
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- python 문법
- ndarray
- Python 특징
- 가능도
- 딥러닝
- Numpy
- 표집분포
- seaborn
- Python 유래
- Python
- Numpy data I/O
- Operation function
- 부스트캠프 AI테크
- 카테고리분포 MLE
- Comparisons
- groupby
- 정규분포 MLE
- namedtuple
- BOXPLOT
- unstack
- Array operations
- linalg
- 최대가능도 추정법
- VSCode
- scatter
- dtype
- boolean & fancy index
- pivot table
- type hints
- subplot
- Today
- Total
또르르's 개발 Story
[09] Python pandas (2) 본문
[08] Python pandas (1)
Pandas는 panel data의 줄임말로 파이썬의 데이터 처리의 사실상 표준인 라이브러리입니다. Python의 pandas는 통계 프로그램인 R하고 비슷하다는 소리를 많이 듣는데요. pandas의 객체 생성과 함수들을
dororo21.tistory.com
위 글에 이어서 groupby, pivot, merge, concat과 같은 명령어를 정리해보겠습니다.
1️⃣ Groupby (1)
Groupby는 Series나 Data frame을 split(자르고)하고 Apply(함수 적용)하고 combine(합치는) 역할을 한 번에 수행합니다.
즉, 어떠한 column으로 묶어서 sum, std와 같은 함수를 적용한 후 보여주는 함수입니다.

1) groupby 구조

위와 같은 데이터가 존재한다고 할 때, groupby 메서드를 사용하면 Team별로 묶어서 보는 것이 가능합니다.
이때 적용받는 column (Points)을 정해주시면 Points의 sum값이 정리되어서 나옵니다.

Team
Devils 134.350288
Kings 24.006943
Riders 88.567771
Royals 72.831998
kings NaN
Name: Points, dtype: float64만약, (Team, Year)처럼 둘을 묶어서 보고 싶으시다면 list로 묶어서 쓰시면 됩니다.
>>> df.groupby(["Team", "Year"])["Points"].sum()
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Riders 2014 876
2015 789
2016 694
2017 690
Royals 2014 701
2015 804
kings 2015 812
Name: Points, dtype: int64
2) 다양한 메서드
- unstack() : Group으로 묶인 데이터를 matrix형태로 전환

- swaplevel() : Index level 변경
Index 순서를 변경합니다. (원래 Team, Rank 순서의 Index => Rank, Team 변경)
>>> grouped2.swaplevel(0)
- sort_index() : 지정한 level를 순서에 맞게 sort
level=1은 Rank index이며, 오름차순으로 sort 합니다.
>>> grouped2.sort_index(level=1)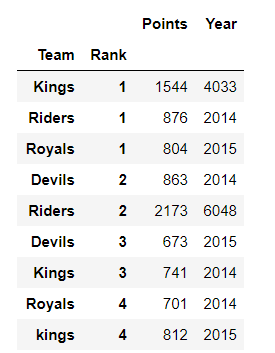
2️⃣ Groupby (2)
Groupby는 Split -> Apply -> Combine의 형태를 가진다고 했는데 Split 형태로도 사용할 수 있습니다.
>>> grouped = df.groupby("Team") # 적용 Column 지정 X
>>> for name, group in grouped:
print(name)
print(group)
Devils
Team Rank Year Points
2 Devils 2 2014 863
3 Devils 3 2015 673
Kings
Team Rank Year Points
4 Kings 3 2014 741
6 Kings 1 2016 756
7 Kings 1 2017 788
Riders
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
8 Riders 2 2016 694
11 Riders 2 2017 690
Royals
Team Rank Year Points
9 Royals 4 2014 701
10 Royals 1 2015 804
kings
Team Rank Year Points
5 kings 4 2015 812
1) 다양한 메서드
- get_group() : 특정 key값을 가진 그룹의 정보만 추출 가능
>>> grouped.get_group("Devils")
- agg() : 요약된 통계정보 추출
>>> grouped.agg(np.mean)
또는 {"column이름 1": sum, "column이름2": "count", .... } 형식으로 사용이 가능합니다.
>>> df_phone.groupby("month", as_index=False).agg({"duration": "sum"}) # as_index = False => index를 없앰
{"column이름1": action} 형식에서 action부분에 "[ ]"를 씌우면 index가 생겨납니다.
>>> grouped = df_phone.groupby("month").agg({"duration": [min, max, np.mean]})
- add_prefix() : index에 접두사를 붙임
>>> grouped.add_prefix("duration_")
- transform() : 해당 정보 fucntion에 맞게 변환해줌
>>> score = lambda x: (x - x.mean()) / x.std()
>>> grouped.transform(score)
- filter() : boolean을 사용해 특정 정보를 제거하여 보여줌
Points column의 mean()이 700 이상인 것만 보여줌
>>> df.groupby("Team").filter(lambda x: x["Points"].mean() > 700)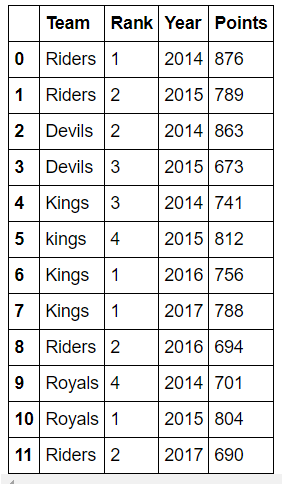
3️⃣ Pivot table & Crosstab
1) Pivot table
pivot_table을 생성할 때는 아래와 같이 생성합니다.
- index, column : 행(row), 열(column) 기준이 되는 series (groupby와 동일)
- aggfunc : sum, sub, mean 등 action
- values : aggfunc을 적용하는 값(Column에 추가로 labeling값을 추가)
df_phone.pivot_table(
values=["duration"],
index=[df_phone.month, df_phone.item],
columns=df_phone.network,
aggfunc="sum",
fill_value=0,
)
2) Crosstab
Crosstab은 pivot table의 특수한 형태로 두 column에 교차 빈도, 비율, 덧셈 등을 구할 때 사용합니다.
- index, column : 행(row), 열(column) 기준이 되는 series (groupby와 동일)
- aggfunc : sum, sub, mean 등의 action
- values : aggfunc을 적용하는 값(Column에 추가로 labeling값을 추가)
- fillna(0) : 값이 NaN일 때 0으로 채움
pd.crosstab(
index=df_movie.critic,
columns=df_movie.title,
values=df_movie.rating,
aggfunc="first",
).fillna(0)
4️⃣ Merge & Concat
Merge와 Concat은 두 개의 데이터를 하나로 합치는 작업입니다.
1) merge
merge는 두 개의 data frame을 합치는 작업입니다.
아래 df_a와 df_b 두 개의 테이블이 있다고 하면,

merge() 메서드를 사용하면 merge가 가능합니다. 이때, on은 합칠 때 기준이 되는 column 이름입니다.
>>> pd.merge(df_a, df_b, on="subject_id")
만약, 기준이 되는 column 이름이 다르다면 left_on, right_on을 사용하면 됩니다.
>>> pd.merge(df_a, df_b, left_on="subject_id", right_on="subject_id")
하지만 위의 data frame들은 subject_id가 겹치는 값들만 표시되게 됩니다. merge의 default값이 inner join으로 되어있기 때문인데 how를 사용하면 join 방법을 선택할 수 있습니다. join은 4가지 방법이 있습니다.

- Left join : how='left'
왼쪽의 모든 값, 오른쪽의 겹치는 값을 가지고 옵니다. (왼쪽에 있지만 오른쪽에 없으면 NaN)
>>> pd.merge(df_a, df_b, on="subject_id", how="left")
- right join : how='right'
왼쪽의 겹치는 값, 오른쪽의 모든 값을 가지고 옵니다. (왼쪽에 없지만 오른쪽에 있으면 NaN)
>>> pd.merge(df_a, df_b, on="subject_id", how="right")
- outer join : how='outer'
왼쪽의 모든 값, 오른쪽의 모든 값을 가지고 옵니다. (왼쪽에 없거나 오른쪽에 없으면 NaN)
>>> pd.merge(df_a, df_b, on="subject_id", how="outer")
- inner join : how='inner' 또는 default
왼쪽의 겹치는 값, 오른쪽의 겹치는 값을 가지고 옵니다. (NaN이 존재 X)
>>> pd.merge(df_a, df_b, on="subject_id", how="inner")
2) concat
concat은 같은 형태의 데이터를 붙이는 연산 작업입니다.

아래 df_a와 df_b 두 개의 테이블이 있다고 하면,
concat을 사용해 df_a 아래에 df_b를 붙일 수 있습니다.
>>> pd.concat([df_a, df_b])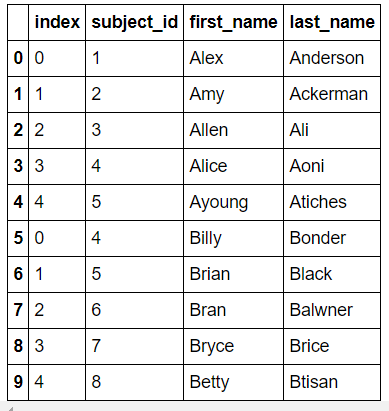
append를 사용해도 concat과 똑같은 효과를 낼 수 있습니다.
>>> df_a.append(df_b)
axis=1을 하면 오른쪽 옆에 붙게 됩니다.
>>> pd.concat([df_a, df_b], axis=1)
5️⃣ DB persistence
Pandas의 data frame을 DB에서 불러와 수정을 하고, 수정한 내용을 DB에 저장할 수 있습니다.
DB에서 정보를 가져오기 위해서는 sqlite3 모듈이 필요합니다.
import sqlite3 # pymysql 설치이후 db connection을 해서 db에 저장된 데이터를 불러옵니다.
conn = sqlite3.connect("./data/flights.db")
cur = conn.cursor()
cur.execute("select * from airlines limit 5;")
results = cur.fetchall()
>>> results
[(0, '1', 'Private flight', '\\N', '-', None, None, None, 'Y'),
(1, '2', '135 Airways', '\\N', None, 'GNL', 'GENERAL', 'United States', 'N'),
(2, '3', '1Time Airline', '\\N', '1T', 'RNX', 'NEXTIME', 'South Africa', 'Y'),
(3,
'4',
'2 Sqn No 1 Elementary Flying Training School',
'\\N',
None,
'WYT',
None,
'United Kingdom',
'N'),
(4, '5', '213 Flight Unit', '\\N', None, 'TFU', None, 'Russia', 'N')]pandas의 read_sql_query 메서드에서 sql문으로 data frame을 불러올 수 있습니다.
>>> df_airplines = pd.read_sql_query("select * from airlines;", conn)
>>> df_airplines
'부스트캠프 AI 테크 U stage > 이론' 카테고리의 다른 글
| [10] Python 시각화 모듈(matplotlib, seaborn) (0) | 2021.01.29 |
|---|---|
| [09-1] 딥러닝에 사용되는 확률론 (0) | 2021.01.28 |
| [08-1] 신경망(neural network) (0) | 2021.01.27 |
| [08] Python pandas (1) (1) | 2021.01.27 |
| [07] 경사하강법 (0) | 2021.01.26 |



