
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Numpy
- python 문법
- scatter
- subplot
- pivot table
- Array operations
- VSCode
- type hints
- Numpy data I/O
- 표집분포
- Operation function
- BOXPLOT
- Comparisons
- Python
- seaborn
- 최대가능도 추정법
- ndarray
- boolean & fancy index
- 딥러닝
- groupby
- Python 유래
- namedtuple
- Python 특징
- 카테고리분포 MLE
- 정규분포 MLE
- unstack
- linalg
- dtype
- 가능도
- 부스트캠프 AI테크
- Today
- Total
또르르's 개발 Story
[Stage 3 - 이론] Ontology-based DST models 본문
1️⃣ Ontology
Ontology는 각 Slot j가 가질 수 있는 Value의 후보군을 정의해둔 정보입니다.


Ontology는 Model에서 $Set(S^{j})$를 의미합니다.

Ontology-based model들은 이 Ontology가 미리 정의되어 있고, 모든 Value는 이 안에서만 등장 한다는 가정을 합니다.
1) 한계점
- 다루는 Ontology의 Volume이 커질 수록 Computation Cost가 증가합니다.
- Unseen value가 등장했을 때 Tracking하기 어렵습니다.
2️⃣ 이전 Ontology-based Model
기본적으로 Ontology based DST model은 크게 2가지 모듈이 존재합니다.
- Encoder: Dialogue Context 등 인풋 인코딩
- Scoring module: P(Slot j=Value n) 계산

1) Neural Belief Tracker (NBT)
과거에는 DST 모델을 heuristic하고 rule-base로 많이 풀었는데 이 모델이 데이터를 기반으로 DST를 푼 모델입니다.
여기서 Candidate Pair은 Ontology를 의미합니다.

2) GLAD
Encoder 모듈과 Scoring 모듈을 가지고 있습니다.
Encoder에는 유저의 발화(User utterance), 시스템 액션(Action)이라는 것도 있습니다.
Encoder의 Slot-value encoder는 value들과 비교해 score을 만드는 Ontology라고 말할 수 있습니다.

Encoder를 확대해보면 다음과 같습니다.
input(X)가 들어오게되면 Local BiLSTM과 Global BiLSTM이 존재합니다.
여기서 $H^{S}, C^{S}$처럼 S는 각 slot type을 의미합니다. (Tracking 해야 할 Slot 총개수는 J개이고, 미리 defined되어 있습니다.) 그래서 각 slot type마다 Local BiLSTM과 Local Self-Attn이 따로 있다는 것을 볼 수 있습니다.
Slot과 관계없이 global하게 input들을 encoding하는 것이 Global BiLSTM과 Global Self-Attn입니다.
따라서 J(Slot-Specific)+1(Global) 개의 BiLSTM과 Self-attention weight 사용합니다.
이 방법은 JxN개의 encoding & Scoring을 거쳐야합니다.
Output은 $H$와 $c$가 나오게 되는데 $H$는 BiLSTM의 hidden output이며, $c$는 self-attention layer로 하나의 vector입니다.
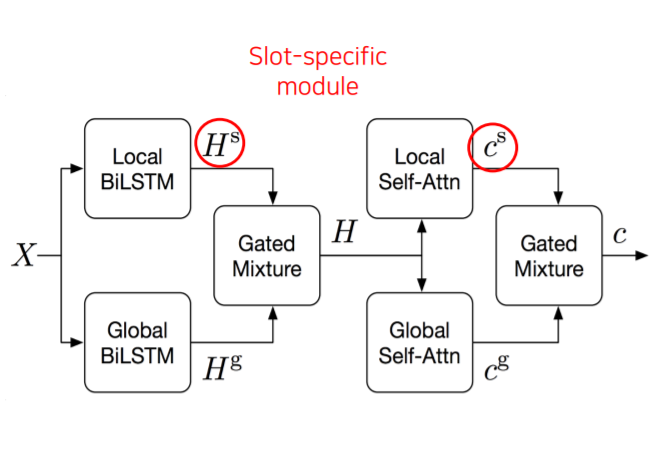
그래서 Encoding에서 유저 발화가 $H^{utt}$와 $c^{utt}$로 나오고, Action도 $H^{act}$, $C^{act}$로 나오게 됩니다.
Score Module에서는 Attention module을 사용합니다.
유저 발화의 Attention Module의 Query, Key, Value vector에는 각각 $c^{val}, H^{utt}, H^{utt}$가 들어오게 됩니다.
Act의 Attention Module의 Query, Key, Value vector에는 각각 $c^{utt}, C^{act}_{j}, C^{act}_{j}$가 들어오게 됩니다.
이후 유저 발화 Attention과 Act Attention을 각각의 계산 식을 거친 후, sigmoid를 하면 최종 scoring 값이 나오게 됩니다.

하지만 GLAD는 상당히 많은 수의 모듈을 가지고 있었기 때문에 scalable하기가 쉽지 않았습니다.
3) GCE
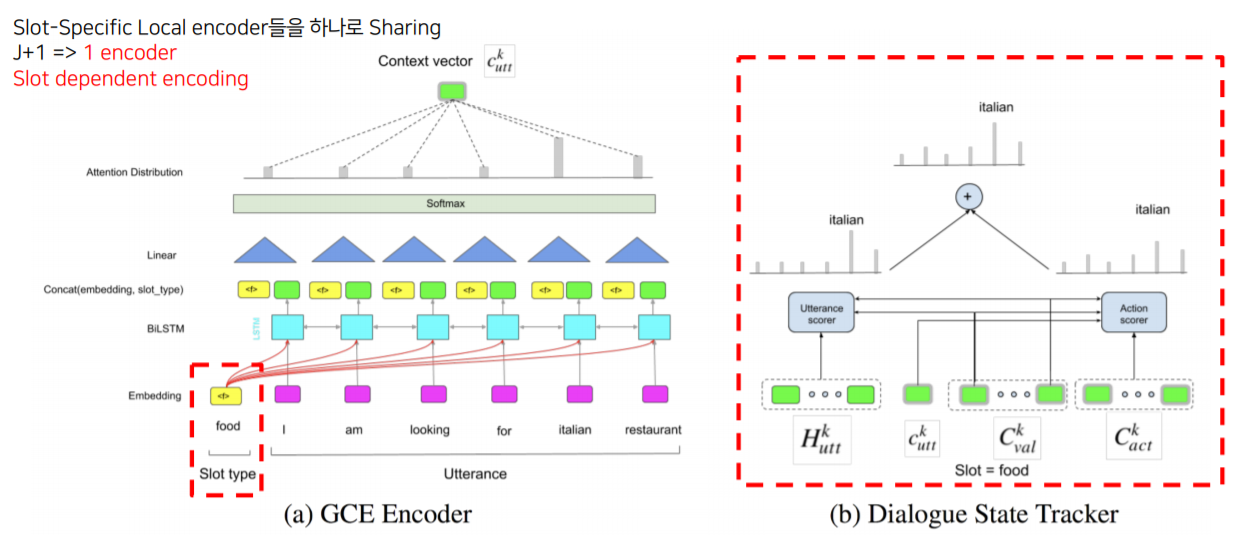
후속 논문인 GCE 논문에서는 Slot-Specific했던 Local encoder들을 하나로 sharing하는 방법을 사용헀습니다.
Encoding을 할 때 관심있는 slot type에 대해서는 추가적인 token을 넣어줘서 utterance들과 같이 encoding을 하게 됩니다. 그래서 하나의 encoder만 사용하고, slot dependent한 encoding이 가능해집니다.
scoring module은 기존 GLAD와 비슷한 구조를 가집니다.
3️⃣ SUMBT
1) Overview
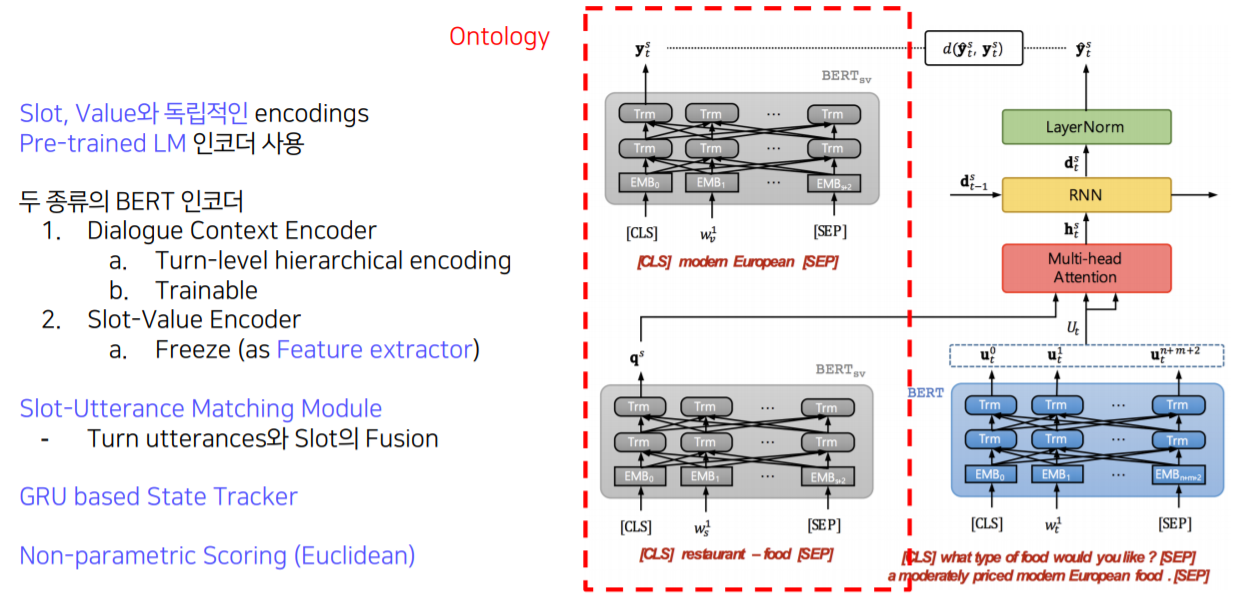
SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking.
두 종류의 BERT encoder 사용 (파란색은 trainable, 회색은 Freeze)
1. $BERT_{sv}$는 slot-value encoder이며, freeze해서 사용
2) Encoding Module
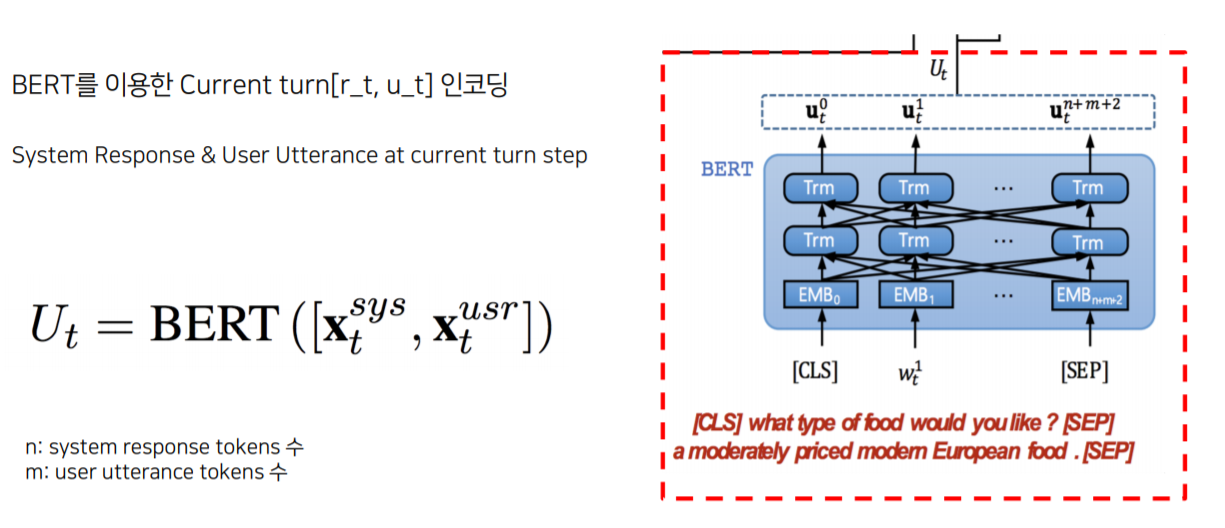
- Dialogue Context Encoder
- Slot-Value Encoder
slot, value들을 pre-encoding 한 후, vector들을 따로 저장해놓고 사용

3) Slot-Utterance Matching (Scoring)
- $q^{s}$ : Slot-Value Encoder에서 도출된 값
- $U^{t}$ : Dialogue Context Encoder에서 도출된 값

4) GRU-based State Contextualizing
- $h^{s}_{t}$ : Slot-Utterance Matching을 통과한 결과물
- $d^{s}_{t-1}$ : 이전 턴의 hidden state
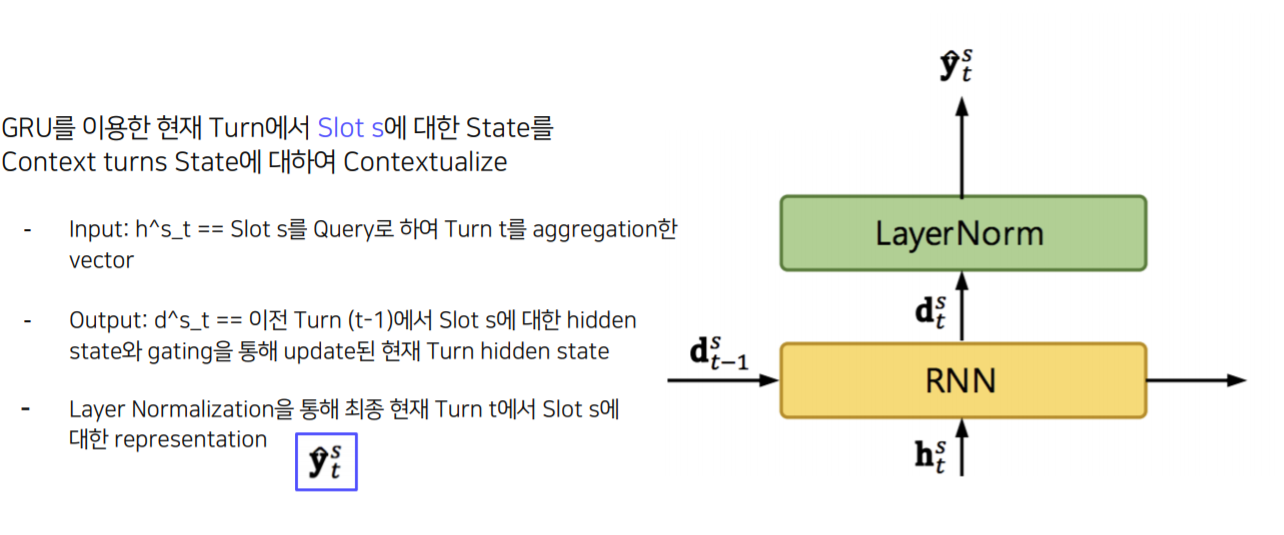
5) Non-Parametric Scoring

6) Training Criteria
여기서 $C_{s}$는 Ontology를 뜻합니다.

'[P Stage 3] DST > 이론' 카테고리의 다른 글
| [Stage 3 - 이론] DST의 한계점 (0) | 2021.05.11 |
|---|---|
| [Stage 3 - 이론] Advanced DST Models (0) | 2021.05.11 |
| [Stage 3 - 이론] DST의 Computational Complexity (0) | 2021.05.04 |
| [Stage 3 - 이론] Hybrid Approach (0) | 2021.05.04 |
| [Stage 3 - 이론] Introduction to Task-Oriented Dialogue System (0) | 2021.04.27 |



