
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- BOXPLOT
- 최대가능도 추정법
- seaborn
- 표집분포
- 정규분포 MLE
- 카테고리분포 MLE
- Python
- Array operations
- 딥러닝
- Operation function
- Numpy data I/O
- Comparisons
- namedtuple
- 부스트캠프 AI테크
- Python 유래
- unstack
- ndarray
- python 문법
- type hints
- pivot table
- dtype
- Numpy
- VSCode
- 가능도
- Python 특징
- subplot
- linalg
- groupby
- scatter
- boolean & fancy index
- Today
- Total
또르르's 개발 Story
[Stage 3 - 이론] Advanced DST Models 본문
1️⃣ TripPy
1) Trip Copy Strategy
- Span-based Copy mechanism
Extraction based 알고리즘 - System Inform Memory for Value Prediction
- DS memory for Coreference Resolution
2) 구조

3) Encoding Module

4) Slot Gates

- Gate

- Boolean type gate
C_bool = {none, dontcare, true, false}
$$softmax(W^{bgate}_{s} \dot r^{CLS}_{t} + b^{bgate}_{s}) \in R^{4}$$
- true : 해당 slot의 value가 'yes'
- false : 해당 slot의 value가 'no'
5) Span-based Value Prediction
Slot Gate Classification의 결과 "span"으로 예측된다면, 추출된 span의 결과를 현재 턴 Slot의 value로 Copy

6) System Inform Memory for Value Prediction
"Inform"은 Service가 제안하고, User가 긍정의 의미를 지니고 있을 때 예측합니다.

7) DS Memory for Coreference Resolution
"refer"은 User가 이전 turn의 dialogue에서 inform 한 value와 동일한 value 일 때를 예측합니다.

이전에 채워진 State의 어떤 Slot에서 Value를 Copy해올지 Classification하는 것을 의미합니다.

8) Auxiliary Features
TripPy의 Input은 History로 들어가는 것을 알 수 있습니다.
따라서 Dialogue state에 어떤 값이 들어가 있는지 알기 힘든 상황입니다. 그래서 무엇을 inform 했는지도 알기 힘듭니다.

따라서 추가적인 Features를 넣어주게 됩니다.
추가적인 Feature는 Binary vector (0,1) 형태로 들어가게 됩니다.
이전에는 $p^{gate}_{t,s}, p^{bgate}_{t,s}, p^{refer}_{t,s}$ 모두 CLS vector를 사용해서 계산했지만,
Features를 넣어주기 위해 $p^{gate}_{t,s}, p^{bgate}_{t,s}, p^{refer}_{t,s}$에다가 $\hat{r}^{CLS}_{t}$로 계산이 되는 것을 알 수 있습니다.

2️⃣ Pretraining
1) TOD-BERT
TOD-BERT의 경우 DST에 적합한 Corpus를 가지고 훈련시킨 BERT 모델을 뜻합니다.


또한 훈련을 시킬 때 두 가지 방법을 사용했습니다.
- Masked Language Modeling (MLM)
BERT에서 많이 사용하는 Mask 모델입니다.
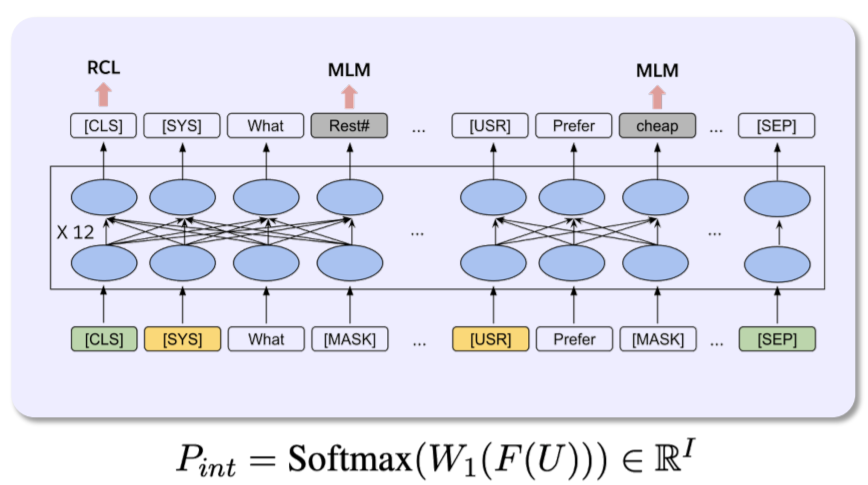
- Response Contrasive Loss (RCL)
뒷 문장이 앞 context에 대한 response인지 판별하는 방법

따라서 이 두 가지 방법으로 TOD-BERT를 훈련시켰을 때 결과는 다음과 같습니다.
TOD-BERT-mlm은 MLM만 사용해 Pretrain 한 모델이며, TOD-BERT-jnt는 MLM + RCL을 사용해 Pretrain한 모델입니다.
BERT에 비해 few-shot & full-data 모두 높은 성능을 보이는 것을 알 수 있습니다.

2) ConvBERT
ConvBERT는 Pretrained Model을 가지고 Target Dataset (Dialogue dataset)을 이용해서 추가로 pretrain (MLM)한 모델을 말합니다.


방법은 두 가지가 있습니다.
1. Pre-training 한 후 Fine-tuning
2. Pre-training과 동시에 Fine-tuning
3) ConvBERT-DG (ConvBERT on DialoGLUE)
DG는 DialoGLUE의 약자로 Dialogue에 특화된 GLUE입니다.

이 DialoGLUE를 ConvBERT에 full-data로 Pre-training (MLM)한 모델을 의미합니다.

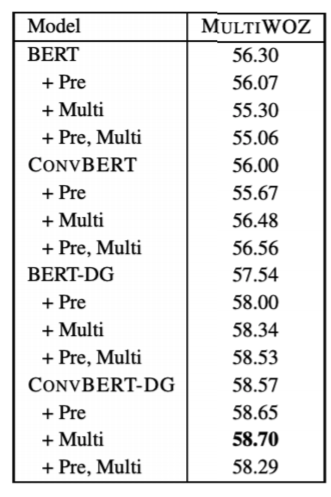
따라서 다음과 같은 실험을 진행할 수 있습니다.
- 4개의 BERT-like models
BERT-base, ConvBERT, BERT-DG, ConvBERT-DG - 4 Settings :
1) Direct Fine-tuning
2) MLM Pre-training with target data before Fine-tuning
3) Multi-tasking : MLM Pre-training with target data during Fine-tuning
4) 2) + 3) - DST Base model : TripPy
결과는 다음과 같습니다.
전반적으로 ConvBERT/task-adaptive training을 따로 적용할 때보다 같이 적용했을 때 더 큰 성능 향상이 있었습니다.
'[P Stage 3] DST > 이론' 카테고리의 다른 글
| [Stage 3 - 이론] DST의 한계점 (0) | 2021.05.11 |
|---|---|
| [Stage 3 - 이론] DST의 Computational Complexity (0) | 2021.05.04 |
| [Stage 3 - 이론] Hybrid Approach (0) | 2021.05.04 |
| [Stage 3 - 이론] Ontology-based DST models (0) | 2021.04.27 |
| [Stage 3 - 이론] Introduction to Task-Oriented Dialogue System (0) | 2021.04.27 |



