
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- unstack
- 최대가능도 추정법
- VSCode
- type hints
- 가능도
- BOXPLOT
- Comparisons
- dtype
- 딥러닝
- groupby
- Array operations
- Numpy data I/O
- Python
- Operation function
- Numpy
- python 문법
- seaborn
- 정규분포 MLE
- linalg
- Python 유래
- 표집분포
- 카테고리분포 MLE
- subplot
- scatter
- Python 특징
- ndarray
- 부스트캠프 AI테크
- namedtuple
- pivot table
- boolean & fancy index
- Today
- Total
또르르's 개발 Story
[33-2] Pytorch Autograd 본문
1️⃣ Autograd
Automatic gradient의 약자로 자동 미분을 뜻합니다.
Autograd는 자동으로 forward & backward passes를 가능하게 만들어줍니다.
즉, 학습을 하면서 많은 parameter를 사용했다면 backpropagation을 하면서 자동으로 gradient를 계산해줍니다.
Autograd는 Computational graph라는 데이터 구조를 사용해서 automatic gradient를 편리하게 구현할 수 있도록 만들었습니다.
- $c$는 $w_2$와 $a$의 operation으로 계산됨
- $b$는 $w_1$과 $a$의 operation으로 계산됨
- $d$는 $c$와 $b$와 $w_4$, $w_3$의 operation으로 계산됨
- $L$은 $d$의 operation으로 계산됨

Computational graph는 $L$이 계산되기 전까지 어떠한 history를 가지고 있었는지 그 계보를 다 가지고 있습니다. Computational graph에서는 terminal node에서부터 $L$까지 도달하기까지 어떠한 연산들, 어떠한 연결성을 가지고 계산이 되느냐를 따로 저장하고 있습니다.
예를 들어, $L$에서 $a$에 대한 gradient를 구하고 싶다면 $d$, $c$, $b$, $a$를 타고 넘어와 backpropagation을 계산할 수 있습니다. 즉, chain rule은 연쇄 작용을 따라가는데 graph를 제너럴하게 나타냄으로 이 history를 따라갈 수 있는 것입니다. 따라서 Backward를 구현하기 쉽게 만들어놓았습니다.
2️⃣ backward()
아래 코드에서 y.backward를 사용하면 Autograd는 $\frac {\partial y} {\partial 변수}$ 형태로 편미분을 계산해 놓습니다.
x.grad를 수행하면 $\frac {\partial y} {\partial x}$를 출력하게 됩니다.
$\frac {\partial y} {\partial x}$를 하면 원래는 3이 나와야하는데 gradients라는 argument를 넣게 되면 $gradients \times \frac {\partial y} {\partial x}$ 형태로 계산되게 됩니다. (backward()에 아무것도 넣지 않으면 gradients=1)

여기서 requires_grad = True는 $x$가 gradient를 저장할 수 있는 변수로 선언해준다는 의미입니다.
그래야 x.grad로 호출할 수 있습니다.
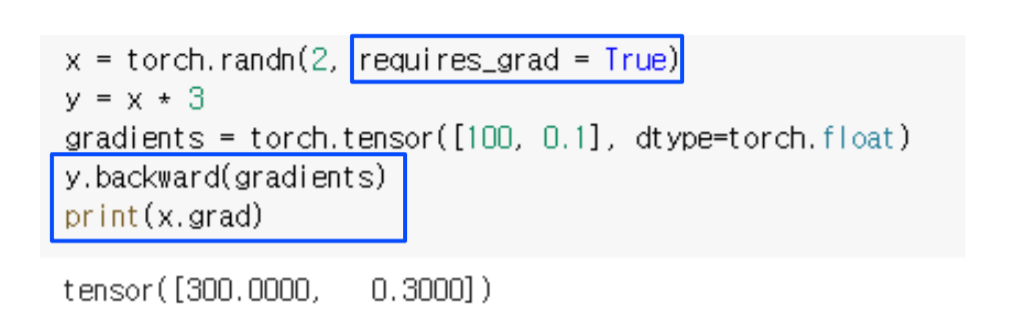
requires_grad = False로 하게되면 y.backward에서 error가 나게됩니다.
이유는 y로 backward를 했기 때문에 y = x * 3에서 x와 3이 gradient를 담을 수 있는 변수가 없기 때문에 오류가 납니다.

y.backward를 두 번 호출하게되면 error가 납니다.
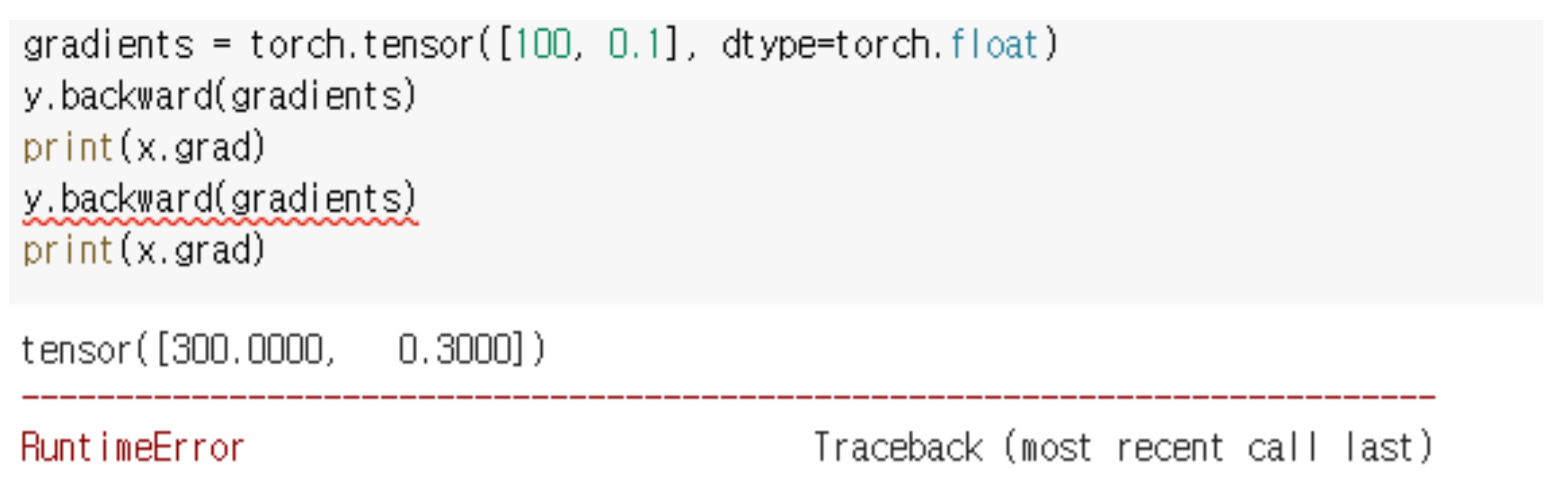
왜냐하면 backward를 한 번 호출하면 그 중간에 계산했었던 computational graph를 지워버립니다.
즉, intermediate resource (중간 자원)들을 모두 release (제거) 해버리는 것입니다.
따라서 retain_graph=True라고 값을 주게되면 intermediate resource가 사라지지 않습니다.
backward()를 두 번하게 되면 첫 번째 결과와 두 번째 결과가 accumulated되서 나오게 됩니다.

3️⃣ grad_fn
만약, x를 가지고 w,y,z 로 computational graph를 만든다고 했을 때 w,y,z는 모두 graph를 가지고 있습니다.
그렇다면 이 computational graph들을 backpropagation할 때 어떻게 구현이 되느냐하면 grad_fn attribute 형태로 되어 있다고 말할 수 있습니다.
아래 코드와 같이 w,y,z 값 모두 grad_fn attribute가 달려있는데,
- w 직전의 computational graph의 operation은 덧셈
- y 직전의 computational graph의 operation은 곱셈
- z 직전의 computational graph의 operation은 나눗셈
을 나타냅니다. 이 grad_fn의 의미은 backpropagation을 수행할 때 해당 값과 직전의 값 사이의 operation을 뜻하게 됩니다.

4️⃣ no_grad
torch.no_grad를 하게 되면 autograd가 requires_grad=True 인 Tensor들의 연산 기록을 추적하는 것을 멈출 수 있습니다.
requires_grad=True 인 Tensor들의 연산 기록을 추적은 forward를 수행하면서 하기 때문에 forward를 수행하는 칸 위에 torch.no_grad를 사용해야합니다.
5️⃣ hook
CAM에서는 class ativation map을 계산할 때 중간에 gradient값을 저장해야했습니다. 따라서 중간에서 gradient 값을 얻을 때 hook을 사용합니다.
여기서 register_hook이라고 하면 Backward가 call될 때 backward 중간에 있는 정보를 빼오는 방법입니다.

따라서 gradient를 hook하게 되면은 우리가 gradient를 계산할 때마다 gradient를 낚아채올 수 있습니다.
hook을 사용하기 위해 3 layer짜리 SimpleNet을 정의합니다.

hook이라는 것이 동작을 할 때 어떤 것을 실행해야하는지 Signature of hook function이라는 것을 정의해야합니다. Signature of hook function은 hooking이 동작을 할 때 hook_func (아래 코드) 내의 정의된 동작들이 수행되게 되게끔 구현을 해줍니다.
중요한 점은 hook_func의 argument인 input, output는 항상 존재해야합니다.

Hooking을 걸고 싶은 layer에다가 register hook을 수행합니다.
conv1.register_forward_hook은 conv1 layer가 foward 될 때 동작하라고 등록해주는 것입니다.

Forward pass를 하게되면서 Activation이 계산될 때 hook function이 자동으로 호출됩니다.

register_forward_pre_hook은 hook이 foward pass를 하기 바로 직전에 발생합니다.

register_backward_hook은 backpropagation을 할 때 hooking을 수행합니다.
register_backward_hook은 input을 만들어주고 network를 forwarding할때까지는 동작하지 않습니다.
이후, 뒤쪽에서 error를 계산한 후에 backward() 함수를 호출하게 되면 backpropagation이 수행되면서 hook이 실행되게 됩니다.
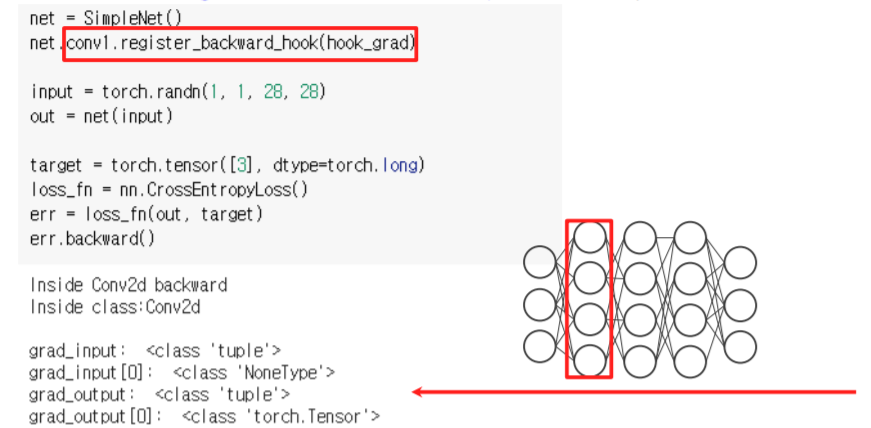
register_backward_hook의 signature of hook function인 hook_grad의 함수는 다음과 같습니다.
중요한 점은 hook_grad의 argument인 grad_input, grad_output는 항상 존재해야합니다.
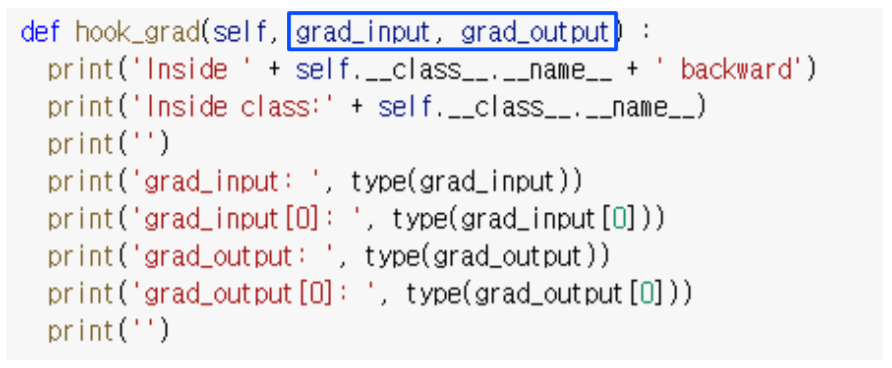
grad_input, grad_out의 argument 변경이 안되지만 gradient를 바꾸고 싶을 때는 선택적으로 return이 가능합니다.
hook_grad에 return에다가 새로운 gradient를 계산해서 넣어주면은 hook_grad를 통과하면서 backpropagation이 다음으로 넘어갈 때 gradient가 변형돼서 넘어가게 됩니다.
register를 지우는 방법은 Handle.remove() 함수를 사용하면 됩니다.
register_hook을 선언하고 반환되는 값 (h)를 Handle이라고 부릅니다.

1) register_hook을 사용해서 중간에 activation을 가지고 오는 방법 (예시)
(1) hook_func을 정의합니다.
- save_feat : feature가 들어왔을 때 feature를 저장하는 list

(2) hook_func을 등록합니다.
- model.get_model_shortcuts() : model에서 각각의 module들을 가지고 옴

(3) foward pass 수행
forward pass가 수행되면서 설정한 target_layer에서 hook에 걸려 output이 save_feat list에 저장되게 됩니다.

'부스트캠프 AI 테크 U stage > 실습' 카테고리의 다른 글
| [34-4] Hourglass Network using PyTorch (0) | 2021.03.12 |
|---|---|
| [34-3] CNN Visualization using VGG11 (0) | 2021.03.12 |
| [32-2] Segmentation using PyTorch (0) | 2021.03.10 |
| [31-3] Scratch Training VS Fine Tuning (VGG-11) (0) | 2021.03.08 |
| [31-2] VGG-11 구현 using PyTorch (0) | 2021.03.08 |



