
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- scatter
- unstack
- ndarray
- namedtuple
- Numpy data I/O
- VSCode
- pivot table
- Operation function
- type hints
- 딥러닝
- seaborn
- BOXPLOT
- 가능도
- 카테고리분포 MLE
- 정규분포 MLE
- Python 특징
- Comparisons
- Python
- Python 유래
- Array operations
- boolean & fancy index
- linalg
- python 문법
- subplot
- Numpy
- 표집분포
- groupby
- 부스트캠프 AI테크
- 최대가능도 추정법
- dtype
- Today
- Total
또르르's 개발 Story
[34-3] CNN Visualization using VGG11 본문
Pre-trained된 VGG11을 backbone network로 사용해서 visualization을 할 수 있습니다.
1️⃣ Visualizing model activations
hook을 사용해서 중간에 있는 layer에 있는 activation map을 추출할 수 있습니다.
1) Plot_filters 함수
plot_filters함수는 weight들의 data를 시각화해주는 function입니다.
def plot_filters(data, title=None):
"""
Take a Tensor of shape (n, K, height, width) or (n, K, height, width)
and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)
"""
if data.size(1) > 3:
data = data.view(-1, 1, data.size(2), data.size(3))
data = image_tensor_to_numpy(data)
# normalize data for display
data = (data - data.min()) / (data.max() - data.min())
# force the number of filters to be square
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = (((0, n ** 2 - data.shape[0]),
(0, 2), (0, 2)) # add some space between filters
+ ((0, 0),) * (data.ndim - 3)) # don't pad the last dimension (if there is one)
data = np.pad(data, padding, mode='constant', constant_values=1) # pad with ones (white)
# tile the filters into an image
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
data = data.squeeze()
# plot it
plt.figure(figsize=(10, 10))
plt.axis('off')
plt.title(title)
plt.imshow(data)pre-trained된 VGG11의 모델을 가지고 와서 conv1에 있는 weight들의 data를 출력하면 다음과 같습니다.
model = VGG11Classification()
model.load_state_dict(torch.load(model_root)) # pre-trained
conv1_filters_data = model.backbone.conv1.weight.data # VGG11의 conv1에 있는 weight값
plot_filters(conv1_filters_data, title="Filters in conv1 layer")
2) Hook을 사용해 activation map 뽑기
Hook을 사용하면 intermediate layers (중간 layer)에 있는 activation map을 가지고 오는 것이 가능합니다.
위에서 선언한 plot_filter를 불러옵니다.
plot_activations = plot_filtersactivation_list는 hook들의 output이 저장됩니다.
show_activations_hook 함수는 signature of hook function을 뜻하며, hook을 register하기 전에 선언해주어야합니다.
activation_list = []
def show_activations_hook(name, module, input, output):
# conv/relu layer outputs (BxCxHxW)
if output.dim() == 4:
activation_list.append(output)
plot_activations(output, f"Activations on: {name}")image를 불러옵니다.
# Image preparation
img = dataset[0]
show_image(img)
img = Variable(img[np.newaxis, ...])
img = img.double()Pre-trained된 VGG11 모델을 불러옵니다.
이때, hook을 해서 activation map을 보고 싶은 layer이름은 module_list, module_name에 저장되어 있습니다.
여기서 functools.partial를 사용한 이유는 원래 hook signature에는 (module, input, output) 3가지 argument만 가능한데 4개의 argument가 존재하기 때문에 name argument를 functools.partial 함수로 미리 고정해놓고 사용합니다.
# Re-define the model to clear any previously registered hooks
model = VGG11Classification()
model.load_state_dict(torch.load(model_root))
model.double()
# Register the hook on the select set of modules
module_list = [model.backbone.conv1, model.backbone.bn4_1]
module_names = ["conv1", "bn4_1"]
for name, module in model.named_parameters():
if name.split('.')[1] in module_names and name.split('.')[2] != "bias":
idx = module_names.index(name.split('.')[1])
show_activations_hook_n = functools.partial(show_activations_hook, module_names[idx])
module_list[idx].register_forward_hook(show_activations_hook_n)
_ = model(img)데이터 저작권 출력 생략..
2️⃣ Visualizing Grad-CAM
Grad-CAM은 다음과 같은 수식으로 표현됩니다.
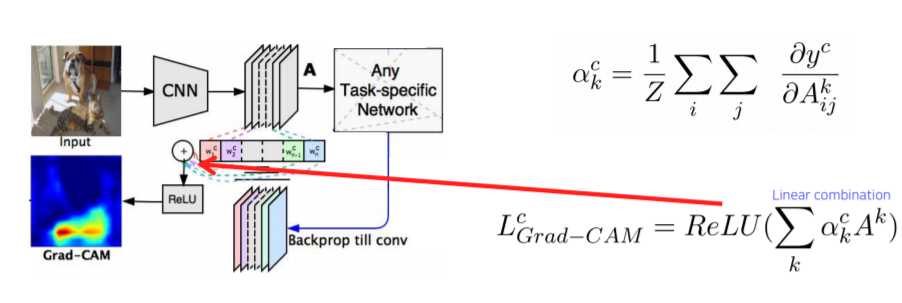
Grad-CAM 코드는 다음과 같습니다.
save_feat=[]
def hook_feat(module, input, output): # # signature of hook function- forward
relu_layer = torch.nn.ReLU()
feature = relu_layer(output)
save_feat.append(feature)
return feature
save_grad=[]
def hook_grad(module, grad_input, grad_output): # signature of hook function- backward
"""
get a gradient from intermediate layers (dy / dA).
See the .register-hook function for usage.
:return grad: (Variable) gradient dy / dA
"""
save_grad.append(grad_input)
return grad_input
def vis_gradcam(vgg, img):
"""
Imshow the grad_CAM.
:param vgg: VGG11Customed model
:param img: a dog image
output : plt.imshow(grad_CAM)
"""
vgg.eval()
# (1) forward_hook 등록
vgg.backbone.bn5_2.register_forward_hook(hook_feat)
# (2) backward_hook 등록
vgg.backbone.bn5_2.register_backward_hook(hook_grad)
# (3) Forward pass 수행 (imag를 unsqueeze해서 넣어줘야함)
img = Variable(img.unsqueeze(0), requires_grad=True)
out = vgg(img)[0]
# (4) 모델을 돌리고 나온 output값 중 max값에 대해 backward
out[out.detach().numpy().argmax()].backward()
# Compute activation at global-average-pooling layer
gap_layer = torch.nn.AdaptiveAvgPool2d(1) # gloabal averaging pooling
alpha = gap_layer(save_grad[0][0].squeeze()) # alpha값
A = save_feat[0].squeeze() # A값
# (5) Compute grad_CAM
relu_layer = torch.nn.ReLU()
grad_CAM = torch.sum(torch.mul(alpha, A), dim=0) # alpha와 A의 weighted sum
grad_CAM = torch.squeeze(grad_CAM, 0)
grad_CAM = relu_layer(grad_CAM) # relu 통과
# (6) Upscale grad_CAM
upscale_layer = torch.nn.Upsample(scale_factor=img.shape[-1]/grad_CAM.shape[-1], mode='bilinear') # 16배 확대
grad_CAM = grad_CAM.unsqueeze(0)
grad_CAM = grad_CAM.unsqueeze(0)
grad_CAM = upscale_layer(grad_CAM) # grad_CAM shape [1,1,14,14]
# Plotting
img_np = image_tensor_to_numpy(img)
if len(img_np.shape) > 3:
img_np = img_np[0]
img_np = normalize(img_np)
grad_CAM = grad_CAM.squeeze().detach().numpy()
plt.figure(figsize=(8, 8))
plt.imshow(img_np)
plt.imshow(grad_CAM, cmap='jet', alpha = 0.5)
plt.show
return grad_CAMmodel을 선언해줍니다.
model = VGG11Classification()
model.load_state_dict(torch.load(model_root))
model.double()
img = dataset[0]
res = vis_gradcam(model, img)데이터 저작권 문제로 출력 생략..
'부스트캠프 AI 테크 U stage > 실습' 카테고리의 다른 글
| [36-1] Model Conversion (0) | 2021.03.16 |
|---|---|
| [34-4] Hourglass Network using PyTorch (0) | 2021.03.12 |
| [33-2] Pytorch Autograd (0) | 2021.03.11 |
| [32-2] Segmentation using PyTorch (0) | 2021.03.10 |
| [31-3] Scratch Training VS Fine Tuning (VGG-11) (0) | 2021.03.08 |



