
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 가능도
- VSCode
- BOXPLOT
- type hints
- scatter
- 딥러닝
- groupby
- python 문법
- subplot
- seaborn
- Operation function
- 카테고리분포 MLE
- pivot table
- Numpy data I/O
- linalg
- Python 유래
- dtype
- namedtuple
- Numpy
- 표집분포
- ndarray
- unstack
- 부스트캠프 AI테크
- Array operations
- Python 특징
- Python
- 정규분포 MLE
- boolean & fancy index
- 최대가능도 추정법
- Comparisons
- Today
- Total
또르르's 개발 Story
[Stage 3 - 이론] DST의 한계점 본문
1️⃣ Task Oriented Dialogue 한계점
- 매우 좁은 대화 커버러지 (N intents, J slots)
- 제한된 대화의 주도권
- 다양한 가정들
- Predefined Scenario에 대한 높은 의존도

2️⃣ Cost of Dialogue Collection
- Human2Human의 Dialogue 수집은 비용이 매우 비쌈
- 게다가 상당 수의 Annotation Errors를 발생시킴 (MultiWOZ 2.1)
- Data Distribution을 제어하는 것이 쉽지 않음 (CoCo)
1) M2M
M2M은 시나리오를 정의한 (Rule-based 시뮬레이션)을 통해 User chatbot과 System chatbot이 대화를 생성해나가는 방법을 말합니다.
M2M을 사용하면 Dialogue를 쉽게 얻을 수는 있지만 부자연스러운 대화를 가지고 올 수 있습니다.


2) Zero-shot Domain Transfer
DST모델이 보지 못한 Domain (Unseen Domain = Target Domain)에 대해 Source Domain들만 가지고 맞출 수 있게 하는 방법입니다.

3) Abstract Transaction Dialogue Model
따라서 Zero-shot Domain Transfer를 Agenda-based Simulation과 합쳐서 만든 것이 Abstract Transaction Dialogue Model입니다. Agenda-based Simulation보다 복잡한 형태의 Rule-based Simulation입니다.
- Abstract State Transition Matrix 정의
- 다양한 Template의 활용

User가 하고싶은 Action들을 여러개로 정의함으로써 복잡한 구조를 띄게 됩니다.
Abstract State는 Domain에 상관없이 Action transition의 추상적 표현 (각각을 정확한 action으로 정의해놓은 것이 아닌 뭉뚱그려서 사용)으로 사용합니다. ( start 단계, confirm 단계 등)

따라서 다양한 dialogue들을 뽑아낼 수 있습니다.

또한, TRADE와 SUMBT 모델에 Zero-shot (DM), 즉, Zero-shot에 Abstract 모델에서 생성한 Dialogue를 같이 사용했을 경우 엄청난 성능 향상이 있었습니다.

3️⃣ Natural Conversation Framework
- 현대의 대화형 에이전트를 위한 Design Principle
- Conversational Activities, Conversation Management 등 대화 상황에서 자연스럽게 일어날 수 있는 Flow를 100가지 패턴으로 명시하고 있음

따라서 예전 SOTA였던 Model들에 Naturalistic Variation을 줘서 대화를 다시 재구성하게 되면 점수가 반토막나게 됩니다.
4️⃣ Counterfactual Goal
Counterfactual Goal이라는 것은 MultiWOZ가 현실 세계를 반영하지 못하고 있는 Goal을 의미합니다.
따라서 이 CoCo라는 프레임워크는 Controllable Counterfactuals라고 합니다.

1) Utterance Generation Model
"시스템 발화"와 "이전 turn의 state 발화"와 "이번 turn에 나올 inform된 slot value"들을 받아서 "User의 발화"를 생성하는 부분입니다.

2) Counterfacutal Goal Generator
$L_{t}$ (turn level의 dialogue state)를 input으로 받아서 순서대로 3가지 operation을 수행합니다.
3가지 operation은 Drop, Change, Add입니다.

3) Utterance Sampling based CF-Goal
시스템 발화와 생성된 Counterfactual Goal $\hat{L}_{t}$를 통해 $\hat{U}^{user}_{t}$를 Sampling하게 됩니다.
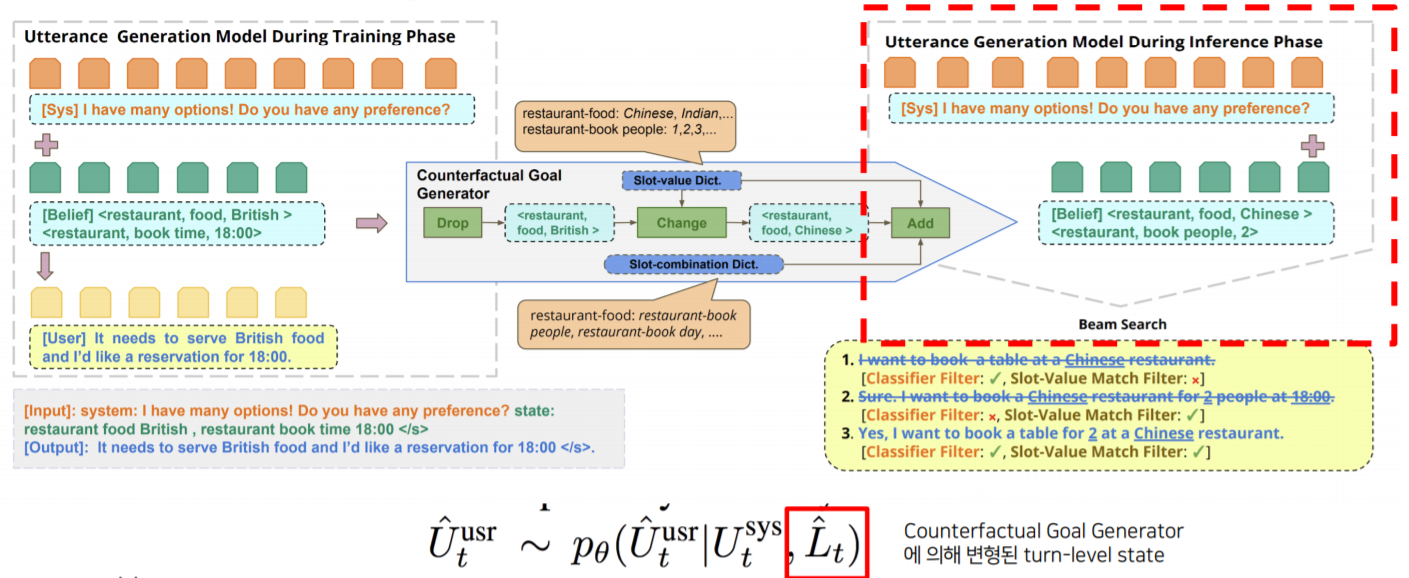
4) Filtering
User Utterance 모델이 학습된 이후에도 2가지 문제점이 있습니다.
- de-generation : $L_{t}$에 있는 (slot, value) 중 일부를 빠뜨려서 생성
- over-generation : $L_{t}$에 없는 (slot, value)까지 생성
따라서 두가지 경우의 filter를 사용하게 됩니다.
- rule-based의 slot-value match filter
- pretrained language model 사용해서 classification 수행
Beam Search를 통해 여러 개의 문장 후보군을 생성하고 이 두 개의 filter을 동시에 통과해야만 문장을 사용할 수 있습니다.

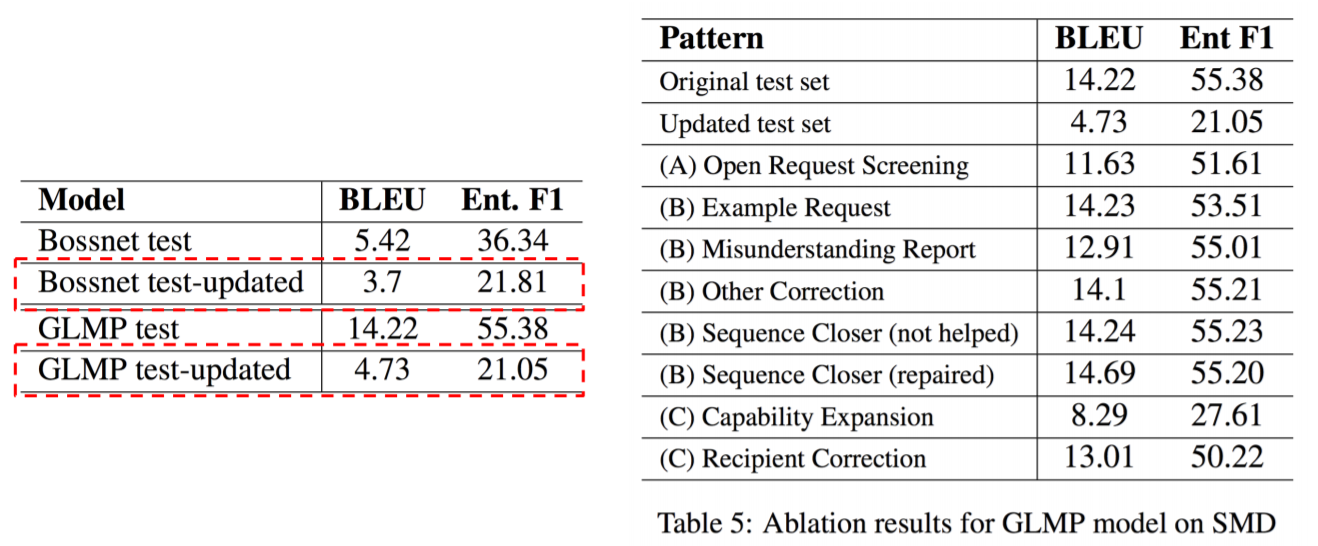
5) Evaluation Results

'[P Stage 3] DST > 이론' 카테고리의 다른 글
| [Stage 3 - 이론] Advanced DST Models (0) | 2021.05.11 |
|---|---|
| [Stage 3 - 이론] DST의 Computational Complexity (0) | 2021.05.04 |
| [Stage 3 - 이론] Hybrid Approach (0) | 2021.05.04 |
| [Stage 3 - 이론] Ontology-based DST models (0) | 2021.04.27 |
| [Stage 3 - 이론] Introduction to Task-Oriented Dialogue System (0) | 2021.04.27 |



