", "[/ENTITY]"]}) # special token 추가
token을 출력하면 다음과 같습니다.
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
>>> print(tokenized_text)
['[ENTITY]', '이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.', '[/ENTITY]']
1-4) Model의 embedding layer size 늘리기
Vocab을 새롭게 추가했다면, model의 embedding layer size를 늘려야합니다.
>>> print(model.get_input_embeddings())
Embedding(119547, 768, padding_idx=0)model.resize_token_embeddings(tokenizer.vocab_size + added_token_num).>>> print(model.get_input_embeddings())
Embedding(119554, 768)
1-5) Model inference test
huggingface의 pipeline 모듈을 사용해 바로 [MASK] token을 inference할 수 있습니다.
text = "이순신은 [MASK] 중기의 무신이다."
tokenized_text = tokenizer.tokenize(text)
>>> print(tokenized_text)
['이', '##순', '##신', '##은', '[MASK]', '중', '##기의', '무', '##신', '##이다', '.']from transformers import pipeline
nlp_fill = pipeline('fill-mask', model=MODEL_NAME) # inference를 바로 test할 수 있음
nlp_fill("이순신은 [MASK] 중기의 무신이다.")Some weights of the model checkpoint at bert-base-multilingual-cased were not used when initializing BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[{'score': 0.8747126460075378,
'sequence': '이순신은 조선 중기의 무신이다.',
'token': 59906,
'token_str': '조선'},
{'score': 0.06436426192522049,
'sequence': '이순신은 청 중기의 무신이다.',
'token': 9751,
'token_str': '청'},
{'score': 0.010954886674880981,
'sequence': '이순신은 전 중기의 무신이다.',
'token': 9665,
'token_str': '전'},
{'score': 0.0046471720561385155,
'sequence': '이순신은종 중기의 무신이다.',
'token': 22200,
'token_str': '##종'},
{'score': 0.0036106714978814125,
'sequence': '이순신은기 중기의 무신이다.',
'token': 12310,
'token_str': '##기'}]
모델의 출력 결과를 확인할 수 있습니다.
tokens_pt = tokenizer("이순신은 조선 중기의 무신이다.", return_tensors="pt")
outputs = model(**tokens_pt) # **tokens_pt로 넣게 되면 embedding vector들을 모두 집어넣을 수 있음
last_hidden_state = outputs.last_hidden_state
pooler_output = outputs.pooler_output
>>> print("\nToken wise output: {}, Pooled output: {}".format(last_hidden_state.shape, pooler_output.shape))
Token wise output: torch.Size([1, 13, 768]), Pooled output: torch.Size([1, 768])
1-6) [CLS] token으로 문장 유사도 측정
sent1 = tokenizer("오늘 하루 어떻게 보냈나요?", return_tensors="pt")
sent2 = tokenizer("오늘은 어떤 하루를 보내셨나요?", return_tensors="pt")
sent3 = tokenizer("이순신은 조선 중기의 무신이다.", return_tensors="pt")
sent4 = tokenizer("깟뻬뜨랑 리뿔이 뜨럽거 므리커럭이 케쇽 냐왜쇼 우뤼갸 쳥쇼섀료다혀뚜여", return_tensors="pt")
outputs = model(**sent1)
sent_1_pooler_output = outputs.pooler_output
outputs = model(**sent2)
sent_2_pooler_output = outputs.pooler_output
outputs = model(**sent3)
sent_3_pooler_output = outputs.pooler_output
outputs = model(**sent4)
sent_4_pooler_output = outputs.pooler_output
torch.nn의 CosinSimilarity를 사용해서 sent들의 cosine 유사도를 측정합니다.
from torch import nn
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
print(cos(sent_1_pooler_output, sent_2_pooler_output))
print(cos(sent_2_pooler_output, sent_3_pooler_output))
print(cos(sent_3_pooler_output, sent_4_pooler_output))
print(cos(sent_1_pooler_output, sent_4_pooler_output))sent1과 sent2는 0.97의 높은 유사도가 있고, sent2와 setn3, sent3과 sent4는 상대적 낮은 유사도를 가지고 있습니다.
하지만 sent1과 sent4는 유사도가 높지만 실제로는 관련없는 문장입니다.
tensor([0.9757], grad_fn=<DivBackward0>)
tensor([0.6075], grad_fn=<DivBackward0>)
tensor([0.5929], grad_fn=<DivBackward0>)
tensor([0.9342], grad_fn=<DivBackward0>)1-7) 간단한 chatbot
BERT와 [CLS]의 Cosine 유사도를 사용해서 간단한 chatbot을 만들 수 있습니다.
아래는 question과 answer이 있습니다.
chatbot_Question = ['기차 타고 여행 가고 싶어','꿈이 이루어질까?','내년에는 더 행복해질려고 이렇게 힘든가봅니다', '간만에 휴식 중', '오늘도 힘차게!'] # 질문
chatbot_Answer = ['꿈꾸던 여행이네요.','현실을 꿈처럼 만들어봐요.','더 행복해질 거예요.', '휴식도 필요하죠', '아자아자 화이팅!!'] # 답변
이후, 모든 question을 model에 넣고 돌려 [CLS] token을 추출합니다.
이후 question의 [CLS] token은 모두 dataset_cls_hidden에 저장합니다.
dataset_cls_hidden = []
for q in chatbot_Question:
q_cls = get_cls_token(q) # question list를 가지고 와 cls token으로 변경
dataset_cls_hidden.append(q_cls)
이후, query값을 사용자에게 받고 query값의 [CLS] token을 추출합니다.
query = '아 여행가고 싶다~'
query_cls_hidden = get_cls_token(query)
Query와 Question의 [CLS]값들의 cosine_similarity가 가장 높은 index 번호를 추출합니다.
cos_sim = cosine_similarity(query_cls_hidden, dataset_cls_hidden)>>> print(cos_sim)
[[0.85016316 0.7788856 0.73615134 0.77987427 0.7242017 ]]
0번이 가장 높기 때문에 0번의 답변을 추출합니다.
top_question = np.argmax(cos_sim)
print('나의 질문: ', query)
print('저장된 답변: ', chatbot_Answer[top_question])나의 질문: 아 여행가고 싶다~
저장된 답변: 꿈꾸던 여행이네요.
4️⃣ Sub Task
1) BERT에 Entity Layer 추가 방법
Special token에 [Entity] token을 추가하고 이 special token을 잘 사용하기 위해서는 Entity layer를 추가해주는 것 또한 하나의 방법이라고 생각합니다.
따라서 BERT의 parameter에서 embeddings 부분에 entity layer를 추가로 넣으려고 합니다.
MODEL_NAME = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(MODEL_NAME)
model.parameters
하지만 add_module을 통해 Embedding을 추가하려고 했지만 마지막 layer 후에 추가되는 문제점이 발생했습니다.
model.embeddings.add_module(name="entity layer", module=torch.nn.Embedding(2,768))>>> model.parameters
따라서 docs를 살펴보니 BertEmbeddings 클래스를 약간 수정해서 layer를 추가할 수 있을 것 같았습니다.
아래 사진은 huggingface에 있는 BertEmbeddings class입니다.
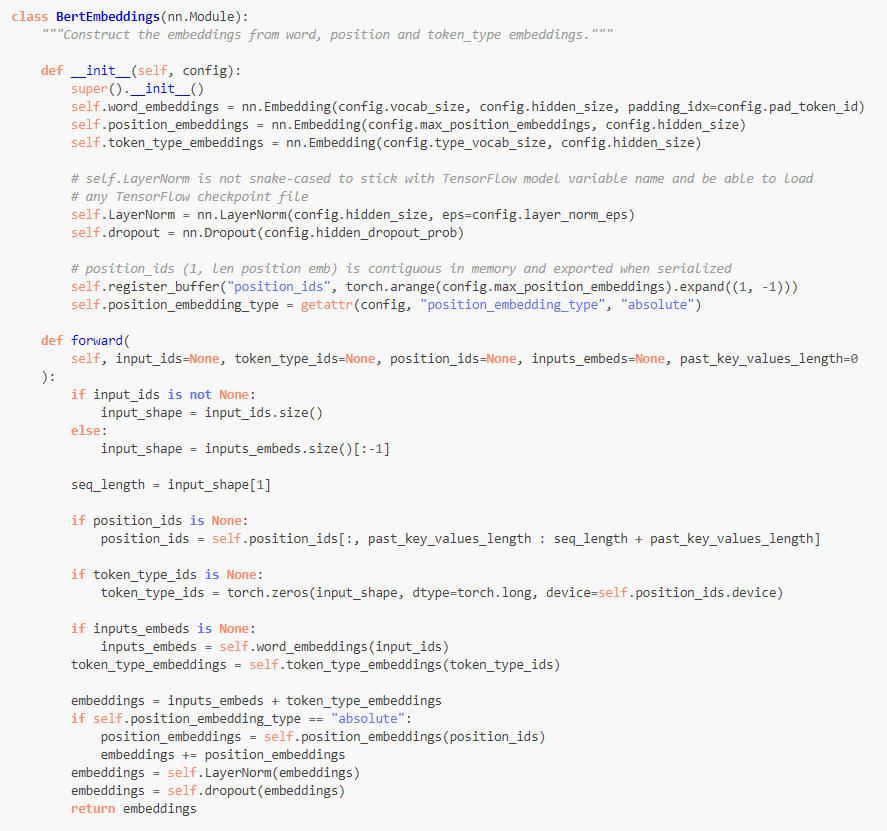
여기서 entity_embeddings를 추가해줍니다.
물론 여기서 input size, hidden size를 모두 token_type_embedding 형태를 그대로 따라했고 필요에 따라 수정해야 합니다.
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.entity_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size) # entity_embedding 추가
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
entity_embeddings = self.entity_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings + entity_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
그리고 BertConfig를 가지고 와서 새롭게 정의한 BertEmbeddings 클래스에 넣어줍니다.
configuration = BertConfig()custom_bertembeddings = BertEmbeddings(configuration)
custom_bertembeddings을 model의 embedding에 넣어줍니다.
model.embeddings = custom_bertembeddings
model의 parameter를 찍어보면 원하는 위치에 잘 들어간 것을 알 수 있습니다.
>>> model.parameters
5️⃣ Evaluation
| 날짜 | Data processing | Model | Training | Time | Accuracy |
| 4/13 | - EDA - |
1h | - | ||
| 4/13 | - new baseline code - |
30m | 59.3000% | ||
| 4/14 | - KoBERT - |
- epoch : 20 max_len = 128 batch_size = 32 - |
23m | 72.0000% |
1) BERT 모델 사용
- BERT 모델에 들어가 있는 tokenizer의 사용 방법에 대해서 알 수 있는 시간이었습니다.
- 새로운 token과 special token을 추가하는 법을 배웠습니다.
2) 차후 목표
- 다른 NLP 모델 찾아보기
- BERT에 entity layer 추가해서 사용해보기
- tokenizer를 자유자재로 다루기
'[P Stage 2] KLUE > 프로젝트' 카테고리의 다른 글
| [Stage 2 - 05] Pororo 라이브러리 사용하기 (0) | 2021.04.20 |
|---|---|
| [Stage 2 - 04] Entity Special token (0) | 2021.04.20 |
| [Stage 2 - 04] BERT MASK & 단일 문장 분류 (0) | 2021.04.16 |
| [Stage 2 - 02] 한국어 전처리 / 토크나이징 (0) | 2021.04.14 |
| [Stage 2 - 01] EDA (0) | 2021.04.13 |



