
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- groupby
- 카테고리분포 MLE
- 딥러닝
- 정규분포 MLE
- Python
- Numpy
- ndarray
- Python 유래
- Numpy data I/O
- Python 특징
- Array operations
- subplot
- python 문법
- Operation function
- 최대가능도 추정법
- 부스트캠프 AI테크
- 표집분포
- unstack
- boolean & fancy index
- BOXPLOT
- dtype
- linalg
- 가능도
- VSCode
- namedtuple
- type hints
- seaborn
- scatter
- pivot table
- Comparisons
- Today
- Total
또르르's 개발 Story
[36-1] Model Conversion 본문
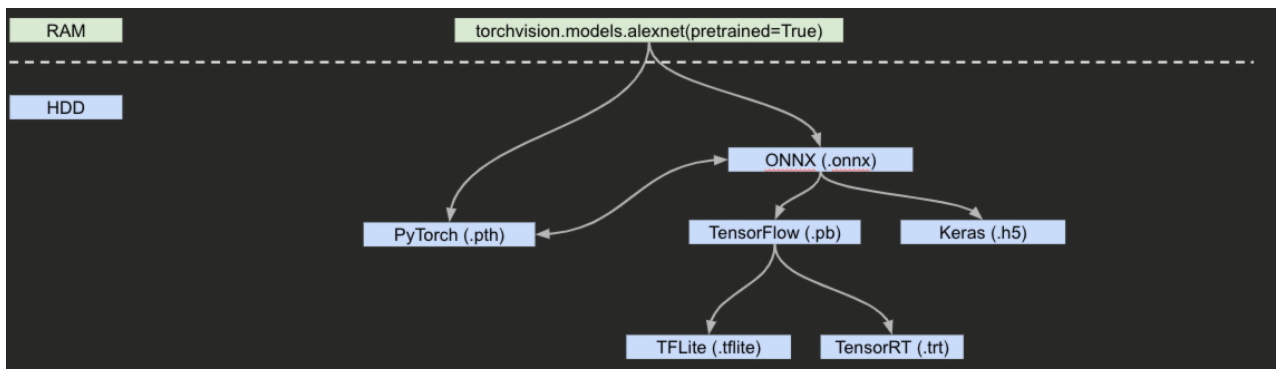
Model Conversion은 하나의 모델을 여러 Library로 변경하는 방법을 뜻합니다.
아래 그림과 같이 pytorch (.pth)로 pre-trained된 alexnet을 불러온다고 할 때
- ONNX (.onnx) -> Tensorflow (.pb)
- Tensorflow (.pb) -> tensorrt (.trt)
- PyTorch (.pth) -> ONNX (.onnx)
- ONNX (.onnx) -> PyTorch (.pth)
- ONNX (.onnx) -> Keras (.h5)
- Tensorflow (.pb) -> Tensorflowlite (.tflite)
로 변경할 수 있습니다.
즉, 대부분 ONNX 형식으로 변환 후 Model을 conversion 할 수 있습니다.
1️⃣ 설정
Onnx, tensorflow, pytorch 등 필요한 Library를 설치합니다.
!pip install onnx2keras
!pip install pycuda
!pip install onnx==1.7.0
!pip install Pympler
!pip install onnx-tf==1.7.0
!pip install tensorflow-addons==0.11.2
그리고 필요한 모듈을 불러옵니다.
import torch
import torchvision
import onnx
from onnx_tf.backend import prepare
from onnx2keras import onnx_to_keras
from onnx_tf.backend import prepare
import tensorflow as tf
각 Library의 버전은 다음과 같습니다.
# Check version
>>> print(tf.__version__)
2.4.1
>>> print(onnx.__version__)
1.7.0
>>> print(torch.__version__)
1.8.0+cu101
>>> print(torchvision.__version__)
0.9.0+cu101
2️⃣ Pytorch
torchvision에 등록되어있는 pre-trained Alexnet을 불러옵니다.
dummy_input = torch.randn(10, 3, 224, 224, device='cuda')
model = torchvision.models.alexnet(pretrained=True).cuda() # alexnet의 pre-trained를 넣음
# input, output마다 이름을 출력
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
Alexnet 모델을 .pth 형태로 저장합니다.
# export torch (.pth) pth 형태로 저장
torch.save(model, "alexnet.pth")
3️⃣ Pytorch <-> Onnx
Torch에서 .onxx로 export합니다.
# export torch -> .onnx
torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names)graph(%actual_input_1 : Float(10, 3, 224, 224, strides=[150528, 50176, 224, 1], requires_grad=0, device=cuda:0),
%learned_0 : Float(64, 3, 11, 11, strides=[363, 121, 11, 1], requires_grad=1, device=cuda:0),
%learned_1 : Float(64, strides=[1], requires_grad=1, device=cuda:0),
%learned_2 : Float(192, 64, 5, 5, strides=[1600, 25, 5, 1], requires_grad=1, device=cuda:0),
%learned_3 : Float(192, strides=[1], requires_grad=1, device=cuda:0),
%learned_4 : Float(384, 192, 3, 3, strides=[1728, 9, 3, 1], requires_grad=1, device=cuda:0),
%learned_5 : Float(384, strides=[1], requires_grad=1, device=cuda:0),
%learned_6 : Float(256, 384, 3, 3, strides=[3456, 9, 3, 1], requires_grad=1, device=cuda:0),
%learned_7 : Float(256, strides=[1], requires_grad=1, device=cuda:0),
%learned_8 : Float(256, 256, 3, 3, strides=[2304, 9, 3, 1], requires_grad=1, device=cuda:0),
%learned_9 : Float(256, strides=[1], requires_grad=1, device=cuda:0),
%learned_10 : Float(4096, 9216, strides=[9216, 1], requires_grad=1, device=cuda:0),
%learned_11 : Float(4096, strides=[1], requires_grad=1, device=cuda:0),
%learned_12 : Float(4096, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0),
%learned_13 : Float(4096, strides=[1], requires_grad=1, device=cuda:0),
%learned_14 : Float(1000, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0),
%learned_15 : Float(1000, strides=[1], requires_grad=1, device=cuda:0)):
%17 : Float(10, 64, 55, 55, strides=[193600, 3025, 55, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[11, 11], pads=[2, 2, 2, 2], strides=[4, 4]](%actual_input_1, %learned_0, %learned_1) # /usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py:396:0
%18 : Float(10, 64, 55, 55, strides=[193600, 3025, 55, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%17) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%19 : Float(10, 64, 27, 27, strides=[46656, 729, 27, 1], requires_grad=1, device=cuda:0) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%18) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:659:0
%20 : Float(10, 192, 27, 27, strides=[139968, 729, 27, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[5, 5], pads=[2, 2, 2, 2], strides=[1, 1]](%19, %learned_2, %learned_3) # /usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py:396:0
%21 : Float(10, 192, 27, 27, strides=[139968, 729, 27, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%20) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%22 : Float(10, 192, 13, 13, strides=[32448, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%21) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:659:0
%23 : Float(10, 384, 13, 13, strides=[64896, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%22, %learned_4, %learned_5) # /usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py:396:0
%24 : Float(10, 384, 13, 13, strides=[64896, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%23) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%25 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%24, %learned_6, %learned_7) # /usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py:396:0
%26 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%25) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%27 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%26, %learned_8, %learned_9) # /usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py:396:0
%28 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%27) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%29 : Float(10, 256, 6, 6, strides=[9216, 36, 6, 1], requires_grad=1, device=cuda:0) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%28) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:659:0
%30 : Float(10, 256, 6, 6, strides=[9216, 36, 6, 1], requires_grad=1, device=cuda:0) = onnx::AveragePool[kernel_shape=[1, 1], strides=[1, 1]](%29) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1037:0
%31 : Float(10, 9216, strides=[9216, 1], requires_grad=1, device=cuda:0) = onnx::Flatten[axis=1](%30) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1076:0
%32 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0) = onnx::Gemm[alpha=1., beta=1., transB=1](%31, %learned_10, %learned_11) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1753:0
%33 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%32) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1076:0
%34 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0) = onnx::Gemm[alpha=1., beta=1., transB=1](%33, %learned_12, %learned_13) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1753:0
%35 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cuda:0) = onnx::Relu(%34) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1204:0
%output1 : Float(10, 1000, strides=[1000, 1], requires_grad=1, device=cuda:0) = onnx::Gemm[alpha=1., beta=1., transB=1](%35, %learned_14, %learned_15) # /usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1753:0
return (%output1)
onnx 모델을 다시 불러와 torch (.pth) 형태로 저장하려면 다음과 같습니다.
# export onnx -> .pth
model = onnx.load("alexnet.onnx")
torch.save(model, "alexnet-onnx2pth.pth")
4️⃣ Onnx -> Tensorflow
Onnx (.onnx)에서 Tensorflow (.pb)로 Model을 conversion합니다.
# export onnx -> tensorflow (.pb)
onnx_model = onnx.load("alexnet.onnx")
output = prepare(onnx_model)
output.export_graph("alexnet.pb")
4️⃣ Onnx -> Keras
Onnx (.onnx)에서 Keras (.h5)로 Model을 conversion합니다.
# export onnx -> keras (.h5)
onnx_model = onnx.load("alexnet.onnx")
k_model = onnx_to_keras(onnx_model, ['actual_input_1'])
k_model.save("alexnet.h5")
5️⃣ Tensorflow -> TensorflowLite
Tensorflow (.pb)에서 TensorflowLite (.tflite)로 Model을 conversion합니다.
# export pb -> tensorflowlite (.tflite)
converter = tf.lite.TFLiteConverter.from_saved_model("alexnet.pb")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tf_lite_model = converter.convert()
open('alexnet.tflite', 'wb').write(tf_lite_model)
6️⃣ Tensorflow -> Tensorrt
Tensorflow (.pb)에서 Tensorrt (.trt)로 Model을 conversion합니다.
# export pb -> tensorrt (.trt)
params = tf.experimental.tensorrt.ConversionParams(precision_mode='FP16')
converter = tf.experimental.tensorrt.Converter(input_saved_model_dir="alexnet.pb", conversion_params=params)
converter.convert()
converter.save("alexnet.trt")
7️⃣ Data 크기 비교
각 Library를 통해 저장된 pre-trained data의 크기는 다음과 같습니다.
TensorflowLite의 data 크기가 가장 작은 것을 알 수 있습니다.
tensorflow (.pb) : 233.14mb
tensorrt (.trt) : 466.23mb
onnx2pth (.pth) : 351.28mb
keras (.h5) : 233.14mb
onnx (.onnx) : 233.08mb
pytorch (.pth): 233.09mb
tensorflowlite (.tflite) : 58.33mb
⏩ Bytecode 역어셈블러
Python의 dis 모듈을 사용하면 Assembler단에서 돌아가는 순서를 알 수 있습니다.
import dis
>>> dis.dis('print((4 != 0) not in [0,1,2,3])') 1 0 LOAD_NAME 0 (print)
2 LOAD_CONST 0 (4)
4 LOAD_CONST 1 (0)
6 COMPARE_OP 3 (!=)
8 LOAD_CONST 2 ((0, 1, 2, 3))
10 COMPARE_OP 7 (not in)
12 CALL_FUNCTION 1
14 RETURN_VALUE'부스트캠프 AI 테크 U stage > 실습' 카테고리의 다른 글
| [38-2] Python 병렬 Processing (0) | 2021.03.17 |
|---|---|
| [37-2] PyTorch profiler (0) | 2021.03.17 |
| [34-4] Hourglass Network using PyTorch (0) | 2021.03.12 |
| [34-3] CNN Visualization using VGG11 (0) | 2021.03.12 |
| [33-2] Pytorch Autograd (0) | 2021.03.11 |


