
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- pivot table
- 가능도
- ndarray
- subplot
- 정규분포 MLE
- unstack
- BOXPLOT
- dtype
- python 문법
- type hints
- Operation function
- groupby
- scatter
- VSCode
- Python 특징
- linalg
- 딥러닝
- 부스트캠프 AI테크
- Comparisons
- Python
- 표집분포
- Numpy data I/O
- Python 유래
- Array operations
- Numpy
- boolean & fancy index
- 카테고리분포 MLE
- 최대가능도 추정법
- seaborn
- namedtuple
Archives
- Today
- Total
또르르's 개발 Story
[31-3] Scratch Training VS Fine Tuning (VGG-11) 본문
네트워크를 처음부터 학습(scratch training) 하였을 때와 pre-trained 된 네트워크에 fine tuning을 적용하였을 때를 비교하는 문제입니다.
데이터는 저작권 문제로 생략합니다.
1️⃣ 설정
필요한 모듈을 import 합니다.
# Seed
import torch
import numpy as np
import random
torch.manual_seed(0)
torch.cuda.manual_seed(0)
np.random.seed(0)
random.seed(0)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')2️⃣ Dataset 설정하기
DataSet을 새롭게 설정합니다.
# Dataset
import torch
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import os
import cv2
import numpy as np
from glob import glob
class Dataset(Dataset):
def __init__(self, data_root, is_Train=True, input_size=224, transform=None):
super(Dataset, self).__init__()
self.img_list = self._load_img_list(data_root, is_Train)
self.len = len(self.img_list)
self.input_size = input_size
self.transform = transform
def __getitem__(self, index):
img_path = self.img_list[index]
# Image Loading
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img/255.
if self.transform:
img = self.transform(img)
# Ground Truth
label = self._get_class_idx_from_img_name(img_path)
return img, label
def __len__(self):
return self.len
def _get_class_idx_from_img_name(self, img_path):
img_name = os.path.basename(img_path)
if 'normal' in img_name: return 0
elif 'test1' in img_name: return 1
elif 'test2' in img_name: return 2
elif 'test3' in img_name: return 3
elif 'test4' in img_name: return 4
elif 'test5' in img_name: return 5
elif 'incorrect test' in img_name: return 6
else:
raise ValueError("%s is not a valid filename. Please change the name of %s." % (img_name, img_path))DataLoader에 dataset을 올려 loader상태로 만들어줍니다.
# Dataset and Data Loader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
train_dataset = Dataset(data_root, is_Train=True, input_size=input_size, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, pin_memory=True, shuffle=True)
valid_dataset = Dataset(data_root, is_Train=False, input_size=input_size, transform=transform)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, pin_memory=True, shuffle=False)
3️⃣ Scratch Training
Pre-training을 사용하지 않고 초기 상태부터 학습을 진행(from scratch)하는 단계입니다.
from torchvision.models import vgg11
pretrained = False # True of False
model = vgg11(pretrained)
model.classifier[6] = nn.Linear(in_features=4096, out_features=7, bias=True)
model.cuda()VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(11): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): ReLU(inplace=True)
(13): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(14): ReLU(inplace=True)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): ReLU(inplace=True)
(20): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=7, bias=True)
)
)Loss와 Optimizer를 정의합니다.
# Loss function and Optimizer
from torch.optim import Adam
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=lr)# Main
os.makedirs(log_dir, exist_ok=True)
with open(os.path.join(log_dir, 'scratch_train_log.csv'), 'w') as log:
# Training
for iter, (img, label) in enumerate(train_loader):
# optimizer에 저장된 미분값을 0으로 초기화
optimizer.zero_grad()
# GPU 연산
img, label = img.type(torch.FloatTensor).cuda(), label.cuda()
# 모델에 이미지 forward
pred_logit = model(img)
# loss 값 계산
loss = criterion(pred_logit, label)
# Backpropagation
loss.backward()
optimizer.step()
# Accuracy 계산
_,y_pred = torch.max(pred_logit.data,1)
pred_label = (y_pred==label).sum().item()
acc = pred_label / img.size(0)
train_loss = loss.item()
train_acc = acc
# Validation for every 20 epoch
if (iter % 20 == 0) or (iter == len(train_loader)-1):
valid_loss, valid_acc = AverageMeter(), AverageMeter()
for img, label in valid_loader:
# GPU 연산
img, label = img.type(torch.FloatTensor).cuda(), label.cuda()
# 모델에 이미지 forward (gradient 계산 X)
with torch.no_grad():
pred_logit = model(img)
# loss 값 계산
loss = criterion(pred_logit, label)
# Accuracy 계산
_,y_pred = torch.max(pred_logit.data,1)
pred_label = (y_pred==label).sum().item()
acc = pred_label / img.size(0)
valid_loss.update(loss.item(), len(img))
valid_acc.update(acc, len(img))
valid_loss = valid_loss.avg
valid_acc = valid_acc.avg
print("Iter [%3d/%3d] | Train Loss %.4f | Train Acc %.4f | Valid Loss %.4f | Valid Acc %.4f" %(iter, len(train_loader), train_loss, train_acc, valid_loss, valid_acc))# Scratch Training result
Iter [ 0/120] | Train Loss 1.9725 | Train Acc 0.1250 | Valid Loss 1.9554 | Valid Acc 0.1429
Iter [ 20/120] | Train Loss 1.9578 | Train Acc 0.0000 | Valid Loss 1.9466 | Valid Acc 0.1273
Iter [ 40/120] | Train Loss 1.9124 | Train Acc 0.2500 | Valid Loss 1.9446 | Valid Acc 0.1429
Iter [ 60/120] | Train Loss 1.9568 | Train Acc 0.2500 | Valid Loss 1.9407 | Valid Acc 0.1677
Iter [ 80/120] | Train Loss 1.5040 | Train Acc 0.5000 | Valid Loss 1.8183 | Valid Acc 0.2888
Iter [100/120] | Train Loss 1.7515 | Train Acc 0.6250 | Valid Loss 1.8438 | Valid Acc 0.2174
Iter [119/120] | Train Loss 1.9318 | Train Acc 0.2857 | Valid Loss 1.8468 | Valid Acc 0.2453
4️⃣ Fine tuning
ImageNet에 pre-train된 weights를 초기값으로 사용하여 학습을 진행(fine tuning)하는 단계입니다.
from torchvision.models import vgg11
pretrained = True # True of False
model = vgg11(pretrained)
model.classifier[6] = nn.Linear(in_features=4096, out_features=7, bias=True)
model.cuda()
# Freeze the feature extracting convolution layers
for param in model.features.parameters():
param.requires_grad = FalseLoss와 Optimizer를 정의합니다.
# Loss function and Optimizer
from torch.optim import Adam
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=lr)# Main
os.makedirs(log_dir, exist_ok=True)
with open(os.path.join(log_dir, 'fine_tuned_train_log.csv'), 'w') as log:
# Training
for iter, (img, label) in enumerate(train_loader):
# optimizer에 저장된 미분값을 0으로 초기화
optimizer.zero_grad()
# GPU 연산
img, label = img.type(torch.FloatTensor).cuda(), label.cuda()
# 모델에 이미지 forward
pred_logit = model(img)
# loss 값 계산
loss = criterion(pred_logit, label)
# Backpropagation
loss.backward()
optimizer.step()
# Accuracy 계산
_,y_pred = torch.max(pred_logit.data,1)
pred_label = (y_pred==label).sum().item()
acc = pred_label / img.size(0)
train_loss = loss.item()
train_acc = acc
# Validation for every 20 epoch
if (iter % 20 == 0) or (iter == len(train_loader)-1):
valid_loss, valid_acc = AverageMeter(), AverageMeter()
for img, label in valid_loader:
# GPU 연산
img, label = img.type(torch.FloatTensor).cuda(), label.cuda()
# 모델에 이미지 forward (gradient 계산 X)
with torch.no_grad():
pred_logit = model(img)
# loss 값 계산
loss = criterion(pred_logit, label)
# Accuracy 계산
_,y_pred = torch.max(pred_logit.data,1)
pred_label = (y_pred==label).sum().item()
acc = pred_label / img.size(0)
valid_loss.update(loss.item(), len(img))
valid_acc.update(acc, len(img))
valid_loss = valid_loss.avg
valid_acc = valid_acc.avg
print("Iter [%3d/%3d] | Train Loss %.4f | Train Acc %.4f | Valid Loss %.4f | Valid Acc %.4f" %(iter, len(train_loader), train_loss, train_acc, valid_loss, valid_acc))Scratch Training보다 Loss와 Accuracy가 훨씬 빠르게 정답에 도달하는 것을 알 수 있습니다.
# Fine tuning result
Iter [ 0/120] | Train Loss 1.9274 | Train Acc 0.2500 | Valid Loss 2.0970 | Valid Acc 0.1211
Iter [ 20/120] | Train Loss 1.5025 | Train Acc 0.2500 | Valid Loss 1.5778 | Valid Acc 0.3975
Iter [ 40/120] | Train Loss 1.0306 | Train Acc 0.6250 | Valid Loss 1.4823 | Valid Acc 0.4565
Iter [ 60/120] | Train Loss 1.0807 | Train Acc 0.5000 | Valid Loss 1.4128 | Valid Acc 0.5062
Iter [ 80/120] | Train Loss 1.0972 | Train Acc 0.5000 | Valid Loss 1.2141 | Valid Acc 0.5807
Iter [100/120] | Train Loss 0.7244 | Train Acc 0.7500 | Valid Loss 1.0971 | Valid Acc 0.6211
Iter [119/120] | Train Loss 0.4674 | Train Acc 0.8571 | Valid Loss 1.3172 | Valid Acc 0.6118
5️⃣ 결과 시각화
결과를 pyplot을 사용해 그려보면 다음과 같습니다.
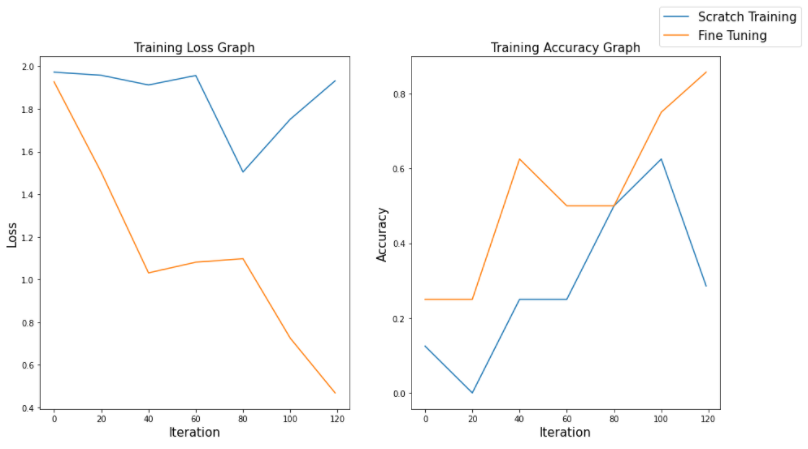
- Visualize training log
Fine Tuning이 Scratch보다 Loss가 훨씬 빠르게 줄어들고, Accuracy는 훨씬 빠르게 증가하는 것을 알 수 있습니다.
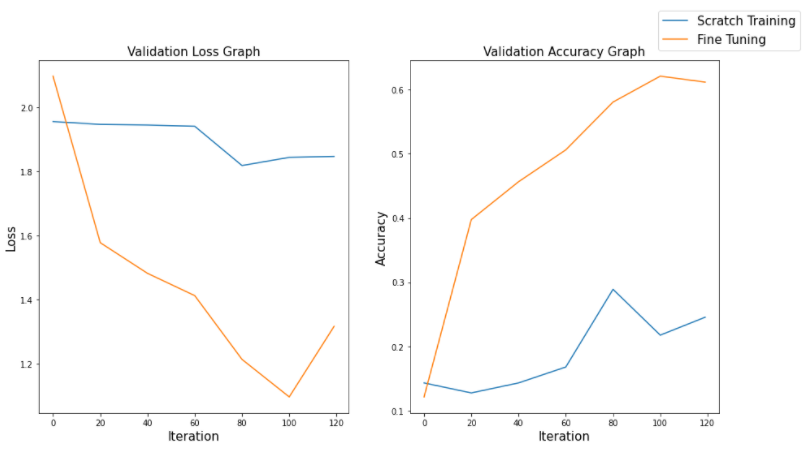
- Visualize validation log
Validation dataset에서는 차이가 더욱 확실하게 나타납니다.
'부스트캠프 AI 테크 U stage > 실습' 카테고리의 다른 글
| [33-2] Pytorch Autograd (0) | 2021.03.11 |
|---|---|
| [32-2] Segmentation using PyTorch (0) | 2021.03.10 |
| [31-2] VGG-11 구현 using PyTorch (0) | 2021.03.08 |
| [25-1] GraphSAGE 모델 구현 using DGL Library (0) | 2021.02.27 |
| [24-3] 추천 시스템 using surprise library (0) | 2021.02.26 |
'부스트캠프 AI 테크 U stage/실습' Related Articles
more




Comments